
Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Java PDF Library

This article will teach you how to use Java to extract data from a PDF file. Data extraction from PDFs is a typical operation in the IT sector and is frequently necessary for a variety of applications, including reporting, content management, and more.
In this tutorial, we'll show you how to use IronPDF for Java to extract data from a PDF file. Setting up the environment, importing the library, reading the input file, and extracting the needed data are all steps we'll do. You will understand precisely how to extract data from a PDF file using IronPDF for Java at the conclusion of this article.
IronPDF is a software library that provides developers with the ability to generate, edit, and extract data from PDF files within their Java applications. It allows you to create PDFs from HTML, ASPX, images, and more, as well as merge, split, and manipulate existing PDFs. IronPDF also provides the ability to secure PDFs with password protection and add digital signatures, among other features.
IronPDF for Java is developed and maintained by Iron Software. One of its top-rated features is to extract text and data from PDF files as well as from HTML and URLs.
To use IronPDF to extract data from PDF files, you must meet the following prerequisites:
Installing IronPDF for Java is easy and uncomplicated, provided all the requirements are met. This guide will use JetBrains' IntelliJ IDEA to demonstrate the installation and run sample code.
Here's what to do:
Open IntelliJ IDEA: Launch JetBrains IntelliJ IDEA on your system.
Create a Maven Project: In IntelliJ IDEA, create a new Maven project. This will provide a suitable environment for the installation of IronPDF for Java.
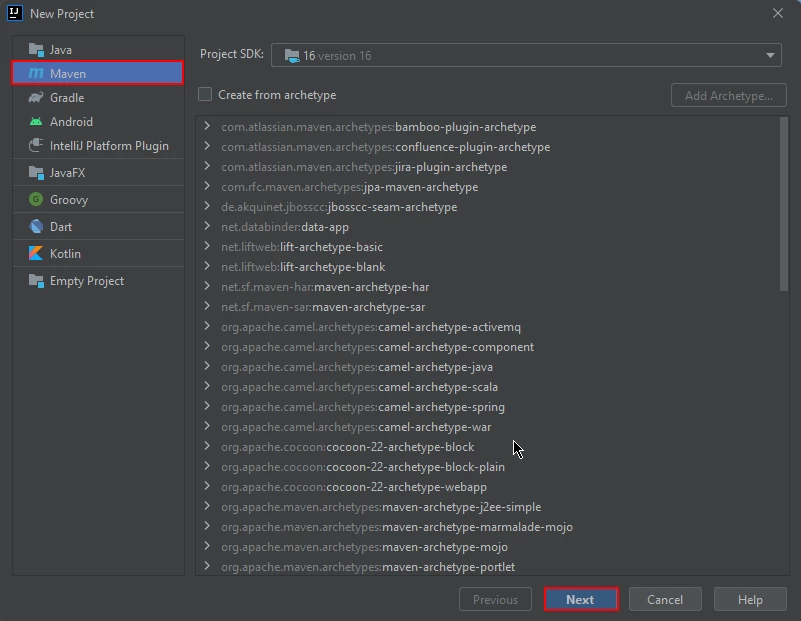
Create an New IntelliJ Maven Project
A new window will appear. Enter the name of the project and click on Finish.
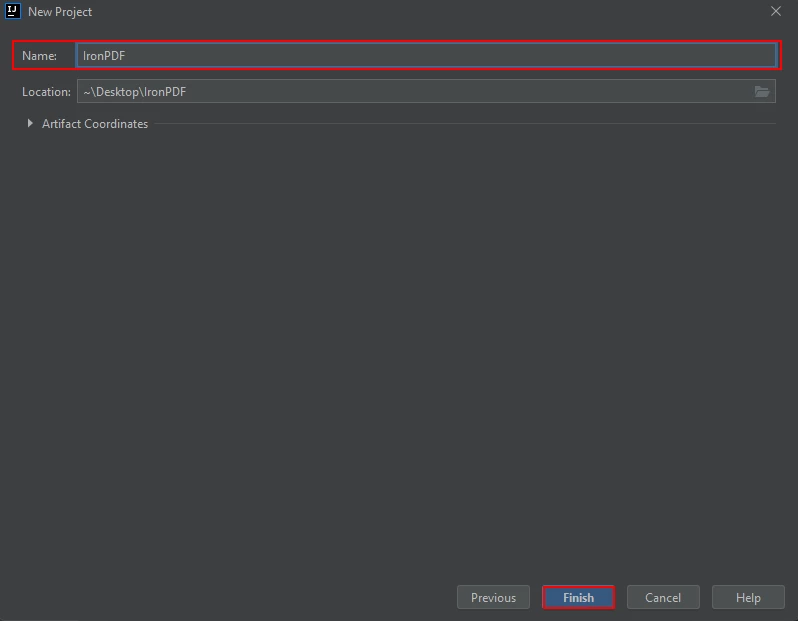
Give your new Maven Project a suitable name, and click Finish to complete the New Project Wizard.
A new project with a pom.xml will open once you click Finish. This will be used to add IronPDF Java Maven dependencies.
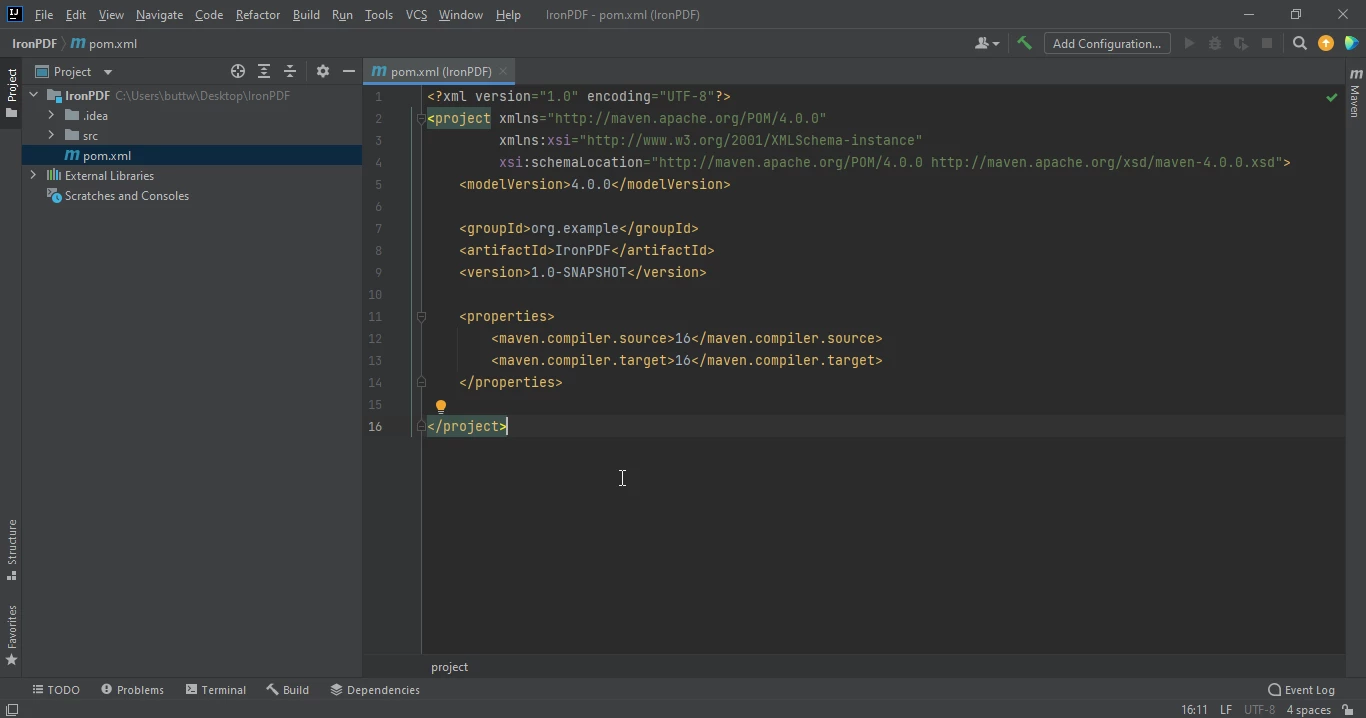
The pom.xml file
Add the following dependencies in the pom.xml file or you can download the JAR file from the following link.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>com.ironsoftware</artifactId>
<version>2024.3.1</version>
</dependency>Once you placed the dependencies in the pom.xml file, a small icon will appear in the right top corner of the file.
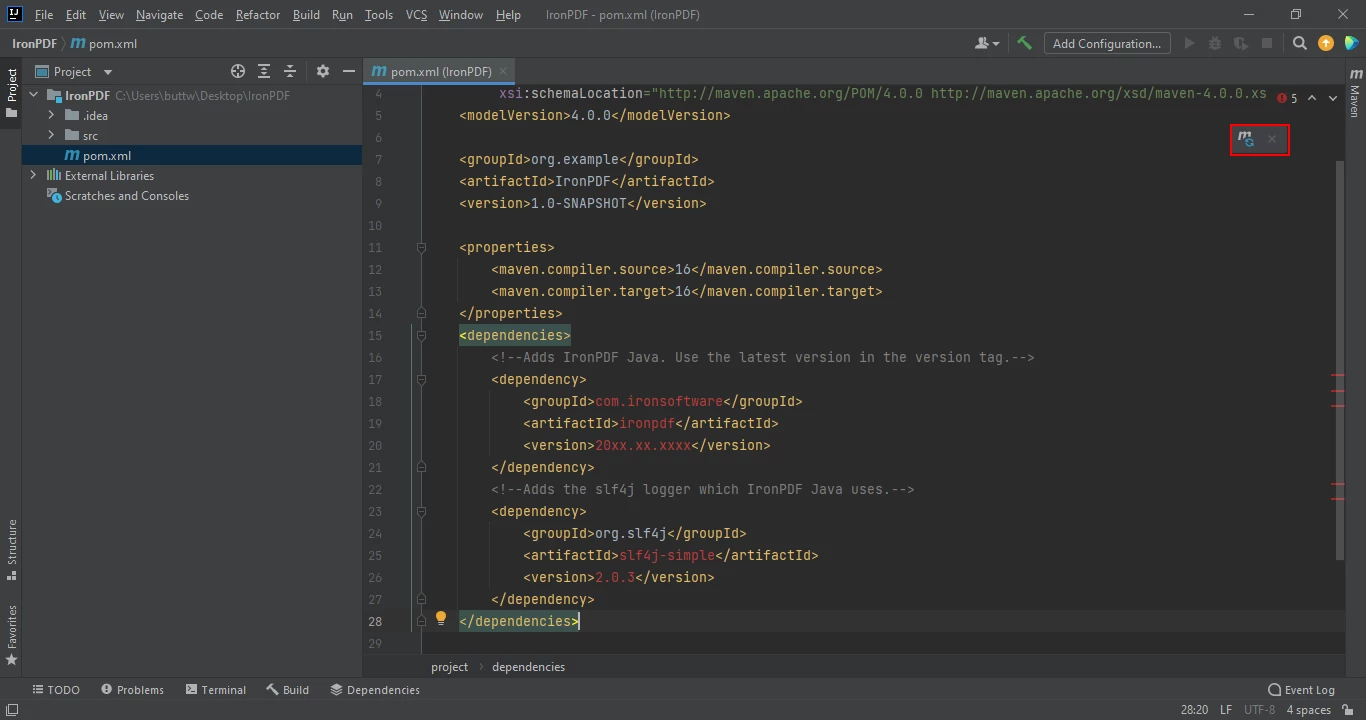
Click on the Floating Maven Icon shown above to install the new Maven dependencies automatically.
Install IronPDF for Java's Maven dependencies by clicking this button. Depending on the speed of your internet connection, this should just take a few minutes.
IronPDF is a .NET library for creating, editing and extracting data from PDF documents. It allows developers to extract text, images, and other data from PDFs using C# or VB.NET code. With IronPDF, you can also manipulate PDFs, such as converting HTML to PDF or adding watermarks or annotations to existing PDFs.
Using IronPDF for Java, you can easily extract text data from PDF documents. Below is the example code for extracting data from a PDF file.
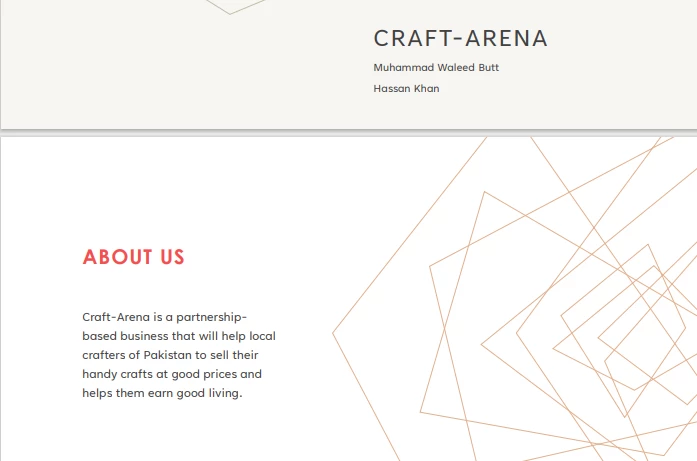
The working PDF from which we will be extracting content in this tutorial.
import com.ironsoftware.ironpdf.License;
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class main {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("bussiness plan.pdf"));
String text = pdf.extractAllText();
System.out.println("Text extracted from the PDF: " + text);
}
}The source code produces the output given below:
> Text extracted from the PDF:
>
> CRAFT-ARENA
>
> Muhammad Waleed Butt
>
> Hassan Khan
>
> ABOUT US
>
> Craft-Arena is a partnershipbased business that will help local crafters of Pakistan to sell their handy crafts at good prices and helps them earn good living.IronPDF for Java converts the URL to PDF in runtime and extracts text from it. In this example, we will see the source code to extract text from URLs.
import com.ironsoftware.ironpdf.License;
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class main {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// new PDFparser
String text = pdf.extractAllText();
System.out.println("Text extracted from the URLs: " + text);
}
}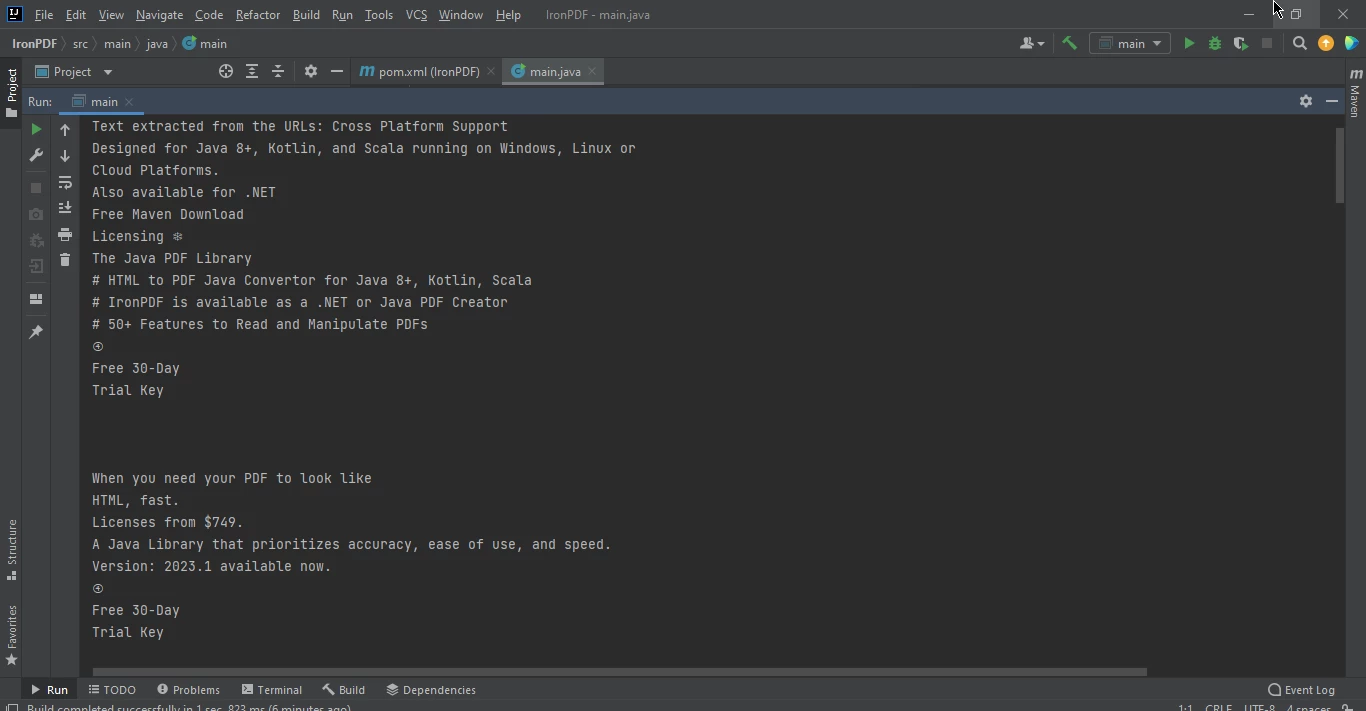
The text extracted from a webpage. This approach combined the renderUrlAsPdf method with the extractAllText method.
To extract table data from a PDF using IronPDF for Java is very simple; all you need is a PDF containing a table, and to run the below code.
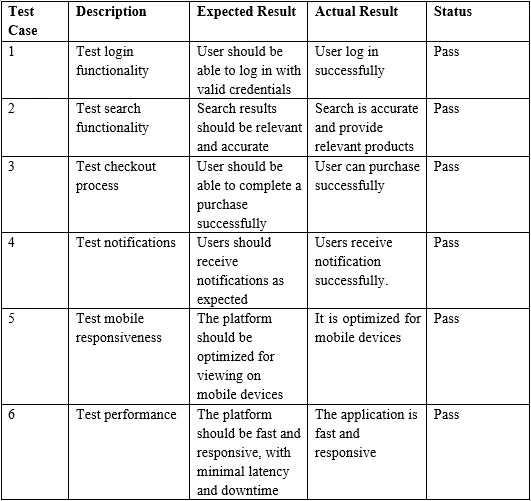
A sample PDF containing a table
import com.ironsoftware.ironpdf.License;
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class main {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
String text = pdf.extractAllText();
System.out.print("Text extracted from the Marked tables: " + text);
}
}> Test Case Description Expected Result Actual Result Status
>
> 1 Test login functionality User should be able to log in with valid credentials
>
> User log in successfully Pass
>
> 2 Test search functionality Search results should be relevant and accurate
>
> Search is accurate and provide relevant products Pass
>
> 3 Test checkout process User should be able to complete a purchase successfully
>
> User can purchase successfully PassIn conclusion, this tutorial has demonstrated how to extract data, specifically tabular data from a PDF file, using IronPDF for Java.
For more information, please refer to the Extract Text on the IronPDF website.
IronPDF is a library with a commercial license, starting at $749. However, you can evaluate it in production with a free trial.

30-day Trial Key instantly.
30-day Trial Key instantly.
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.3.1</version>
</dependency>
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
9 .NET API products for your office documents
Thank you!
Your license key has been delivered to the email provided. Contact us

24-Hour Upgrade Offer:
Save 50% on a
Professional Upgrade
Go Professional to cover 10 developers
and unlimited projects.
hours
:
minutes
:
seconds

Professional
$600 USD
$299 USD
5 .NET Products for the Price of 2
Total Suite Value:
$7,192 USD