
Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Java PDF Library

Reading a PDF document in Java can be an integral part of any project, ranging from business applications to data analytics. PDF documents offer advantages such as file portability and fast load times that make them particularly useful in many system settings for content parser.
With the IronPDF library, it has become easier than ever before to integrate PDF processing capabilities in your Java projects.
fromFile methodextractAllText method to read text from the opened fileIronPDF Java PDF library is the perfect solution for Software Developers who need to produce high-quality, capture-ready PDFs quickly from HTML. The library also provides powerful document manipulation tools that enable dynamic control over page layout, content, and formatting.
Let's see how we can read a PDF file stored at a path in a Java program using IronPDF library.
First, we had to install IronPDF in our Maven project.
Here are the steps to install IronPDF in a Maven project:
In the pom.xml file, add the IronPDF library dependency in the dependencies section.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>com.ironsoftware</artifactId>
<version>2024.3.1</version>
</dependency>Once the installation is complete, you should be able to import and use the IronPDF's following classes and Apache tika parsers in your project.
Here is the code which you can use to read the new file with or without tabular boundaries using the IronPDF library.
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
public class test{
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("C:\\sample.pdf"));
String text = pdf.extractAllText();
System.out.println(text);
}
}In this program, the PdfDocument class from the IronPDF library is used to read the contents of a PDF file. The first line of the program imports the required classes from the IronPDF library. The second line imports the IOException class from the Java standard library.
The program defines a public class named "test". Inside the class, there is a public static method named main that takes an array of strings as an argument.
The main method uses the fromFile method of the PdfDocument class to load a PDF file located at "C:\sample.pdf". This method returns a PdfDocument object that represents the PDF file.
Once the PDF file is loaded, the program calls the extractAllText method of the PdfDocument class to extract all the text from the PDF file. This method returns a String that contains all the text in the PDF file.
The extracted text is then stored in a String variable named "text". This variable can be used to process or display the contents of the PDF file.
Finally, the program prints the extracted text to the console using the System.out.println method.
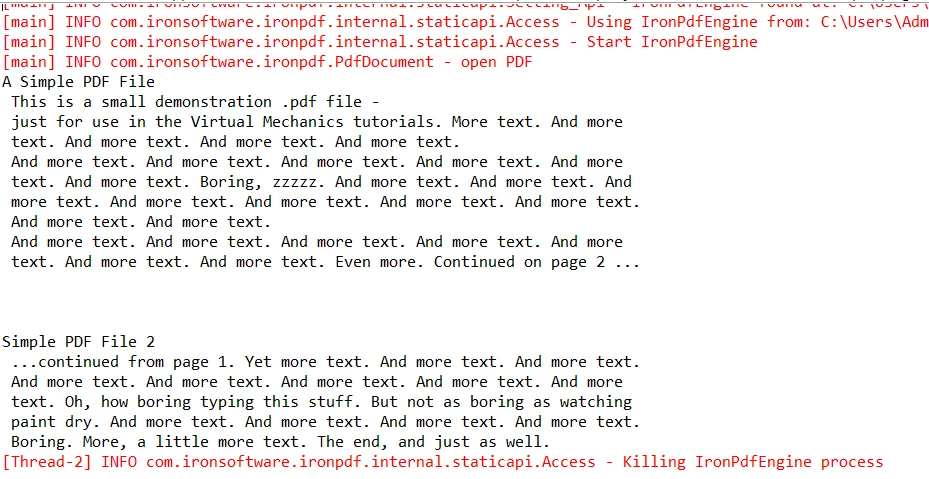
The results of executing the code shown above
IronPDF is a great solution for reading PDF files within the same path or multiple different paths in Java, as it offers high performance and many features that make developing PDFs easily. Its syntax is straightforward and user-friendly. Its API allows developers to quickly craft the code that they need for their projects.
IronPDF's licensing plans start from just $749, making it accessible to extract content for those on a budget. Overall, IronPDF provides an excellent option for any Java developer looking to work with PDFs in their Java applications programming.

30-day Trial Key instantly.
30-day Trial Key instantly.
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.3.1</version>
</dependency>
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
9 .NET API products for your office documents
Thank you!
Your license key has been delivered to the email provided. Contact us

24-Hour Upgrade Offer:
Save 50% on a
Professional Upgrade
Go Professional to cover 10 developers
and unlimited projects.
hours
:
minutes
:
seconds

Professional
$600 USD
$299 USD
5 .NET Products for the Price of 2
Total Suite Value:
$7,192 USD