
Dask Python(開発者向けのしくみ)
Pythonはデータ分析と機械学習における強力な言語ですが、大規模なデータセットを扱うことはデータ分析において挑戦となることがあります。 ここでDaskが登場します。 Daskはオープンソースのライブラリで、高度な並列化を提供し、単一のマシンのメモリ容量を超える大規模なデータセットで効率的な計算を行えるようにします。この記事では、Daskライブラリの基本的な使い方と、IronPDFという非常に興味深いPDF生成ライブラリを使用したPDFドキュメントの生成について見ていきます。
なぜDaskを使うのか?
Daskは、Pythonコードを1台のラップトップから大規模クラスターにスケールするように設計されています。 これは、NumPy、pandas、scikit-learnなどの人気 for Pythonライブラリとシームレスに統合され、コードの大幅な変更なしに並列実行を可能にします。
Daskの主な特徴
1.並列コンピューティング: Dask を使用すると、複数のタスクを同時に実行できるため、計算速度が大幅に向上します。 2.スケーラビリティ:メモリよりも大きなデータセットを小さなチャンクに分割し、並列処理することで処理できます。 3.互換性:既存の Python ライブラリと適切に連携し、現在のワークフローに簡単に統合できます。 4.柔軟性: Dask DataFrame、タスク グラフ、Dask Array、Dask Cluster、Dask Bag などの高レベル コレクションを提供します。これらはそれぞれ、pandas、NumPy、リストを模倣しています。
Daskの入門
インストール
Daskのインストールにはpipを使用できます:
pip install dask[complete]pip install dask[complete]基本的な使い方
ここでは、Daskがどのように計算を並列化するかを示す簡単な例を紹介します:
import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
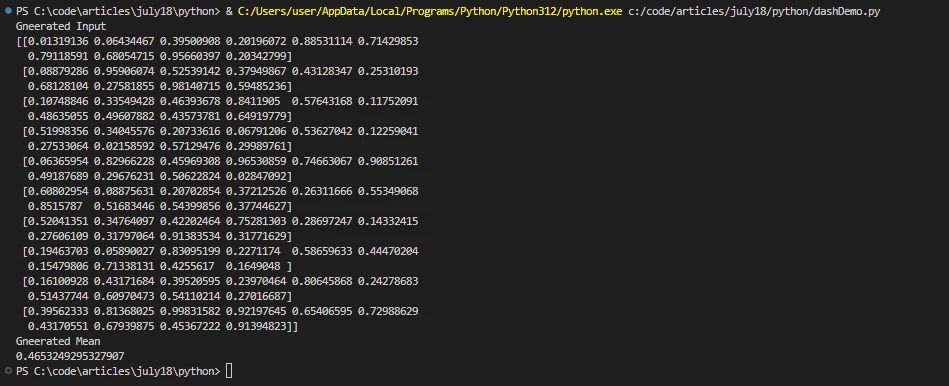
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)この例では、Daskが大きな配列を作成しそれを小さなチャンクに分割します。 compute() メソッドは並列計算をトリガーし、結果を返します。 タスクグラフは、Python Daskで並列計算を実現するために内部で使用されます。
出力
Dask DataFrame
Dask DataFrameは、pandas DataFrameに似ていますが、メモリを超えるデータセットを扱うために設計されています。 こちらが例です:
import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
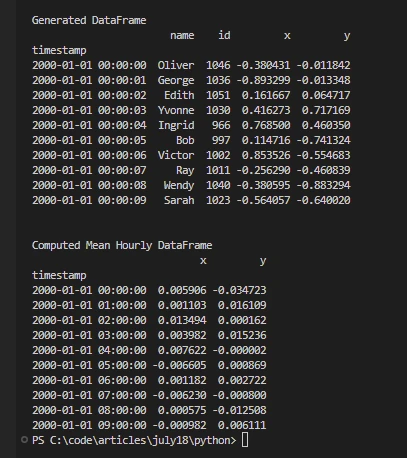
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))このコードは、Daskの時系列データの処理、合成データセットの生成、および複数 for Pythonプロセス、分散スケジューラ、および複数コアの計算リソースを使用して、効率的に時間単位の平均値を計算する能力を示しています。
出力
ベストプラクティス
1.小さく始める:スケールアップする前に、Dask がどのように機能するかを理解するために、小さなデータセットから始めます。 2.ダッシュボードを使用する: Dask は、計算の進行状況とパフォーマンスを監視するためのダッシュボードを提供します。 3.チャンク サイズの最適化:メモリ使用量と計算速度のバランスをとるために適切なチャンク サイズを選択します。
IronPDFの紹介
IronPDFは、HTML、CSS、画像、およびJavaScriptを使用してPDFドキュメントを作成、編集、署名するために設計された強力なPythonライブラリです。 これは、メモリ使用量を最小限に抑えながら、パフォーマンス効率に重点を置いています。 主な機能は以下のとおりです:
- HTML から PDF への変換: Chrome の PDF レンダリング機能を活用して、HTML ファイル、文字列、URL を PDF ドキュメントに簡単に変換できます。 *クロスプラットフォーム サポート:* Windows、Mac、Linux、およびさまざまなクラウド プラットフォーム上の Python 3+ でシームレスに動作します。 .NET、Java、Python、およびNode.js環境とも互換性があります。 編集と署名: PDF プロパティをカスタマイズし、パスワードや権限などのセキュリティ対策を適用し、デジタル署名をシームレスに追加します。 ページ テンプレートと設定:ヘッダー、フッター、ページ番号、調整可能な余白、カスタム用紙サイズ、レスポンシブ デザインを使用して PDF レイアウトをカスタマイズします。 標準準拠:** PDF/A や PDF/UA などの PDF 標準に厳密に準拠し、UTF-8 文字エンコードの互換性を確保します。 画像、CSSスタイルシート、フォントなどのアセットの効率的な管理もサポートされています。
インストール
pip install ironpdf
pip install daskpip install ironpdf
pip install daskIronPDFとDaskを使用してPDFドキュメントを生成する
前提条件
- Visual Studio Codeがインストールされていることを確認してください。
- Pythonバージョン3がインストールされています。
まず、スクリプトを追加するPythonファイルを作成してください。
Visual Studio Code を開いてファイルを作成し、daskDemo.py。
必要なライブラリをインストール:
pip install dask
pip install ironpdfpip install dask
pip install ironpdfその後、以下 for Pythonコードを追加して、IronPDFとDask Pythonパッケージの使用法を示します:
import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
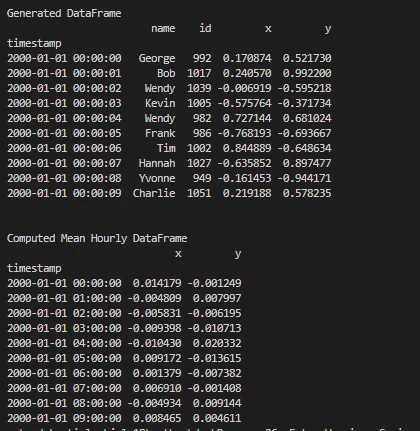
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("DemoIronPDF-Dask.pdf")import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("DemoIronPDF-Dask.pdf")コードの説明
このコードスニペットは、データ処理のためにDaskを、PDF生成のためにIronPDFを統合します。 次を示します:
- Dask統合:
dask.datasets.timeseries()を使用して、合成タイムシリーズDataFrame (df) を生成します。 最初の10行を出力し (df.head(10))、列 "x" と "y" を基に時間単位のDataFrame (dfmean) の平均を計算します。 - IronPDFの使用:
License.LicenseKeyを使用してIronPDFのライセンスキーを設定します。 生成および計算されたDataFrameからのヘッダーとデータを含むHTML文字列 (content) を作成し、このHTMLコンテンツをChromePdfRenderer()を使用してPDF (pdf) にレンダリングし、最終的に "DemoIronPDF-Dask.pdf" としてPDFを保存します。
このコードは、IronPDFのHTMLコンテンツをPDFドキュメントに変換する機能とDaskの大規模データ操作の能力を組み合わせています。
出力

IronPDFライセンス
IronPDFライセンスキーは、購入前にその豊富な機能を確認することができます。
スクリプトを使用する前にライセンスキーを配置しIronPDFパッケージを使用します。
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"結論
Daskは、Pythonでのデータ処理能力を大幅に向上させることができる多用途のツールです。 並列計算と分散計算を可能にすることで、大規模なデータセットを効率的に処理し、既存 for Pythonエコシステムにシームレスに統合することができます。 IronPDFは、HTML、CSS、画像、およびJavaScriptを使用してPDFドキュメントを作成および操作するための強力なPythonライブラリです。 HTMLからPDFへの変換、PDF編集、デジタル署名、クロスプラットフォームサポートなどの機能を提供し、Pythonアプリケーションのさまざまなドキュメント生成や管理タスクに適しています。
両者のライブラリを組み合わせることで、データサイエンティストは高度なデータ分析と科学操作を実行し、IronPDFを使用してその出力結果を標準のPDF形式で保存できます。
















