
HTTPX Python(開発者向け:しくみガイド)
HTTPX は、同期および非同期 API を特徴とする、現代的で完全に機能を備えた Python 向けの HTTP クライアントです。このライブラリは HTTP リクエストの処理において高い効率を提供します。 このライブラリのいくつかの機能は、Requestsのような従来のライブラリを拡張します。 したがって、HTTP/2、接続プーリング、およびクッキーマネージメントをサポートしているため、より強力です。
IronPDFと統合されたHTTPXは、包括的な.NETライブラリであり、すべてのPDFドキュメントの作成および編集が可能であり、Web APIやウェブサイトからデータを取得し、この取得したデータを長大で美しく整形されたPDFレポートに変換することができます。 HTML、画像、シンプルなテキストからPDFを生成するIronPDFの機能により、プロフェッショナルで魅力的な文書を作成できます。また、ヘッダー、フッター、透かしなどの高度な機能をサポートしています。 データの取得からレポートの生成まで統合されており、洗練された形でインサイトを伝えるための効率的な方法を提供します。
Httpx Pythonとは何ですか?
HTTPXは、人気のあるRequestsライブラリのクールな使い方をいくつか導入し、これを同期および非同期APIサポートと組み合わせたPython向けのモダンかつ次世代のHTTPクライアントです。 HTTP/2のサポート、接続プーリング、さらには自動クッキーマネジメントのようなさまざまな高度な機能を備えた複雑なHTTPタスクを解決しようとしています。 HTTPXは、開発者が複数の異なるHTTPリクエストを同時に送信できるようにし、ウェブベースの操作が主な期待機能であるケースでアプリケーションのパフォーマンスを向上させます。
Requestsライブラリとの優れた相互運用性を提供し、HTTPクライアントをアップグレードしたい開発者にとって、より複雑な機能にアクセスするための簡単なアップグレードパスを提供します。 HTTPXはモダンなPython開発向けの柔軟なツールです。 それは、シンプルなHTTPクエリからより複雑でパフォーマンスクリティカルなウェブインタラクションまでのタスクによく適しています。 HTTPXは、ソックスプロキシサポート接続を備えた同期および非同期リクエストの両方を処理できます。
Httpx Pythonの機能
PythonのHTTPXは、HTTPリクエストの処理を拡張および強化する最も価値のある機能を提供します。 以下は、その主要な機能の一部です:
同期および非同期API:
同期および非同期リクエスト処理の両方をサポートしています。 開発者は、ニーズに基づいてアプリケーション内で利用可能なオプションのいずれかを適用できます。
HTTP/2のサポート:
このフレームワークには、HTTP/2プロトコルのネイティブサポートがあり、対応するサーバーとの通信をより高速かつ効率的に行えます。
接続プーリング:
スマートなHTTP接続: 設定済みの接続や接続プーリングセッションを再利用し、多くのリクエストの遅延を減らし速度を向上させます。
自動コンテンツデコーディング:
通常、gzipでエンコードされた圧縮レスポンスを、簡単に処理するため自動デコードします。これにより帯域幅の削減が可能です。
タイムアウトとリトライ:
リクエストのタイムアウトを過ぎた際の非ブロッキングリクエストを保証するためのタイムアウトリクエスト設定を定義します。トランジェントな障害に対処するための追加のリトライメカニズムがあります。
WebSocketのサポート:
WebSocket接続をサポートしており、単一の長期間接続を介してクライアントとサーバー間の双方向の通信を可能にします。
プロキシサポート:
HTTPプロキシをネイティブにサポートしています。 これは、プライバシーやネットワーク管理のために中間サーバーを介してリクエストを行えるようにします。
クッキー処理:
ライブラリはクッキーを処理し、リクエスト間のセッション状態を追跡します。
クライアント証明書:
クライアント側の証明書がサポートされており、相互TLS認証を使用するサーバーとの通信を保護します。
ミドルウェアとフック:
ミドルウェアとフックによってリクエストおよびレスポンスの処理をカスタマイズできます。 これにより開発者は、要求に応じてHTTPXの機能を拡張するための優れた拡張性を得られます。 Requests互換性: RequestsのAPIを利用するように設計されており、RequestsからHTTPXプロジェクトに移行して多くの新しい優れた機能と改善を提供します。
Httpx Pythonの作成と設定
まず、ライブラリをインストールし、PythonでHTTPXを設定する環境をセットアップする必要があります。 HTTPXプロジェクトは、HTTPコアと非同期ライブラリアウト検出を依存関係としており、ただしHTTPXプロジェクトをインストールする際に直接インストールされる必要があります。 また、HTTPXのバリエーションとして、リッチなターミナルサポートと共に提供されるコマンドラインクライアントサポートがあります。 しかしこの記事では、HTTPX Pythonに厳密に焦点を当てます。 以下のガイドは、簡単なHTTP GETリクエストの例を示しています。より包括的なAPIリファレンスについては、HTTPXのドキュメントをここでご覧ください。
HTTPXのインストール
まず、HTTPXがインストールされていることを確認してください。 コマンドラインクライアントを使用してインストールできます:
pip install httpxpip install httpxHTTPXのインポートと基本的なリクエストの作成
インストール後、HTTPXをインポートして次のように簡単なHTTP GETリクエストを発行できます:
import httpx
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
# Create a client instance to manage HTTP requests
response = httpx.get(url)
# Print response HTTP status codes and content
print(f"Status Code: {response.status_code}")
# Print Unicode Response Bodies
print(f"Response Content: {response.text}")import httpx
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
# Create a client instance to manage HTTP requests
response = httpx.get(url)
# Print response HTTP status codes and content
print(f"Status Code: {response.status_code}")
# Print Unicode Response Bodies
print(f"Response Content: {response.text}")- 非同期コンテキストマネージャ内でHTTPクライアントを開くfetch_data関数が、指定されたURLにGETリクエストを行います。
httpx.get(url)が返すHTTP応答オブジェクトを格納します。
HTTPXの高度な機能の設定
HTTPXの高度な機能は、プロキシ、ヘッダー、タイムアウトの処理など、他の広範な設定をサポートしています。 以下は、HTTPXを多くのオプションで設定する方法です:
import httpx
def fetch_data_with_config(url):
# Create a client with a timeout and custom headers
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Print response status code and content
print(f"Status Code: {response.status_code}")
print(f"Response Content: {response.json()}")import httpx
def fetch_data_with_config(url):
# Create a client with a timeout and custom headers
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Print response status code and content
print(f"Status Code: {response.status_code}")
print(f"Response Content: {response.json()}")-タイムアウト: HTTP リクエストのタイムアウトを 30 秒に設定します。 これは、リクエストが無限にブロックされるのを防ぐためです。
User-Agentヘッダーを追加します。- response.json() - レスポンスにJSONデータが含まれていることを前提に、レスポンスコンテンツをJSONとして解析します。

開始方法
PythonでHTTPXとIronPDFを使ってPDFを生成します。 まず、データを取得するためにHTTPXを設定し、取得したデータからIronPDFがPDFレポートを作成します。 その方法を詳細に説明します:
IronPDFとは何ですか?
強力で堅牢なPythonライブラリIronPDFは、PDFの生成、編集、読み取りを可能にします。 プログラマーが、既存のPDFを編集したりHTMLファイルをPDFに変換したりと、多くのプログラムベースの操作をPDFに対して行うことができます。 IronPDFは、高品質のレポートをPDF形式で生成することを簡単かつ柔軟にします。 これにより、動的にPDFを作成および処理するアプリケーションにとって実用的です。
HTMLからPDFへの変換
IronPDFは、あらゆるHTMLデータを年齢に関係なくPDFドキュメントに変換できます。 これにより、HTML5、CSS3、およびJavaScriptの現代的な機能を全面的に活用したウェブコンテンツから、美しい芸術的なPDFを作成することが可能です。
PDFの作成と編集
プログラム言語を通じて、テキスト、画像、表、その他のコンテンツを含む新しいPDFドキュメントを生成することが可能です。 IronPDFはまた、既存のPDFドキュメントを開いて変更し、追加のカスタマイズを行うことができます。 PDFドキュメントに含まれるコンテンツを随時追加、変更、削除することができます。
複雑なデザインとスタイリング
これはCSSによって達成され、さまざまなフォント、色、およびその他のデザイン要素で複雑なレイアウトを処理することができます。 さらに、JavaScriptを内部で使用することでPDF内の動的コンテンツの処理を確実に行うことができ、HTMLコンテンツの表示を容易にします。
IronPDFのインストール
IronPDFはpipを使ってインストールできます。インストールコマンドは以下の通りです:
pip install ironpdfpip install ironpdfhttpxとIronPDF for Pythonを組み合わせる
APIやWebサイトからデータを取得するためにHTTPXを使用します。次の例は、JSON形式の偽のAPIからデータを取得する方法を示しています。
import httpx
from ironpdf import ChromePdfRenderer
# Set your IronPDF license key
License.LicenseKey = ""
def fetch_data_with_config(url):
# Create an HTTPX client with added configurations
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Create a PDF document renderer
iron_pdf = ChromePdfRenderer()
# Create HTML content from fetched data
html_content = f"""
<html>
<head><title>Data Report</title></head>
<body>
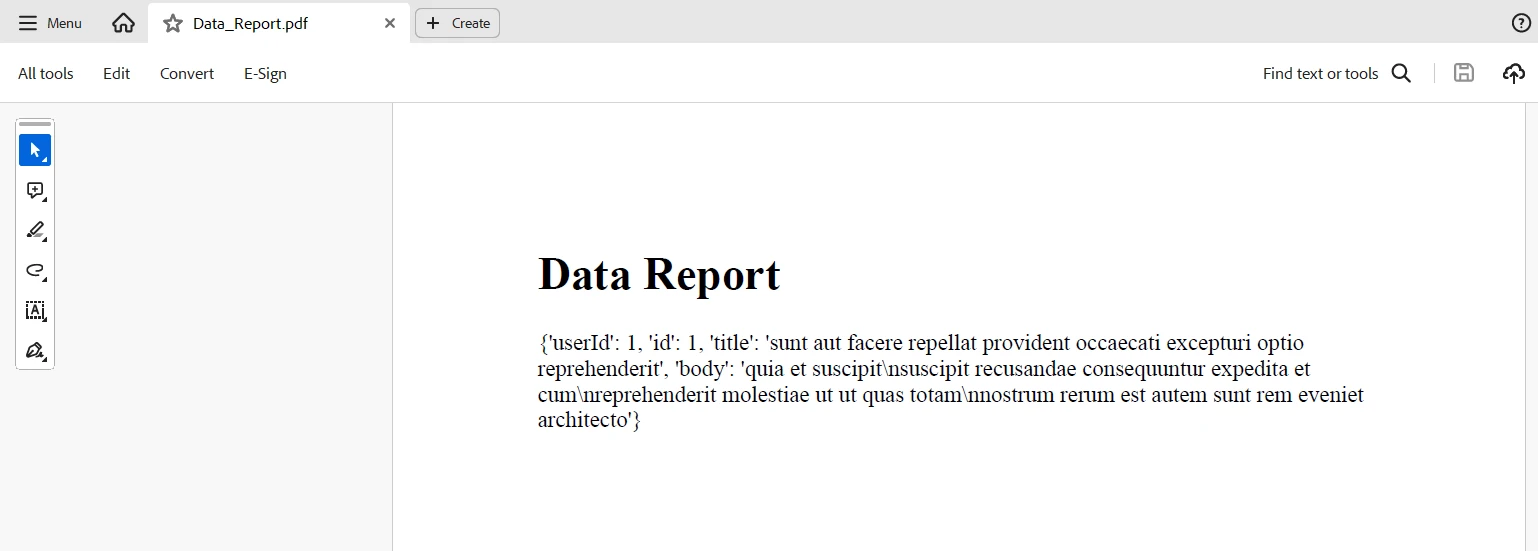
<h1>Data Report</h1>
<p>{response.json()}</p>
</body>
</html>"""
# Render the HTML content as a PDF
pdf = iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("Data_Report.pdf")
print("PDF document generated successfully.")import httpx
from ironpdf import ChromePdfRenderer
# Set your IronPDF license key
License.LicenseKey = ""
def fetch_data_with_config(url):
# Create an HTTPX client with added configurations
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Create a PDF document renderer
iron_pdf = ChromePdfRenderer()
# Create HTML content from fetched data
html_content = f"""
<html>
<head><title>Data Report</title></head>
<body>
<h1>Data Report</h1>
<p>{response.json()}</p>
</body>
</html>"""
# Render the HTML content as a PDF
pdf = iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("Data_Report.pdf")
print("PDF document generated successfully.")- これは、HTTPXを使用してWeb APIやWebサイトからデータを効率的に同期的に取得するように設計されています。 同期および非同期の操作の両方に備えており、異なるHTTPリクエストを同時に処理する実用的なライブラリです。 例として、JSONデータを返すモックAPIエンドポイントを叩くことが挙げられます。
- IronPDFはPythonを介して使用されます; 上記で取得したデータでPDFレポートを生成するために.NETエンジンを利用します。 IronPDFはHTMLコンテンツからPDFを生成し、このデータを構造的なドキュメントに変換することができます。
- IronPDFの統合: Pythonを使用してIronPDFと対話できます。 これは動的に生成されたHTMLコンテンツ (
pdf)を開発することになります。 HTTPXを通じてデータが取得されます。 このHTMLコンテンツは動的に取得されたデータに基づいて作成されます; したがって、パーソナライズされたリアルタイムのレポートを取得できます。
結論
このHTTPXとIronPDFの統合により、Pythonにデータ取得とプロフェッショナルなPDF生成という2つの力が組み合わされます。 HTTPXは、HTTPリクエストを扱うための非同期および同期のスタイルをサポートしているため、Web APIやWebサイトからデータを取得するのに最適です。 一方、IronPDFは取得したデータから、Python .NETのインターオペラビリティを通じて、磨かれたプロフェッショナルなPDFレポートを生成することを容易にし、データインサイトの可視化と伝達を装飾します。
最も簡単なデータ取得からレポート作成までのすべてを軽減し、さまざまな個別データソースおよびフォーマットの処理において柔軟性を提供します。 開発者がプレゼンテーションやドキュメント用に、またはすべてのデータ分析結果をアーカイブするために、詳細なPDFを生成することができるようにします。 これらのユーティリティとPythonアプリケーションは、未加工のデータをプロフェッショナルに形式指定されたレポートに変換し、生産性と意思決定を選択したドメイン内で保証します。
IronPDFとIron Software製品を統合して、クライアントとそのユーザーにリッチで高度なソフトウェアソリューションを提供します。 これにより、プロジェクトの運営と手順が簡素化されます。
すべての基本機能に加えて、IronPDFには完全なドキュメント、活発なコミュニティ、および頻繁な更新があります。 この情報に基づいて、Iron Softwareはモダンなソフトウェア開発プロジェクトにとって信頼できるパートナーです。 開発者はIronPDFの無料試用版を試し、すべての機能を確認できます。 その後、ライセンスは$799から開始します。
















