LoopBack node js (jak to działa dla programistów)
Kompletne rozwiązanie do dynamicznego generowania plików PDF w aplikacjach opartych na frameworku LoopBack zapewnia płynna integracja IronPDF, biblioteki do programowego tworzenia dokumentów PDF, z LoopBack, frameworkiem Node.js do tworzenia interfejsów API. Dzięki funkcjom takim jak tworzenie modeli, walidacja źródeł danych, metody zdalne i kontrola dostępu, framework LoopBack ułatwia tworzenie API i aplikacji internetowych, a IronPDF wzbogaca go o bardziej zaawansowane możliwości tworzenia plików PDF.
Dzięki tej integracji programiści mogą tworzyć pliki PDF w locie, pobierając dane z wielu źródeł, w tym zewnętrznych interfejsów API i baz danych. Umożliwia to tworzenie niestandardowych rekordów lub obiektów domeny biznesowej w celu spełnienia wymagań projektu, takich jak faktury, certyfikaty, raporty i inne. Ponieważ LoopBack działa asynchronicznie, uzupełnia funkcje IronPDF, umożliwiając sprawne generowanie plików PDF bez zakłócania pętli zdarzeń, co gwarantuje responsywność i optymalną wydajność.
Aby rozpocząć pracę z LoopBack i IronPDF, utwórz nowy projekt za pomocą narzędzia CLI LoopBack i zainstaluj IronPDF jako zależność za pomocą npm. Wykorzystanie oprogramowania pośredniczącego LoopBack i możliwości metod zdalnych do natychmiastowego tworzenia plików PDF w odpowiedzi na żądania klientów ułatwia integrację. Podsumowując, ta integracja daje programistom możliwość efektywnego radzenia sobie z różnymi wymaganiami dotyczącymi generowania dokumentów w aplikacjach LoopBack.
Czym jest LoopBack Node.js?
Potężny framework Node.js o nazwie LoopBack został stworzony, aby ułatwić proces tworzenia interfejsów API i łączenia ich z różnymi źródłami danych. Dzięki LoopBack, produktowi firmy StrongLoop, programiści mogą z łatwością projektować skalowalne i elastyczne aplikacje. Zasadniczo LoopBack jest zbudowany w oparciu o framework Express i opiera się na metodologii programowania opartej na modelach, która pozwala programistom tworzyć modele danych symbolizujące domenę ich aplikacji. Bazy danych relacyjnych, takie jak MySQL i PostgreSQL, bazy danych NoSQL, takie jak MongoDB, a także zewnętrzne interfejsy API REST i usługi SOAP można łatwo zintegrować z tymi modelami.
LoopBack wyróżnia się tym, że usprawnia proces tworzenia API poprzez automatyczne generowanie punktów końcowych RESTful na podstawie dostarczonych modeli. Ponadto LoopBack oferuje zintegrowaną obsługę walidacji, uprawnień i uwierzytelniania, umożliwiając programistom zabezpieczenie swoich interfejsów API i zagwarantowanie integralności danych. Ponieważ architektura oprogramowania pośredniczącego LoopBack opiera się na Express.js, jest ona rozszerzalna i elastyczna, umożliwiając programistom pracę z istniejącym oprogramowaniem pośredniczącym lub tworzenie oprogramowania dostosowanego do indywidualnych potrzeb.
Niezależnie od tego, czy tworzysz proste API REST, czy zaawansowaną architekturę mikrousług, LoopBack oferuje funkcje i narzędzia niezbędne do przyspieszenia rozwoju oraz tworzenia niezawodnych, skalowalnych rozwiązań. Ze względu na obszerną dokumentację i prężną społeczność programiści często wybierają je podczas tworzenia najnowocześniejszych aplikacji internetowych i mobilnych.

Funkcje LoopBack
- Architektura oparta na modelach: Umożliwiając programistom definiowanie modeli danych poprzez podejście oparte na schematach, LoopBack wspiera programowanie oparte na modelach. Różnorodne źródła danych, w tym bazy danych, interfejsy API REST i usługi SOAP, mogą być reprezentowane za pomocą modeli.
- Niezależność od źródła danych: Bazy danych relacyjnych (MySQL, PostgreSQL), bazy danych NoSQL (MongoDB), zewnętrzne interfejsy API REST oraz usługi SOAP to tylko niektóre z wielu źródeł danych obsługiwanych przez LoopBack.
- Automatyczne generowanie REST API: LoopBack wykorzystuje predefiniowane modele do automatycznego tworzenia punktów końcowych RESTful API w API Explorer, co pozwala ograniczyć ilość kodu szablonowego i przyspieszyć proces tworzenia oprogramowania.
- Wbudowana obsługa uwierzytelniania i autoryzacji: LoopBack oferuje wbudowaną obsługę tych funkcji, umożliwiając programistom włączenie kontroli dostępu opartej na rolach (RBAC), uwierzytelniania użytkowników i innych środków bezpieczeństwa do swoich interfejsów API.
- Oprogramowanie pośredniczące i metody zdalne: Aby zmienić zachowanie punktów końcowych API, programiści mogą udostępniać oprogramowanie pośredniczące i metody zdalne przy użyciu LoopBack. Podczas gdy metody zdalne oferują dostosowane funkcje, które można wywoływać zdalnie przez HTTP, funkcje oprogramowania pośredniczącego mogą przechwytywać i modyfikować żądania oraz odpowiedzi.
- Interfejs wiersza poleceń (CLI) dla LoopBack: LoopBack zawiera solidne narzędzie CLI, które ułatwia typowe czynności, takie jak tworzenie modeli i kontrolerów, budowanie nowych projektów oraz przeprowadzanie migracji.
- Integracja z komponentami LoopBack: LoopBack ułatwia korzystanie z komponentów, czyli modułów wielokrotnego użytku, które zapewniają dostarczanie wiadomości e-mail, przechowywanie plików oraz funkcje uwierzytelniania. Dzięki temu programiści nie muszą zaczynać od zera, dodając nowe funkcje do swoich aplikacji.
- LoopBack Explorer: Programiści mogą interaktywnie badać i testować punkty końcowe API za pomocą zintegrowanego narzędzia LoopBack do przeglądania API. Ułatwia to rozwiązywanie problemów i zrozumienie możliwości API.
Utwórz i skonfiguruj LoopBack Node.js JS
Możesz skorzystać z poniższych procedur, aby skonfigurować i zbudować aplikację LoopBack w Node.js:
Zainstaluj LoopBack CLI
Pierwszym krokiem jest zainstalowanie interfejsu wiersza poleceń (CLI) LoopBack, który oferuje zasoby do tworzenia i administrowania aplikacjami LoopBack. Użyj npm, aby zainstalować go globalnie:
npm install -g @loopback/clinpm install -g @loopback/cliUtwórz nową aplikację LoopBack
Aby stworzyć szkielet zupełnie nowej aplikacji LoopBack, użyj CLI. Otwórz katalog, w którym chcesz skompilować swoją aplikację, i uruchom ją tam:
lb4 applb4 appAby podać informacje o swojej aplikacji, takie jak jej nazwa, katalog oraz funkcje, które chcesz włączyć, po prostu postępuj zgodnie z instrukcjami.
Zostaniesz poproszony o podanie następujących informacji:
- Nazwa projektu: Wpisz nazwę swojej aplikacji, na przykład my-loopback-app.
- Opis projektu: Opcjonalnie opisz swoją aplikację.
- Katalog główny projektu: zaakceptuj domyślny lub określ inny katalog.
- Nazwa klasy Application: Przyjmij domyślną nazwę Application.
- Włącz Prettier: Wybierz, czy chcesz włączyć Prettier do formatowania kodu.
- Włącz TSLINT: Wybierz, czy chcesz włączyć TSLint do sprawdzania poprawności kodu.
- Włącz Mocha: Wybierz, czy chcesz włączyć Mocha do uruchamiania testów.
Interfejs CLI wygeneruje strukturę projektu i zainstaluje niezbędne zależności.
Zapoznaj się ze strukturą projektu
Katalog projektu będzie miał następującą strukturę:
my-loopback-app/
├── src/
│ ├── controllers/
│ ├── models/
│ ├── repositories/
│ ├── index.ts
│ ├── application.ts
│ └── ...
├── package.json
├── tsconfig.json
└── ...Zdefiniuj modele
Aby określić strukturę danych, należy ręcznie opracować modele lub skorzystać z interfejsu CLI LoopBack. Modele, które mogą być obsługiwane przez różne struktury danych i źródła, reprezentują elementy w programie. Na przykład, uruchom następujące polecenie, aby wygenerować nowy model o nazwie Product:
lb4 modellb4 modelAby określić atrybuty i powiązania modelu, postępuj zgodnie z instrukcjami.
Utwórz kontroler
Aby obsłużyć żądania tworzenia dokumentów PDF, utwórz nowy kontroler. Aby utworzyć nowy kontroler, użyj następującego polecenia w LoopBack CLI:
lb4 controllerlb4 controllerAby zdefiniować nazwę i powiązany model kontrolera, wystarczy postępować zgodnie z instrukcjami. Załóżmy, że chcemy powiązać nazwę właściwości kontrolera z modelem Report i nazwać go ReportController.
Zdefiniuj źródła danych
Określ, z jakimi źródłami danych będą komunikować się Twoje modele. LoopBack obsługuje wiele baz danych, takich jak MySQL, PostgreSQL, MongoDB i inne. Aby skonfigurować źródła danych, należy zaktualizować plik datasources.json lub użyć interfejsu CLI LoopBack.
Poznaj LoopBack
Skorzystaj z wbudowanego narzędzia API Explorer, dostępnego pod adresem http://localhost:3000/explorer, aby zapoznać się z funkcjami LoopBack. Możesz zapoznać się z punktami końcowymi API i przetestować je właśnie tutaj.
Przykładowy kod kontrolera Ping
import {inject} from '@loopback/core';
import {
Request,
RestBindings,
get,
response,
ResponseObject,
} from '@loopback/rest';
/**
* OpenAPI response for ping()
*/
const PING_RESPONSE: ResponseObject = {
description: 'Ping Response',
content: {
'application/json': {
schema: {
type: 'object',
title: 'PingResponse',
properties: {
greeting: {type: 'string'},
date: {type: 'string'},
url: {type: 'string'},
headers: {
type: 'object',
properties: {
'Content-Type': {type: 'string'},
},
additionalProperties: true,
},
},
},
},
},
};
/**
* A simple controller to bounce back http requests
*/
export class PingController {
constructor(@inject(RestBindings.Http.REQUEST) private req: Request) {}
// Map to `GET /ping`
@get('/ping')
@response(200, PING_RESPONSE)
ping(): object {
// Reply with a greeting, the current time, the url, and request headers
return {
greeting: 'Hello from LoopBack',
date: new Date(),
url: this.req.url,
headers: Object.assign({}, this.req.headers),
};
}
}Wynik działania powyższego kodu.

Pierwsze kroki
Zaczniemy od stworzenia przykładowej aplikacji, która wykorzystuje LoopBack Node.js i IronPDF do tworzenia dokumentu PDF z dynamicznie generowanymi informacjami. Jest to instrukcja krok po kroku zawierająca szczegółowe wyjaśnienia.
Czym jest IronPDF?
Biblioteka aplikacji o nazwie IronPDF została opracowana w celu ułatwienia tworzenia, edycji i zarządzania plikami PDF. Dzięki tej aplikacji programiści mogą wyodrębniać tekst i obrazy z dokumentów HTML, dodawać nagłówki i znaki wodne, łączyć wiele dokumentów PDF oraz wykonywać wiele innych czynności. Dzięki przyjaznemu dla użytkownika interfejsowi API i obszernej dokumentacji IronPDF programiści mogą z łatwością automatycznie tworzyć wysokiej jakości dokumenty PDF. IronPDF oferuje wszystkie funkcje i możliwości niezbędne do usprawnienia przepływu pracy z dokumentami oraz zapewnienia najwyższej jakości obsługi użytkownika w różnych scenariuszach, niezależnie od tego, czy są one wykorzystywane do przygotowywania faktur, raportów czy dokumentacji.
Funkcje IronPDF
- Konwersja HTML do PDF to prosty i szybki proces, który można zastosować do dowolnej treści HTML, w tym CSS i JavaScript.
- Łączenie plików PDF: Aby ułatwić zarządzanie dokumentami, połącz wiele dokumentów PDF w jeden plik PDF.
- Wyodrębnianie tekstu i obrazów: Wyodrębnij tekst i obrazy z plików PDF, aby udostępnić je do dalszej analizy lub przetwarzania danych.
- Znak wodny: Ze względów bezpieczeństwa lub wizerunkowych można dodawać tekstowe lub graficzne znaki wodne do stron PDF.
- Dołącz nagłówek i stopkę: Nagłówki i stopki dokumentów PDF pozwalają na umieszczenie spersonalizowanej wiadomości lub numerów stron.
Zainstaluj IronPDF
Aby włączyć obsługę IronPDF, zainstaluj niezbędne pakiety Node.js za pomocą menedżera pakietów Node.
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdfZintegruj LoopBack z IronPDF for Node.js
Zaimplementuj następującą logikę w utworzonym pliku kontrolera (report.controller.ts lub report.controller.js), aby tworzyć dokumenty PDF przy użyciu IronPDF:
import {inject} from '@loopback/core';
import {Request, RestBindings, get, response} from '@loopback/rest';
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF license key, if needed
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({licenseKey: ''});
/**
* Controller handling PDF generation
*/
export class ReportController {
constructor(@inject(RestBindings.Http.REQUEST) private req: Request) {}
@get('/generate-pdf', {
responses: {
'200': {
description: 'PDF file',
content: {'application/pdf': {schema: {type: 'string', format: 'binary'}}},
},
},
})
async generatePdf(): Promise<Buffer> {
// HTML content to be converted to PDF
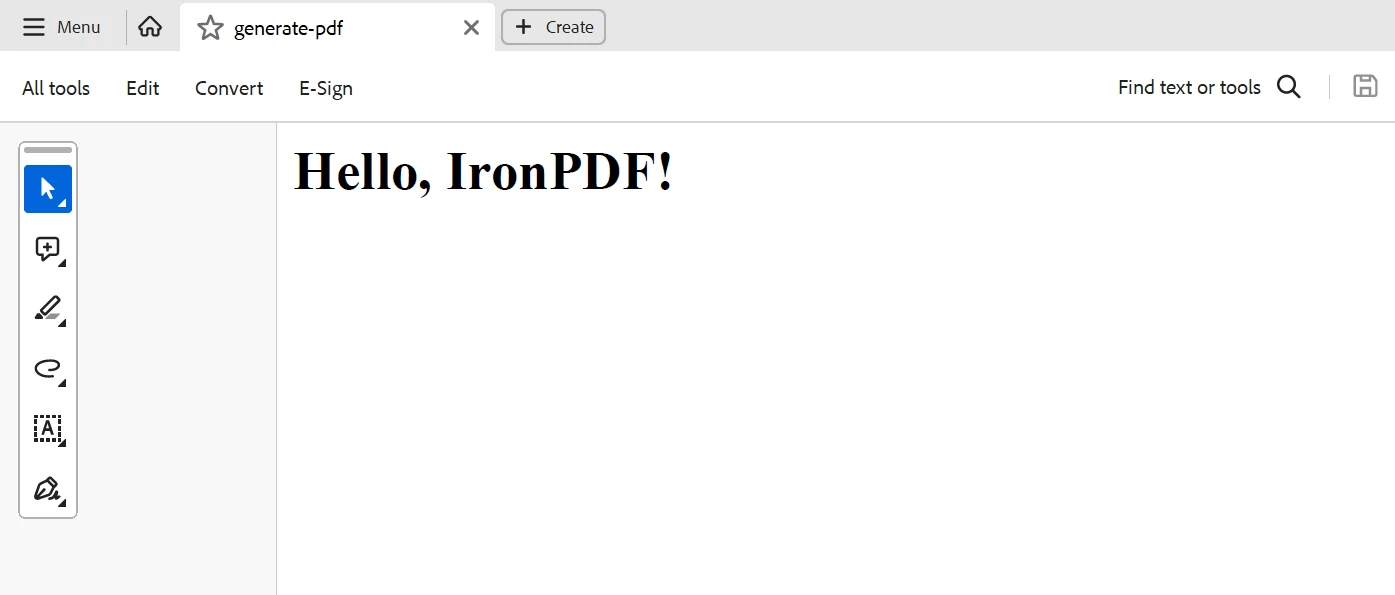
const htmlContent = '<html><body><h1>Hello, IronPDF!</h1></body></html>';
// Generate PDF from HTML
const pdf = await IronPdf.PdfDocument.fromHtml(htmlContent);
// Get the PDF as a Buffer
const pdfBuffer = await pdf.saveAsBuffer();
// Return the PDF buffer to serve as a downloadable file
return pdfBuffer;
}
}Tworzenie instancji Report i generowanie plików PDF obsługuje ReportController. Treść HTML jest konwertowana na bufor PDF przy użyciu IronPDF i zwracana za pomocą metody generatePdf. Aby renderować HTML jako PDF, funkcja generatePdf wykorzystuje IronPDF. Kontroler LoopBack z łatwością obsługuje tę integrację. Treść HTML od klienta jest następnie odbierana poprzez zdefiniowanie punktu końcowego GET, /generate-pdf. Przekształcamy dostarczone informacje HTML na plik PDF w punkcie końcowym, wykorzystując bibliotekę IronPDF.
W szczególności używamy pdf.saveAsBuffer() do utworzenia bufora binarnego pliku PDF oraz IronPdf.PdfDocument.fromHtml(htmlContent) do skonstruowania obiektu PDF na podstawie pliku JSON. Następnie klient otrzymuje ten bufor z powrotem z odpowiednim typem MIME (application/pdf). Wszelkie problemy pojawiające się podczas tworzenia plików PDF są wykrywane i rejestrowane przez serwer, który nasłuchuje na porcie 3000. Klient otrzymuje w odpowiedzi kod statusu 500. Ta konfiguracja umożliwia tworzenie dynamicznych plików PDF na podstawie treści HTML, co jest pomocne podczas tworzenia rachunków, raportów lub innych dokumentów dla aplikacji internetowej.
Wnioski
Wreszcie, integracja IronPDF z LoopBack 4 stanowi potężne połączenie do tworzenia aplikacji internetowych. Dzięki LoopBack 4 programiści mogą z łatwością tworzyć interfejsy API RESTful przy użyciu solidnego frameworka, który pozwala im skupić się na logice biznesowej zamiast na powtarzalnym kodzie. Jednak IronPDF posiada płynne funkcje generowania plików PDF, które umożliwiają tworzenie dynamicznych dokumentów PDF na podstawie tekstu HTML.
Ponadto proces tworzenia oprogramowania jest usprawniony dzięki elastyczności i łatwości obsługi zarówno LoopBack 4, jak i IronPDF, co pozwala programistom na szybkie tworzenie wysokiej jakości aplikacji. Ponieważ LoopBack 4 zarządza kontrolą dostępu do zaplecza API, a IronPDF zajmuje się tworzeniem plików PDF, programiści mogą skupić się na zaspokajaniu potrzeb biznesowych i zapewnianiu doskonałych wrażeń użytkownikom.
Możemy zagwarantować bogate w funkcje, wysokiej klasy rozwiązania programowe dla klientów i użytkowników końcowych poprzez integrację IronPDF i ośmiu innych bibliotek z Państwa stosem programistycznym. Ponadto ta solidna podstawa pozwoli zoptymalizować procesy, systemy zaplecza i inicjatywy. Ceny tych technologii zaczynają się od $799 za sztukę. Doskonale nadają się one do współczesnych projektów programistycznych dzięki obszernej dokumentacji, aktywnej społeczności programistów online oraz częstym aktualizacjom.