
Updated March 4, 2024
How to Read PDF Table in C#
Extracting data from a PDF file is quite a challenge in C#. The data can be in the form of text, images, charts, graphs, tables, etc. Sometimes, business analysts need to extract data to perform data analysis and make decisions based on those results. The IronPDF C# PDF Library is a great solution for extracting data from PDF files.
This article will demonstrate how to extract table data from PDF documents in C# using the IronPDF Library.
How to Read PDF Table in C#
IronPDF - C# PDF Library
IronPDF is a C# .NET Library, that helps developers read, create, and edit PDF documents easily in their software applications. Its Chromium Engine renders PDF documents with accuracy and speed. It allows developers to convert from different formats to PDF and vice versa seamlessly. It supports the latest .NET 7 Framework, as well as .NET Framework 6, 5, 4, .NET Core, and Standard.
Moreover, the IronPDF .NET API also enables developers to manipulate and edit PDFs, add headers and footers, and extract text, images, and tables from PDFs with ease.
Some Important Features include
- Load and Create PDF files (HTML to PDF, Images to PDF)
- Save and Print PDF files
- Merge and Split PDF files
- Extract Data (Text, Images, Table) from a PDF file
Steps to Extract Table Data in C# using IronPDF Library
To extract table data from PDF documents, we need the following components installed on the local computer system:
- Visual Studio - Visual Studio 2022 is the official IDE for C# development and it must be installed on the computer. Please download and install it from the Visual Studio website.
Create Project - Create a console app for extracting data. Follow the steps below to create a project:
Open Visual Studio 2022 and then click on Create a new project button
 Visual Studio's start screen
Visual Studio's start screenNext, Select C# Console Application and click on next
 Create a new Console Application in Visual Studio
Create a new Console Application in Visual StudioNext, type the name of your project "ReadPDFTable" and click next
 Configure the newly created application
Configure the newly created applicationChoose ".NET Framework 6 long-term support" for your project.
 Select a .NET Framework
Select a .NET Framework- Click the Create button, and the console project will be created. Now, we are ready to extract table data from PDF documents programmatically.
Install IronPDF - There are 3 different methods to install the IronPDF library. They are as follows:
Using Visual Studio. Visual Studio contains the NuGet Package Manager which helps to install all NuGet packages in C# applications.
- Click Tools in the top menu, or
Right-click the project in the Solution Explorer
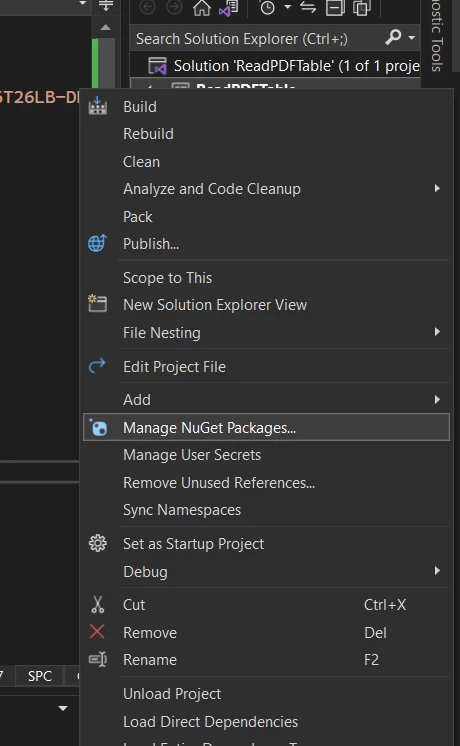 Tools & Manage NuGet Packages
Tools & Manage NuGet PackagesOnce NuGet Package Manager is opened, browse for IronPDF and click install, as shown below:
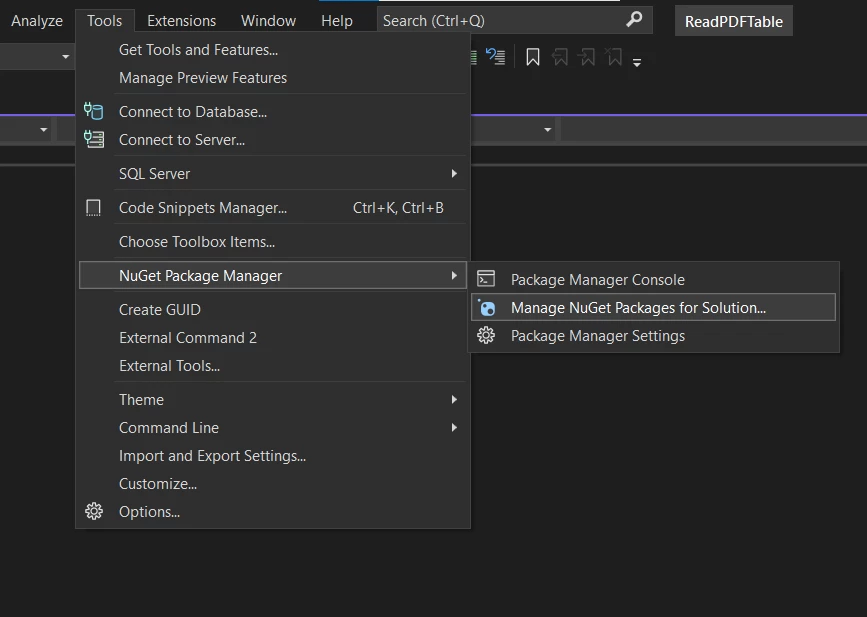 Tools & Manage NuGet Packages
Tools & Manage NuGet Packages
- Download NuGet Package directly. Another easy way to download and install IronPDF is by visiting its page on the NuGet website.
- Download IronPDF .DLL Library. IronPDF can also be downloaded from the IronPDF website. Click on: IronPDF DLL download to download and install it. Remember you will have to reference the .DLL in your project to use it.
Create a PDF Document with a Table Data
Before creating anything, the IronPDF namespace is needed to add into the file and set the license key to use the ExtractText methods from the IronPDF Library.
using IronPdf;
License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";using IronPdf;
License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY";Imports IronPdf
License.LicenseKey = "YOUR-TRIAL/PURCHASED-LICENSE-KEY"Here, a PDF document will be created from an HTML string containing a table and then extract that data using IronPDF. The HTML is stored in a string variable, and the code is as follows:
string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h2>" +
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";string HTML = "<html>" +
"<style>" +
"table, th, td {" +
"border:1px solid black;" +
"}" +
"</style>" +
"<body>" +
"<h1>A Simple table example</h2>" +
"<table>" +
"<tr>" +
"<th>Company</th>" +
"<th>Contact</th>" +
"<th>Country</th>" +
"</tr>" +
"<tr>" +
"<td>Alfreds Futterkiste</td>" +
"<td>Maria Anders</td>" +
"<td>Germany</td>" +
"</tr>" +
"<tr>" +
"<td>Centro comercial Moctezuma</td>" +
"<td>Francisco Chang</td>" +
"<td>Mexico</td>" +
"</tr>" +
"</table>" +
"<p>To understand the example better, we have added borders to the table.</p>" +
"</body>" +
"</html>";Dim HTML As String = "<html>" & "<style>" & "table, th, td {" & "border:1px solid black;" & "}" & "</style>" & "<body>" & "<h1>A Simple table example</h2>" & "<table>" & "<tr>" & "<th>Company</th>" & "<th>Contact</th>" & "<th>Country</th>" & "</tr>" & "<tr>" & "<td>Alfreds Futterkiste</td>" & "<td>Maria Anders</td>" & "<td>Germany</td>" & "</tr>" & "<tr>" & "<td>Centro comercial Moctezuma</td>" & "<td>Francisco Chang</td>" & "<td>Mexico</td>" & "</tr>" & "</table>" & "<p>To understand the example better, we have added borders to the table.</p>" & "</body>" & "</html>"Next, the ChromePdfRenderer is used to create a PDF from an HTML string. The code is as follows:
ChromePdfRenderer renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");ChromePdfRenderer renderer = new ChromePdfRenderer();
PdfDocument pdfDocument = renderer.RenderHtmlAsPdf(HTML);
pdfDocument.SaveAs("table_example.pdf");Dim renderer As New ChromePdfRenderer()
Dim pdfDocument As PdfDocument = renderer.RenderHtmlAsPdf(HTML)
pdfDocument.SaveAs("table_example.pdf")The SaveAs method will save the PdfDocument object to a PDF file named "table_example.pdf". The saved file is shown below:
 Search for IronPDF in NuGet Package Manager UI
Search for IronPDF in NuGet Package Manager UI
Extract Table Data from PDF Documents using IronPDF
To extract data from PDF tables, open the document using the PdfDocument object and then use the ExtractAllText method to retrieve the data for further analysis. The following code demonstrates how to achieve this task:
PdfDocument pdfDocument = new PdfDocument("table_example.pdf");
string text = pdfDocument.ExtractAllText();PdfDocument pdfDocument = new PdfDocument("table_example.pdf");
string text = pdfDocument.ExtractAllText();Dim pdfDocument As New PdfDocument("table_example.pdf")
Dim text As String = pdfDocument.ExtractAllText()The above code analyzes the entire PDF document using the ExtractAllText method and returns the extracted data, including the tabular data, in a string variable. The value of the variable can then be displayed or stored in a file for later use. The following code displays it on the screen:
Console.WriteLine("The extracted Text is:\n" + text);Console.WriteLine("The extracted Text is:\n" + text);Imports Microsoft.VisualBasic
Console.WriteLine("The extracted Text is:" & vbLf & text)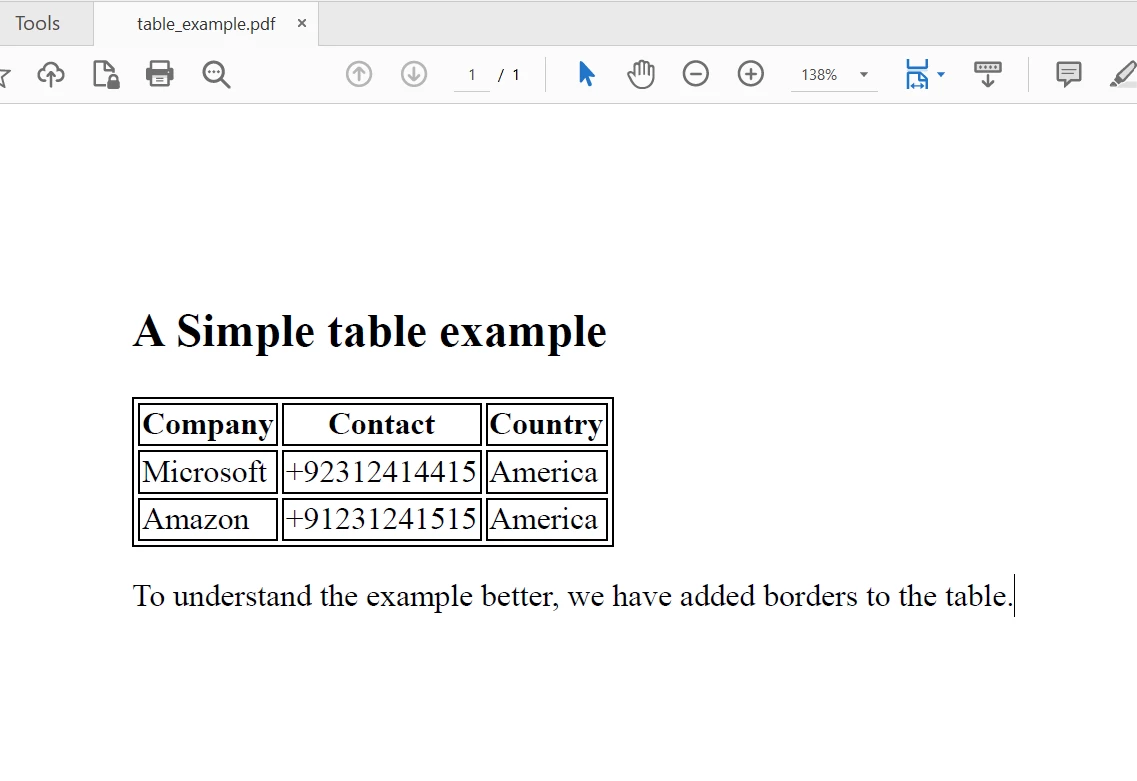 The PDF file to extract text
The PDF file to extract text
Extracting Tabular Data from Extracted Text Content
C# provides a String.Split method which helps to split the string based on a delimiter. The following code will help you limit the output to table data only.
string[] textList = text.Split("\n");
foreach (string textItem in textList)
{
if (textItem.Contains("."))
{
continue;
}
else
{
Console.WriteLine(textItem);
}
}string[] textList = text.Split("\n");
foreach (string textItem in textList)
{
if (textItem.Contains("."))
{
continue;
}
else
{
Console.WriteLine(textItem);
}
}Imports Microsoft.VisualBasic
Dim textList() As String = text.Split(vbLf)
For Each textItem As String In textList
If textItem.Contains(".") Then
Continue For
Else
Console.WriteLine(textItem)
End If
Next textItemThis simple code example helps to extract only table cell data from the extracted text. First, the text lines are split and saved in a string array. Then, each array element is iterated and the ones with a full stop "." at the end are skipped. In most cases, only the tabular data is retrieved from the extracted data, although it may retrieve other lines as well. The output is as follows:
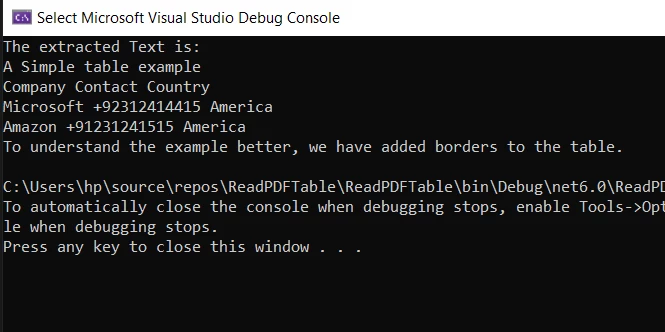 The Console displays extracted texts
The Console displays extracted texts
From the above screenshot, it can be seen that the table data formatting and logical structure are preserved in the Console.WriteLine method output. You can find more details on how to extract data from PDF documents using IronPDF in this code example.
The output can also be saved to a CSV file which can be later formatted and edited for more data analysis. The code is as follows:
using (StreamWriter file = new StreamWriter("table_example.csv", false))
{
string[] textList = text.Split("\n");
foreach (string textItem in textList)
{
if (textItem.Contains("."))
{
continue;
}
else
{
file.WriteLine(textItem);
}
}
}using (StreamWriter file = new StreamWriter("table_example.csv", false))
{
string[] textList = text.Split("\n");
foreach (string textItem in textList)
{
if (textItem.Contains("."))
{
continue;
}
else
{
file.WriteLine(textItem);
}
}
}Imports Microsoft.VisualBasic
Using file As New StreamWriter("table_example.csv", False)
Dim textList() As String = text.Split(vbLf)
For Each textItem As String In textList
If textItem.Contains(".") Then
Continue For
Else
file.WriteLine(textItem)
End If
Next textItem
End UsingThe output will be saved in a CSV file where each textItem will be one column.
Summary
This article demonstrated how to extract data and tables from a PDF document using IronPDF. IronPDF offers several useful options for extracting text from PDF files. It provides the ExtractTextFromPage method, which allows for the extraction of data from a specific page. IronPDF also facilitates the conversion of different formats to PDF such as markdown files or DOCX files and from PDF to different formats. This makes it easy for developers to integrate PDF functionality into the application development process. Additionally, it does not require Adobe Acrobat Reader to view and edit PDF documents.
IronPDF is free for development and can be licensed for commercial use. It provides a free trial license to test out the full functionality of the library. You can find more detailed information on this link.


