Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library

Pandas is a popular data analysis tool in the Python programming language, renowned for its ease of use and versatility in handling tabular data. This guide will take you through the essentials of using Pandas, focusing on practical examples and efficient techniques for data manipulation and analysis.
The primary structure in Pandas is the DataFrame, a powerful tool for data analysis and manipulation. To begin, let's explore how to access data within a DataFrame.
For instance, if you have a CSV file containing your data, you can load it into a DataFrame and start manipulating it. The below code demonstrates how to load data from a CSV file:
import pandas as pd
df = pd.read_csv('your_file.csv')Once loaded, there are several ways to access data in the DataFrame. You can access column data using the column index or the column's name. For example, the below code access data from a column named 'data':
column_data = df['data']Similarly, you can also access row data accessing row data using row indices or conditions:
row_data = df.loc[0] # Accesses the first rowA common issue in data analysis is dealing with null values. Pandas provides robust methods to handle these. The code fills null values with a specified value, or you can drop rows or columns with nulls. Here's a code example of how to fill null values:
df.fillna(0, inplace=True)DataFrames are versatile in allowing the creation of new columns. Whether it's a new integer column or a column derived from existing data, the process is straightforward. Here's an example of adding a new column to a DataFrame:
df['new_column'] = df['existing_column'] * 10You can also filter data based on conditions. For example, if you want to create a new column with data from a column named 'data' greater than a certain value:
df['new_column'] = df[df['column_named_data'] > value]Pandas excel in grouping and aggregating data. The following code uses the groupby method and groups data by a specified column and calculates aggregate functions like mean, sum, etc.:
grouped_data = df.groupby('column_name').mean()Handling date and time is crucial in many datasets. If your data frame has a date column, Pandas simplifies tasks like filtering by date, aggregating by month or year, etc. Here's a basic example:
df['date_column'] = pd.to_datetime(df['date_column'])
For more complex data manipulation needs, Pandas allows you to write custom functions and apply them to your DataFrame. This is particularly useful for scenarios that require a language-integrated query approach.
def custom_function(row):
# Your custom manipulation
return modified_row
df.apply(custom_function, axis=1)Pandas integrates well with libraries like Matplotlib and Seaborn for data visualization. Displaying data in a visual format can be as simple as shown in the following source code:
df.plot(kind='bar')The above code uses the plot method to plot a bar chart for data visualization.
Pandas, as we have discussed, is a robust tool for data manipulation and analysis in Python. Complementing its capabilities, IronPDF, a library developed by Iron Software, offers additional functionalities that can elevate data analysis workflows, particularly when dealing with PDF content.
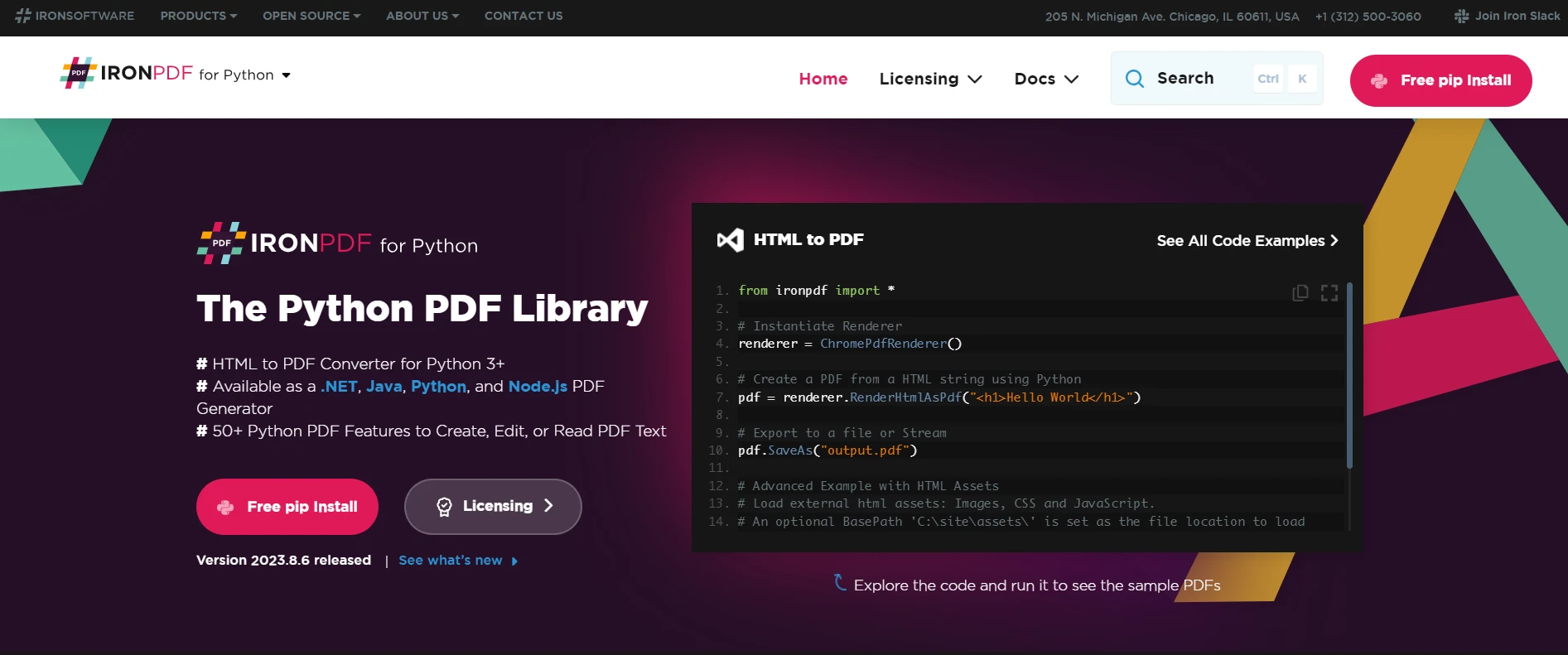
IronPDF is a versatile Python PDF library for creating, editing and extracting PDF content within Python projects. It is designed to work across various platforms including Windows, Mac, Linux, and cloud environments, making it a suitable choice for diverse Python projects. This library is particularly powerful in handling PDF files, offering a seamless experience and efficient processing, which is crucial for developers working with PDF data.
Integrating IronPDF with Pandas opens up possibilities for more advanced data handling and reporting. Imagine an analysis workflow where you use Pandas for data manipulation and analysis, and then seamlessly convert your results and visualizations into a professionally formatted PDF report using IronPDF. This integration can significantly streamline the process of sharing and presenting data analysis outcomes.
In conclusion, while Pandas provides the foundation for data analysis, integrating IronPDF adds a new dimension to the data analysis workflow in Python. This combination not only enhances the efficiency of data manipulation and analysis processes but also significantly improves the way data is presented and shared, making it an invaluable asset for Python-based data analysts and scientists.
IronPDF for users interested in exploring its features before making a purchase.
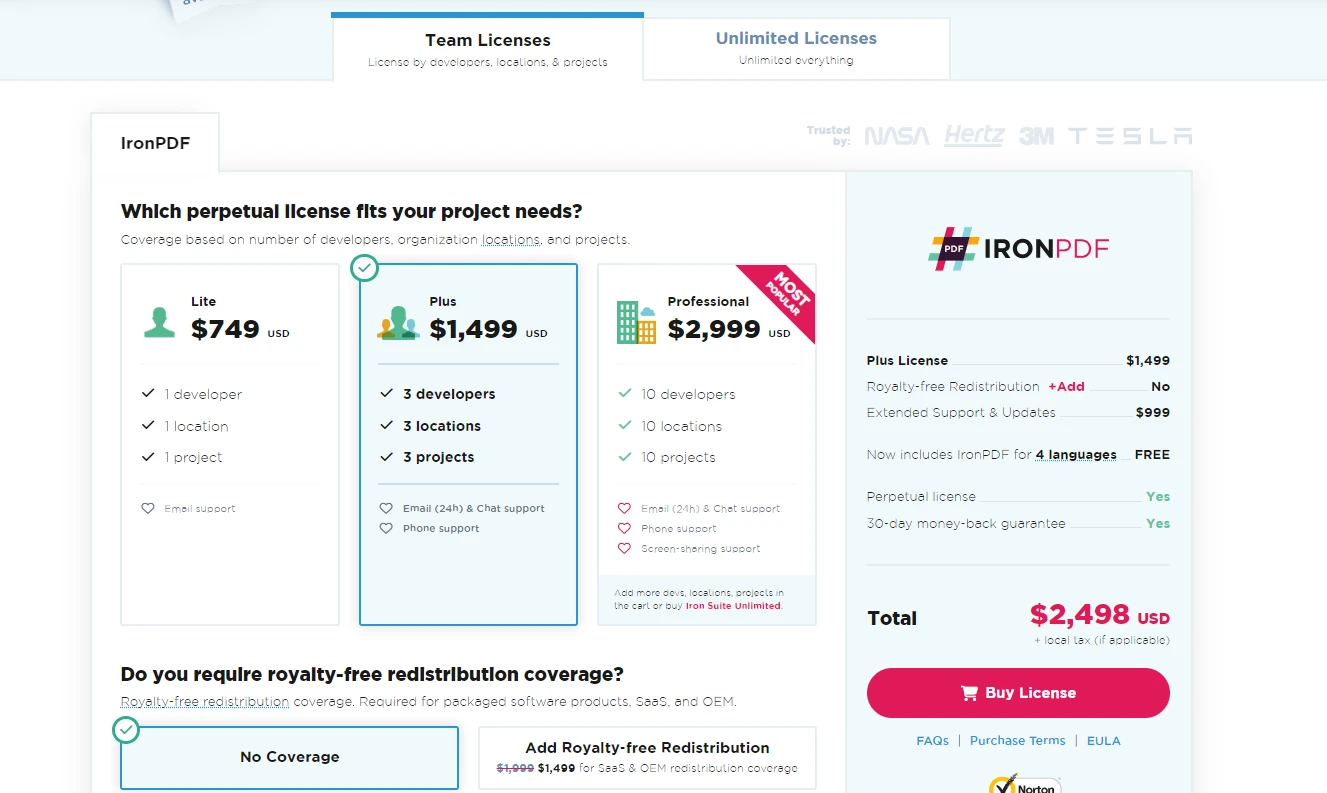
For those looking to acquire a full license, IronPDF allows users to choose a plan that best fits their project's needs and budget.
30-day Trial Key instantly.
30-day Trial Key instantly.
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com

pip install ironpdf-2024.5-py37-none-win_amd64.whiWant to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
9 .NET API products for your office documents
Thank you!
Your license key has been delivered to the email provided. Contact us

24-Hour Upgrade Offer:
Save 50% on a
Professional Upgrade
Go Professional to cover 10 developers
and unlimited projects.
hours
:
minutes
:
seconds

Professional
$600 USD
$299 USD
5 .NET Products for the Price of 2
Total Suite Value:
$7,192 USD