Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library

The programming language Python is high-level and versatile. Code readability is a priority in its design philosophy, which uses substantial indentation. Both Python's types and trash collection are dynamic. It supports a variety of paradigms for programming, such as structured (especially procedural), object-oriented, and functional programming. Considering its extensive standard library, it is frequently called a "batteries included" language.
Adobe created the Portable Document Format (PDF) in 1992 to deliver documents, including text formatting and graphics, in a way that is independent of application software, hardware, and operating systems. PDF is now standardized as ISO 32000. Each PDF file, which is based on the PostScript language, contains the information required to show a fixed-layout flat page, including the text, fonts, vector graphics, raster images, and other elements. John Warnock, a co-founder of Adobe, started "The Camelot Project" in 1991, and that is where PDF had its start.
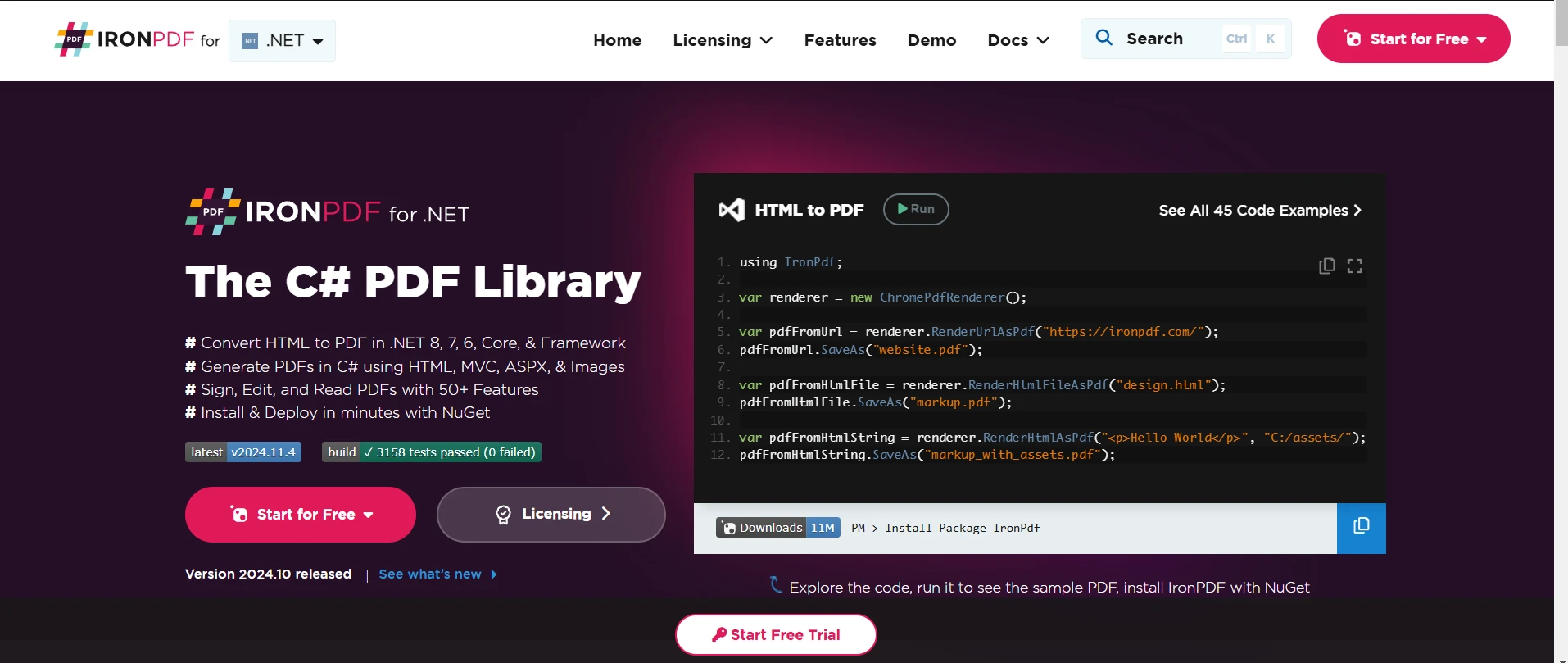
When it comes to document sharing, the Adobe-created Portable Document Format (PDF) is crucial for preserving the integrity of text-rich and aesthetically beautiful content. Most frequently, a specific program is required in order to browse online PDF files. These days, many important digital publications require PDF files. Organizations frequently utilize PDF files to create professional paperwork and invoices. In this Article, We are going to use the top PDF Python library which can be used by our team frequently to parse a PDF document. They are
The IronPDF Python library offers a wide range of PDF operations and facilitates effective PDF data processing, effortlessly enhancing Python programming. Its framework integration skills improve the potential for creating graphical user interfaces.
Python is a powerful programming language that many developers use because it makes it simple and quick to create graphical user interfaces. It differs from other programming languages because of its dynamic nature. It is easy to integrate the IronPDF library into Python, which enables effective handling and processing of PDF data.
Developers can make use of a variety of pre-installed tools and well-known Python libraries, such as PyQt, wxWidgets, Kivy, and many others, for the quick and secure development of fully complete graphical user interfaces.
A Python module called PyPDF2 enables the manipulation of PDF files. It can be used to produce fresh PDF files, edit current ones, and extract information from documents. PyPDF2 is a 100% pure Python PDF library that doesn't need any uncommon modules.
The low-level API, which is built on Pygments, enables the creation of programs that efficiently generate or alter documents. With just a few lines of code, sophisticated documents like forms, booklets, or magazines can be created using the high-level API (based on ReportLab).
A tool for extracting data from PDF documents is called PDFMiner. It is a pure Python library. It exclusively focuses on gathering and analyzing text data, unlike other PDF-related technologies. With the use of PDFMiner, it is possible to find the precise placement of text on a page as well as other details like fonts or lines. It has a PDF converter that allows you to convert PDF files into other text forms, like HTML. It has a versatile PDF parser that can be applied outside of text analysis.
The ReportLab Toolkit is a Python source package that works on all platforms. Compiling some additional C code can improve performance; this is suggested but not necessary.
While we don't offer precompiled binaries for any other platforms, we do for Windows. Many UNIX-like OS manufacturers and Linux distributors offer their own binaries for download; these binaries are installed with the source code when using the appropriate package manager.
ReportLab is now available in the package repositories of most Linux systems. These, however, are not updated by ReportLab and may not be the most recent.
The above comparison is based on my knowledge which we have used for parsing the PDF documents. Each library is capable of parsing the PDF document in different ways. When it comes to the open source library it is free to use the library, but they do not have enough document information about the PDF library with PyPDF2 and PDFMiner. On the other hand, ReportLab PDF library calculated the cost based on the PDF pages.
The IronPDF library converts any number of pages into PDF. In my view, IronPDF is better when it comes to PDF processing, as Need only limited knowledge to use this library, and it has built-in features that allow us to edit scanned PDF documents.
30-day Trial Key instantly.
30-day Trial Key instantly.
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com

pip install ironpdf-2024.5-py37-none-win_amd64.whiWant to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
9 .NET API products for your office documents
Thank you!
Your license key has been delivered to the email provided. Contact us

24-Hour Upgrade Offer:
Save 50% on a
Professional Upgrade
Go Professional to cover 10 developers
and unlimited projects.
hours
:
minutes
:
seconds

Professional
$600 USD
$299 USD
5 .NET Products for the Price of 2
Total Suite Value:
$7,192 USD