Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library

In the digital age, PDF (Portable Document Format) files have become a ubiquitous format for sharing and distributing documents across various platforms. However, the process of extracting images from PDFs is a common task in many applications, from content analysis and data extraction to image processing and archiving. Python, being a versatile and popular programming language, offers a range of powerful libraries and tools that simplify the process of acquiring images from PDF documents.
In this article, we will delve into the world of Python-based solutions to extract images from PDFs, exploring different methods, techniques, and libraries that empower developers to effortlessly navigate and extract images from these versatile documents. Whether you are a data scientist, a developer, or simply dealing with PDF content, harnessing Python's capabilities to extract images from PDF files will undoubtedly enhance your workflow and open up a host of possibilities for image-based applications.
In this article, we will use IronPDF Python to extract images from a PDF file using Python code.
IronPDF for Python is a cutting-edge and powerful library that brings a new dimension to PDF document handling in Python. As a comprehensive solution for PDF tasks, IronPDF enables seamless integration of advanced PDF features into applications.
IronPDF provides a wide range of tools and APIs for tasks like creating PDFs from scratch, converting HTML into high-quality PDFs, and managing PDF pages through actions like merging, splitting, and editing. These tools are user-friendly and efficient. With its user-friendly interface and extensive documentation, IronPDF unlocks possibilities for developers.
Whether creating professional reports and invoices automating workflows, or managing documents, IronPDF provides a valuable asset in the realm of document management and automation, making it an essential tool for any developer seeking to leverage the power of PDFs in Python applications.
PdfDocument.FromFile method to load PDF file using file path from local disk.ExtractAllImages method to extract images from PDF files.Before delving into the world of obtaining images from PDFs using Python, let's ensure we have the necessary prerequisites in place:
IronPDF Library: To utilize the powerful capabilities of IronPDF, you'll need to install it using pip, the Python package manager. Simply open your command-line interface and execute the following command:
pip install ironpdf
Once these prerequisites are in place, you can explore the step by step guide through the exciting world of retrieving images from PDFs using Python and IronPDF.
Here are the steps to create a new Python Project in PyCharm.
Click on File and select New Project from the dropdown menu.
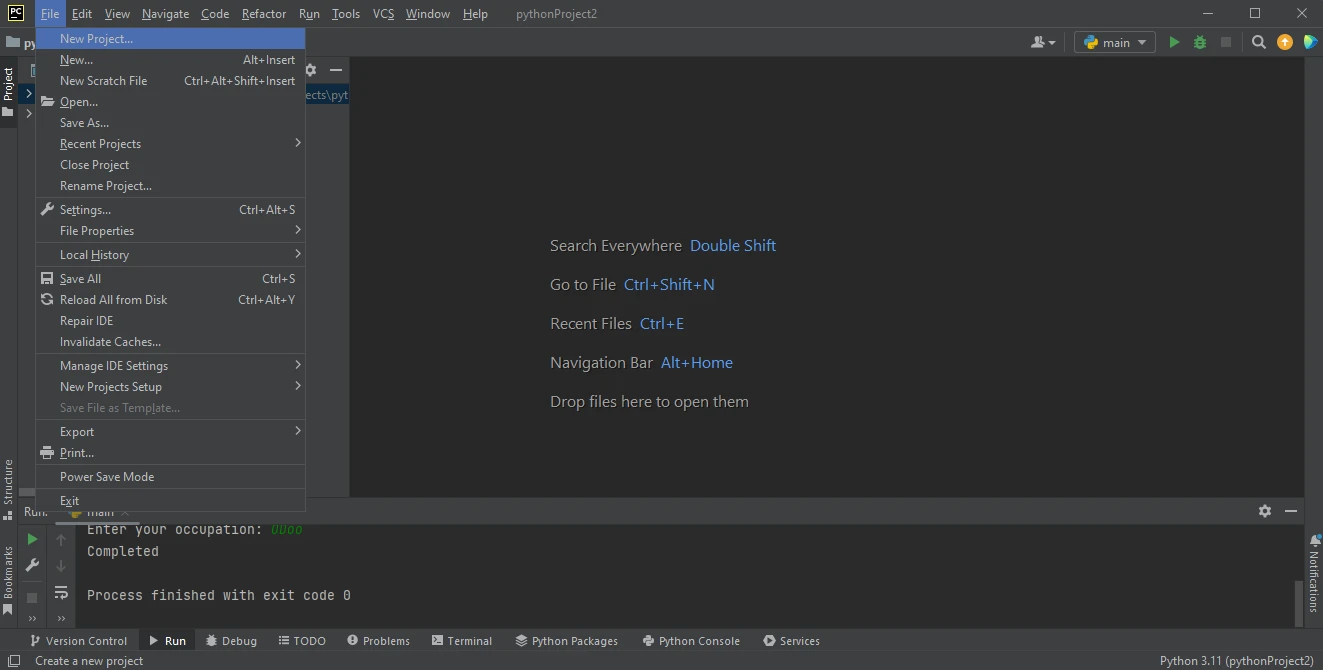
In this window, enter your project name in the Location field at the top. Choose the environment; if you are using a virtual environment, select it from the provided options.
Your Python project is now created and ready to be used for various tasks, such as extracting images.
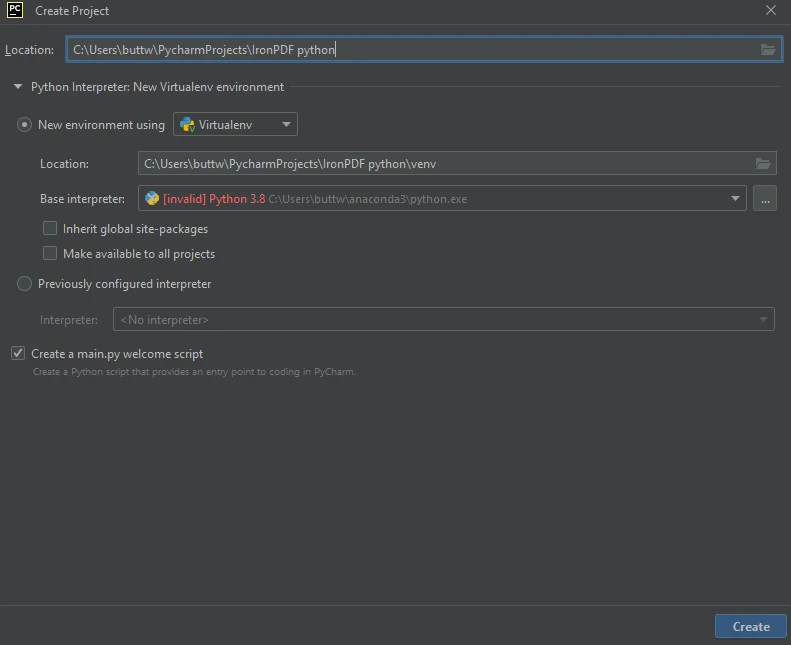
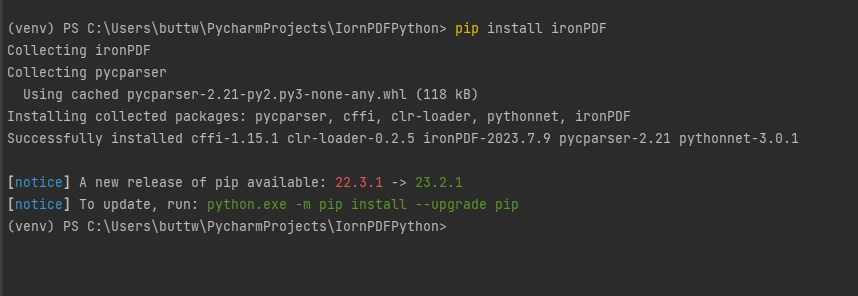
To install IronPDF, simply open the terminal or separate command prompt and enter the command pip install ironpdf, then press the Enter key. The terminal will display the following output.
IronPDF empowers developers with tools and APIs to navigate PDFs and identify and extract embedded images seamlessly. Whether for analysis or integration, IronPDF streamlines extraction using Python's flexibility. This makes it essential for working on PDFs and image-based apps. It can extract all the images from a pdf file which is remarkably simple with just a few lines of code.
See the following code to Extract images from PDF using Python programming language.
from ironpdf import *
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk image
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")This code first imports the IronPDF library and then loads the PDF file from local space using only the file path with the PdfDocument.FromFile method. Then it will access each page of a PDF to extract image bytes as Image objects. These image objects from PDF pages are then saved using the SaveAs method. In the above code, the user assigns a dynamic image name based on image indices and image extension as PNG.
Simpler than alternatively using Python libraries like PyMuPDF and Pillow libraries, which use import fitz to extract images using extractImage() and use from PIL import Image to convert bytes to a PIL image instance to save image files on disk. IronPDF achieves this with just a few lines of code.
Images are extracted from all the pages of a PDF file and saved in PNG format. You also have the flexibility to modify the output format to save the available image objects by adjusting the file extension to match the desired image file formats.
Python, together with the powerful IronPDF, offers a versatile and efficient solution for the task of retrieving images from PDF files. Leveraging Python's flexibility and IronPDF's capabilities, developers can seamlessly navigate PDF documents, locate image bytes within them, and save these images with the desired image extension. The process involves obtaining images from a PDF, and the resulting image list can be further processed and manipulated as needed. By mastering the art of acquiring images from PDFs using Python, developers can enhance their workflows, automate document management, and explore a wide range of image-based applications, making it a valuable skill in the digital age.
For more features on Images from PDF files visit the following link. You can explore other operations like options to convert PDF file contents to Images, the complete tutorial is available here.
30-day Trial Key instantly.
30-day Trial Key instantly.
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com

pip install ironpdf-2024.5-py37-none-win_amd64.whiWant to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
9 .NET API products for your office documents
Thank you!
Your license key has been delivered to the email provided. Contact us

24-Hour Upgrade Offer:
Save 50% on a
Professional Upgrade
Go Professional to cover 10 developers
and unlimited projects.
hours
:
minutes
:
seconds

Professional
$600 USD
$299 USD
5 .NET Products for the Price of 2
Total Suite Value:
$7,192 USD