
Dask Python (Cómo Funciona Para Desarrolladores)
Python es un lenguaje poderoso para el análisis de datos y el aprendizaje automático, pero manejar grandes conjuntos de datos puede ser un desafío para la analítica de datos. Aquí es donde entra en juego Dask. Dask es una biblioteca de código abierto que proporciona paralelización avanzada para la analítica, permitiendo un cálculo eficiente en grandes conjuntos de datos que superan la capacidad de memoria de una sola máquina. En este artículo, veremos el uso básico de la biblioteca Dask y otra biblioteca de generación de PDF muy interesante llamada IronPDF de Iron Software para generar documentos PDF.
¿Por qué usar Dask?
Dask está diseñado para escalar tu código Python desde un solo portátil hasta un gran clúster. Se integra perfectamente con bibliotecas populares de Python como NumPy, pandas y scikit-learn, para permitir la ejecución paralela sin cambios significativos en el código.
Características principales de Dask
- Computación paralela: Dask permite ejecutar múltiples tareas simultáneamente, acelerando significativamente los cálculos.
- Escalabilidad: puede manejar conjuntos de datos más grandes que la memoria dividiéndolos en fragmentos más pequeños y procesándolos en paralelo.
- Compatibilidad: funciona bien con las bibliotecas de Python existentes, lo que facilita la integración en su flujo de trabajo actual.
- Flexibilidad: proporciona colecciones de alto nivel como Dask DataFrame, gráficos de tareas, Dask Array, Dask Cluster y Dask Bag, que imitan a pandas, NumPy y listas, respectivamente.
Cómo empezar con Dask
Instalación
Puedes instalar Dask usando pip:
pip install dask[complete]pip install dask[complete]Uso básico
Aquí hay un ejemplo sencillo para demostrar cómo Dask puede paralelizar cálculos:
import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
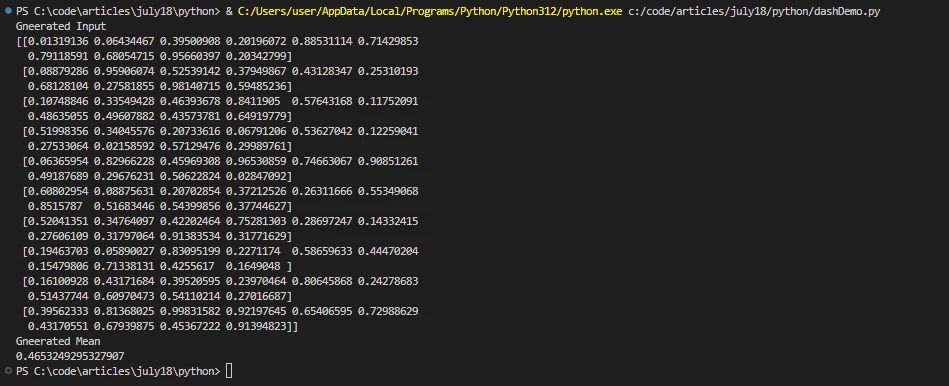
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)En este ejemplo, Dask crea un gran arreglo y lo divide en trozos más pequeños. El método compute() activa el cálculo paralelo y devuelve el resultado. El gráfico de tareas se usa internamente para lograr la computación paralela en Python Dask.
Resultado
Marcos de datos de Dask
Los DataFrames de Dask son similares a los DataFrames de pandas pero están diseñados para manejar conjuntos de datos más grandes que la memoria. Aquí hay un ejemplo:
import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
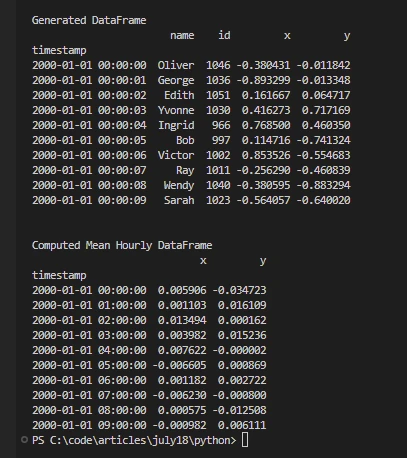
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))El código muestra la capacidad de Dask para manejar datos de series temporales, generar conjuntos de datos sintéticos y calcular agregaciones como medias horarias de manera eficiente utilizando sus capacidades de procesamiento paralelo con múltiples procesos de Python, un programador distribuido y recursos computacionales de múltiples núcleos.
Resultado
Mejores prácticas
- Comience con pequeños conjuntos de datos para comprender cómo funciona Dask antes de ampliarlo.
- Utilice el panel de control: Dask proporciona un panel de control para supervisar el progreso y el rendimiento de sus cálculos.
- Optimice el tamaño de los fragmentos: elija tamaños de fragmentos adecuados para equilibrar el uso de la memoria y la velocidad de cálculo.
Presentando IronPDF
IronPDF es una robusta biblioteca de Python diseñada para crear, editar y firmar documentos PDF usando HTML, CSS, imágenes y JavaScript. Enfatiza la eficiencia en el rendimiento con un uso mínimo de memoria. Las características clave son:
- Conversión de HTML a PDF: convierta fácilmente archivos HTML, cadenas y URL en documentos PDF, aprovechando las capacidades de representación de PDF de Chrome.
- Compatibilidad multiplataforma: funciona sin problemas con Python 3+ en Windows, Mac, Linux y varias plataformas en la nube. También es compatible con los entornos .NET, Java, Python y Node.js.
- Edición y firma: personalice las propiedades del PDF, aplique medidas de seguridad como contraseñas y permisos, y agregue firmas digitales sin problemas.
- Plantillas y configuraciones de página: personalice diseños de PDF con encabezados, pies de página, números de página, márgenes ajustables, tamaños de papel personalizados y diseños adaptables.
- Cumplimiento de estándares: estricta adhesión a los estándares PDF como PDF/A y PDF/UA, lo que garantiza la compatibilidad con la codificación de caracteres UTF-8. También es compatible con la gestión eficiente de activos como imágenes, hojas de estilo CSS y fuentes.
Instalación
pip install ironpdf
pip install daskpip install ironpdf
pip install daskGenera documentos PDF con IronPDF y Dask.
Prerrequisitos
- Asegúrate de que Visual Studio Code esté instalado.
- La versión 3 de Python está instalada.
Para empezar, crearemos un archivo Python para añadir nuestros guiones.
Abra Visual Studio Code y cree un archivo, daskDemo.py.
Instale las bibliotecas necesarias:
pip install dask
pip install ironpdfpip install dask
pip install ironpdfLuego, añade el siguiente código Python para demostrar el uso de los paquetes Dask e IronPDF:
import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
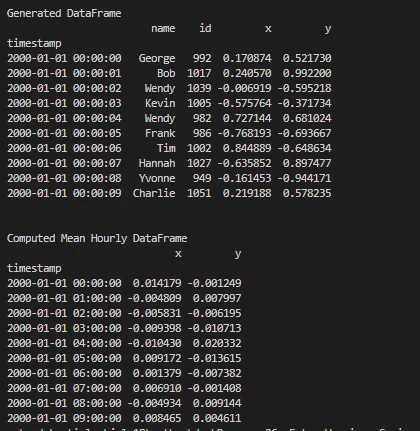
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("DemoIronPDF-Dask.pdf")import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("DemoIronPDF-Dask.pdf")Explicación del código
Este fragmento de código integra Dask para la manipulación de datos e IronPDF para la generación de PDF. Demuestra:
- Integración de Dask: utiliza
dask.datasets.timeseries()para generar un DataFrame de serie temporal sintético (df). Imprime las primeras 10 filas (df.head(10)) y calcula el DataFrame horario promedio (dfmean) basado en las columnas "x" e "y". - Uso de IronPDF : establece la clave de licencia de IronPDF usando
License.LicenseKey. Crea una cadena HTML (content) que contiene encabezados y datos de los DataFrames generados y calculados, luego convierte este contenido HTML en un PDF (pdf) usandoChromePdfRenderer()y, finalmente, guarda el PDF como "DemoIronPDF-Dask.pdf".
Este código combina las capacidades de Dask para la manipulación de datos a gran escala y la funcionalidad de IronPDF para convertir contenido HTML en un documento PDF.
Resultado

Licencia de IronPDF
IronPDF permite a los usuarios verificar sus extensas características antes de la compra.
Coloca la clave de licencia al inicio del guión antes de usar el paquete IronPDF:
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"Conclusión
Dask es una herramienta versátil que puede mejorar significativamente tus capacidades de procesamiento de datos en Python. Al habilitar la computación paralela y distribuida, te permite trabajar con grandes conjuntos de datos de manera eficiente e integrarse sin problemas en tu ecosistema Python existente. IronPDF es una potente biblioteca de Python para crear y manipular documentos PDF usando HTML, CSS, imágenes y JavaScript. Ofrece funciones como la conversión de HTML a PDF, edición de PDF, firma digital y soporte multiplataforma, lo que la hace adecuada para varias tareas de generación y gestión de documentos en aplicaciones Python.
Juntas, ambas bibliotecas permiten a los científicos de datos realizar operaciones avanzadas de analítica y ciencia de datos y luego almacenar los resultados de salida en formato PDF estándar usando IronPDF.
















