Apache PDFBoxとJava用IronPDFの比較
この記事では、JavaでPDFファイルを操作するために使用される最も人気のある2つのライブラリを取り上げます:
- IronPDF
- Apache PDFBox
どのライブラリを使用すべきでしょうか? この記事では、両方のライブラリのコア機能を比較して、どちらが本番環境に最適か決定できるようにします。
Apache PDFBOXでHTMLをPDFに変換する方法
- HTMLをPDFに変換するJavaライブラリをインストールする
- Apache PDFBox で新規文書 ・ ページ イ ン ス タ ン ス を作成
- ドキュメントとページを入力として、新しい`PDPageContentStream`を作成します。
- `PDPageContentStream`インスタンスを使用して、コンテンツを構成し、追加します。
- PDFドキュメントを`save`メソッドでエクスポートします。
IronPDF
IronPDFライブラリは、Java 8+、Kotlin、そしてScalaのHTMLからPDFの変換をサポートしています。 このクリエーターは、Windows、Linux、またはクラウドプラットフォームでのクロスプラットフォームサポートを提供します。 それは特にJavaのために設計されており、正確性、使いやすさ、および速度を優先しています。
- フォント(Web & アイコン) それはIronPDF for .NETの成功と人気に基づいています。
IronPDFの際立った機能には次のようなものがあります:
HTMLアセットを使用する
- HTML(5および以下)、CSS(スクリーン&プリント)、画像(JPG、PNG、GIF、TIFF、SVG、BMP)、JavaScript(+レンダーディレイ)
- HTMLファイル/文字列からPDFドキュメントを生成・操作
HTMLをPDFに
- HTMLファイル/文字列をPDFドキュメントに生成および操作
- URLをPDFに
画像を変換する
- 新しいPDFドキュメントに画像
- PDFを画像に
カスタム紙の設定
- カスタム用紙サイズ、方向&回転
- マージン(mm、インチ&ゼロ)
- カラー&グレー、解像度&JPEG品質
追加機能
- ウェブサイト&システムログイン
- カスタムユーザーエージェントとプロキシ
- HTTPヘッダー
Apache PDFBoxライブラリ
Apache PDFBoxはPDFファイルを扱うためのオープンソース for Javaライブラリです。 既存のドキュメントを生成、編集、操作できます。 また、ファイルからコンテンツを抽出することもできます。 このライブラリは、ドキュメント上の様々な操作を実行するために使用されるいくつかのユーティリティを提供します。
ここにApache PDFBoxの際立った特徴のいくつかを紹介します。
テキストを抽出する
- ファイルからUnicodeテキストを抽出します。
分割&マージ
- 単一のPDFを多くのファイルに分割する
- 複数のドキュメントをマージする。
フォームを埋める
- フォームからデータを抽出する
- PDFフォームを埋める。
プリフライト
- PDF/A-1b基準に対してファイルを検証する。
印刷
- 標準の印刷APIを使用してPDFを印刷する。
画像として保存
- PNG、JPEGまたはその他の画像タイプとしてPDFを保存する。
PDFを作成する
- 埋め込みフォントと画像を使用して、ゼロからPDFを開発する。
署名
- ファイルにデジタル署名します。
概要
この記事の残りの部分は以下の通りです:
- IronPDFのインストール
- Apache PDFBoxのインストール
- PDFドキュメントを作成する
- 画像をドキュメントに
- ドキュメントの暗号化
- ライセンス
- 結論
ライブラリをダウンロードしてインストールし、それらを比較し、その強力な特徴を確認します。
1. IronPDFのインストール
Java用のIronPDFをインストールするのは簡単です。 それを行うための異なる方法があります。 このセクションでは、最も人気のある2つの方法を示します。
1.1. JARをダウンロードし、ライブラリを追加する
IronPDFのJARファイルをダウンロードするには、Maven WebサイトのIronPDFを訪れて、IronPDFの最新バージョンをダウンロードします。
- ダウンロードオプションをクリックし、JARをダウンロードします。
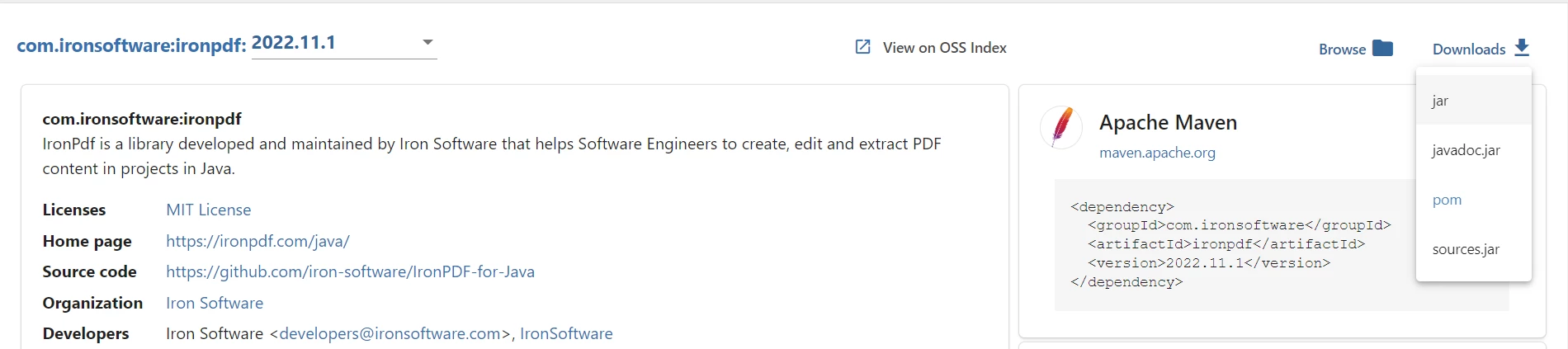
IronPDF JARをダウンロードする
JARのダウンロードが完了したら、次はライブラリをMavenプロジェクトにインストールする時です。 IDEはどれでも使用できますが、ここではNetBeansを使用します。 プロジェクトセクションで:
- ライブラリフォルダーを右クリックして、Add JAR/Folderオプションを選択します。
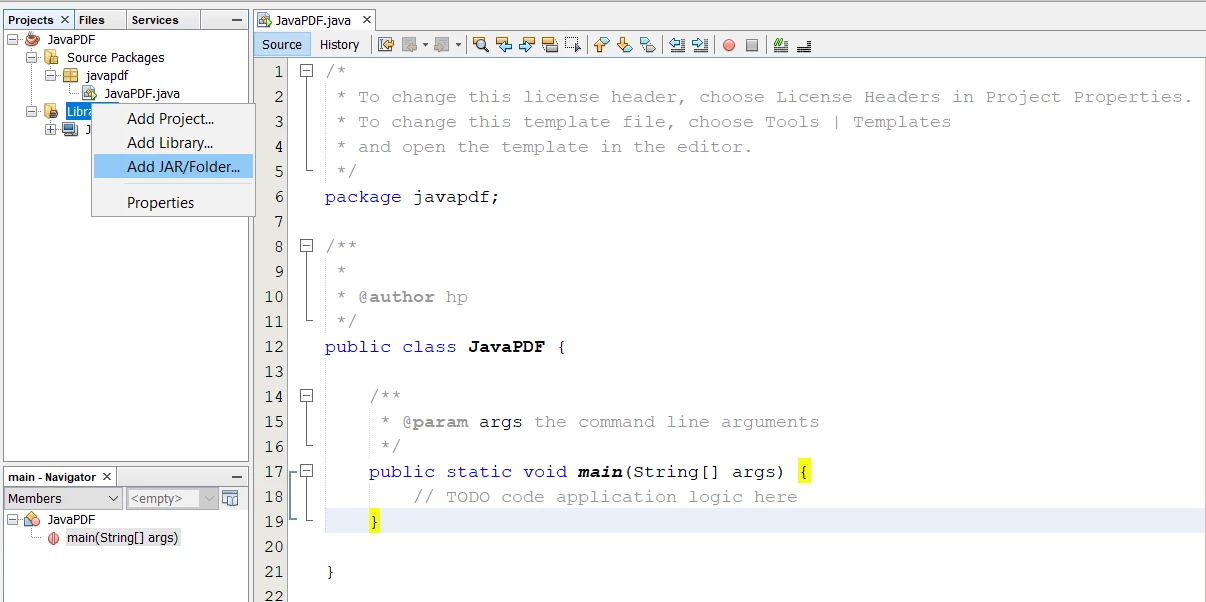
NetbeansにIronPDFライブラリを追加する
- ダウンロードしたJARのフォルダーに移動します。
- IronPDF JARを選択し、開くボタンをクリックします。
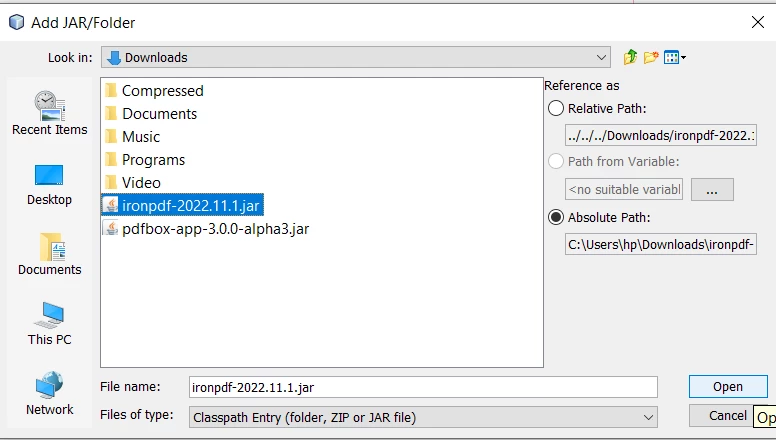
IronPDF JARを開く
1.2. 依存関係としてMavenを通じてインストールする
IronPDFをダウンロードしてインストールするもう一つの方法はMavenを使用することです。 単にpom.xmlに依存関係を追加するか、NetBeansの依存ツールを使用してプロジェクトに含めることができます。
pom.xmlにライブラリ依存を追加する
pom.xml に次の依存関係を追加します。
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>YOUR_VERSION_HERE</version>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>YOUR_VERSION_HERE</version>
</dependency>
</dependencies>依存関係機能を使用してライブラリを追加する
- 依存関係を右クリックする
- Add Dependencyを選択し、以下の詳細を更新バージョンで入力します
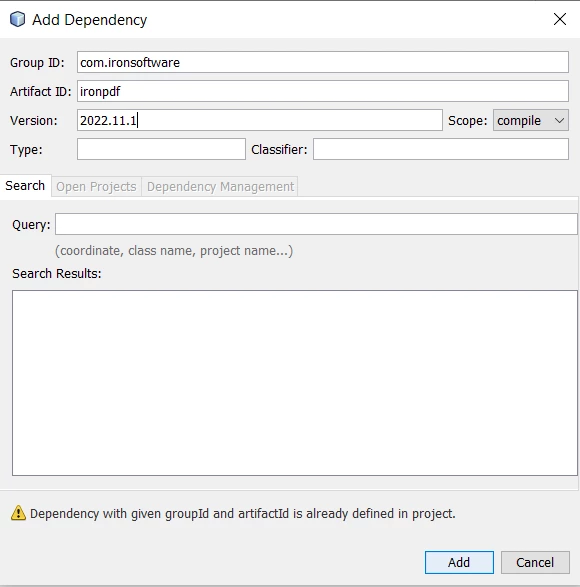
IronPDFの依存関係を追加
次に、Apache PDFBoxをインストールします。
2. Apache PDFBoxのインストール
PDFBoxをIronPDFと同じ方法でダウンロードしてインストールすることができます。
2.1. JARをダウンロードしてライブラリを手動で追加する
PDFBox JARをインストールするには、公式ウェブサイトを訪れ最新バージョンのPDFBoxライブラリをダウンロードします。
プロジェクトを作成した後、プロジェクトセクションで:
- ライブラリフォルダーを右クリックしてAdd JAR/Folderオプションを選択します。
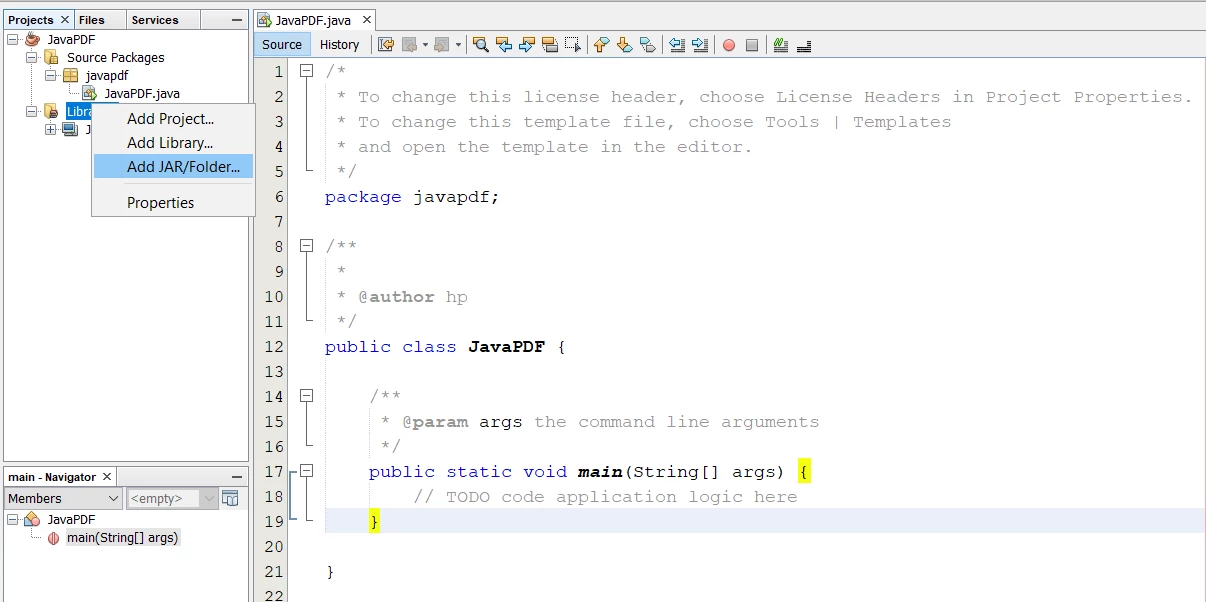
ライブラリの追加
- ダウンロードしたJARのフォルダーに移動します。
- PDFBox JARを選択し、開くボタンをクリックします。
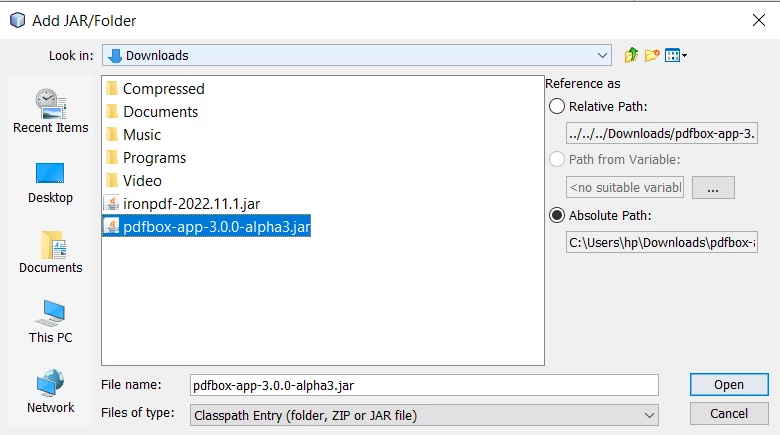
PDFBox JAR を開く
2.2. 依存関係としてMavenを通じてインストールする
pom.xmlに依存関係を追加する
次のコードをコピーしてpom.xmlに貼り付けます。
<dependencies>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-app</artifactId>
<version>3.0.0-alpha3</version>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-app</artifactId>
<version>3.0.0-alpha3</version>
</dependency>
</dependencies>これにより、PDFBox依存が自動でダウンロードされリポジトリフォルダーにインストールされます。 これで使用準備が整います。
依存関係機能を使用して依存を追加する
- プロジェクトセクションの依存関係を右クリックする
- Add Dependencyを選択し、以下の詳細を更新バージョンで入力します
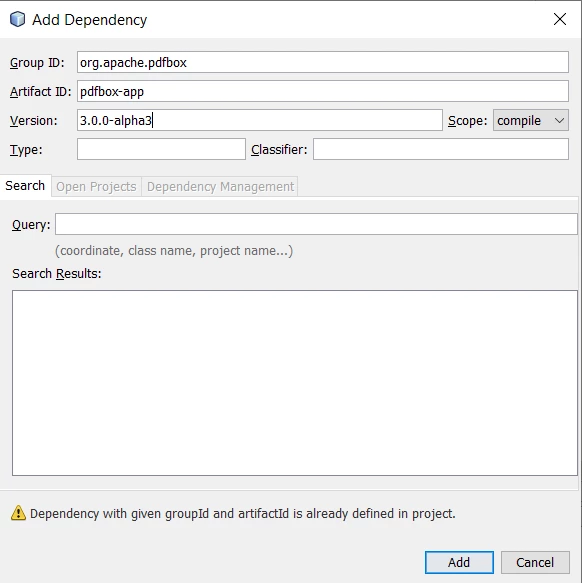
PDFBox の依存関係を追加
3. PDFドキュメントを作成する
3.1. IronPDFを使用する
IronPDFはファイルを作成するためのさまざまな方法を提供します。 最も重要な2つの方法を見ていきましょう。
既存のURLをPDFに変換
IronPDFはHTMLからドキュメントを生成するのを非常に簡単にしてくれます。 次のコードサンプルは、ウェブページのURLをPDFに変換します。
import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Set the license key and log path
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
// Convert a URL to a PDF
PdfDocument myPdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com");
// Save the PDF document to a file
myPdf.saveAs(Paths.get("url.pdf"));import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Set the license key and log path
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
// Convert a URL to a PDF
PdfDocument myPdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com");
// Save the PDF document to a file
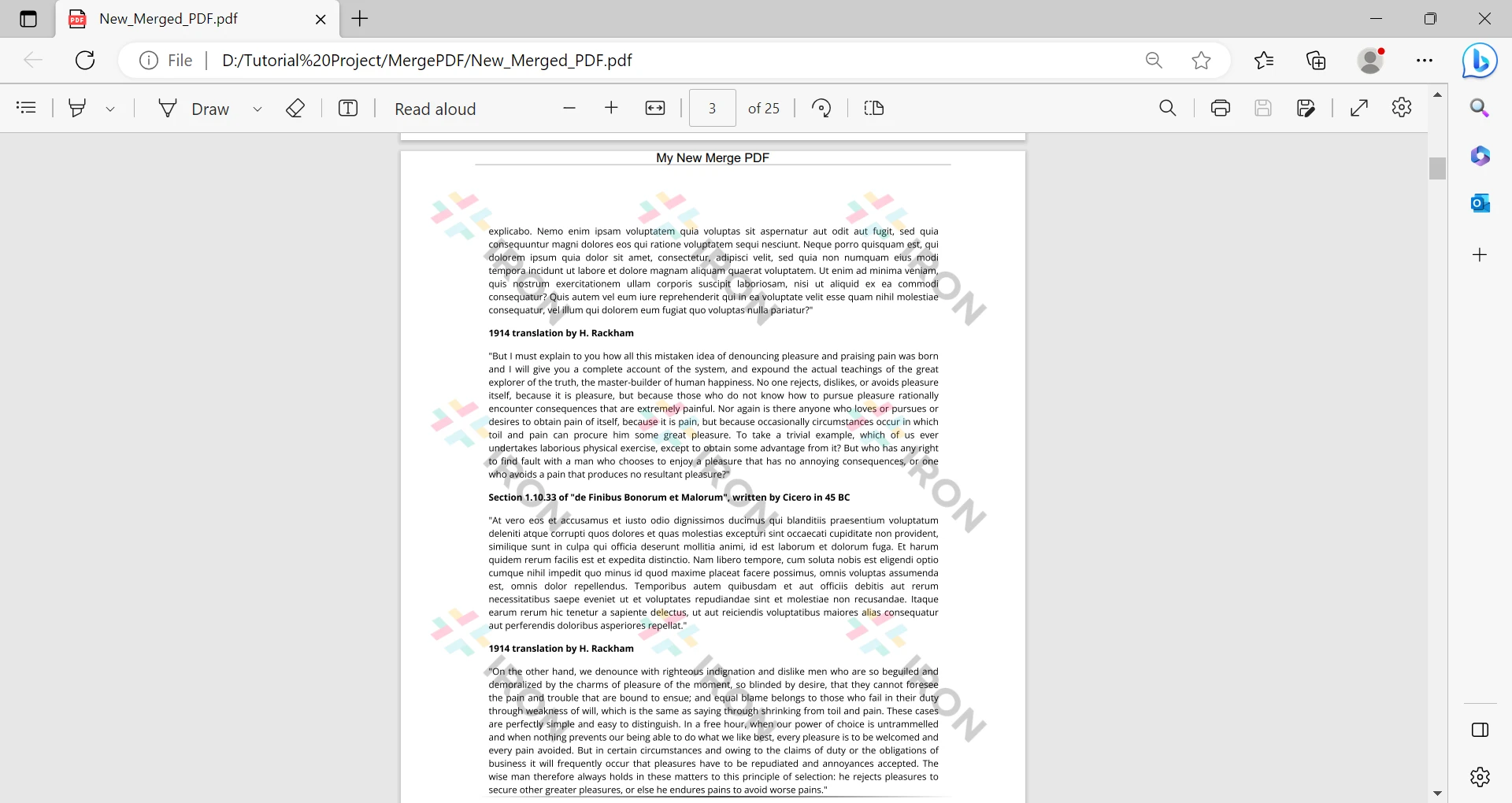
myPdf.saveAs(Paths.get("url.pdf"));出力は以下のURLで、うまくフォーマットされて次のように保存されます:
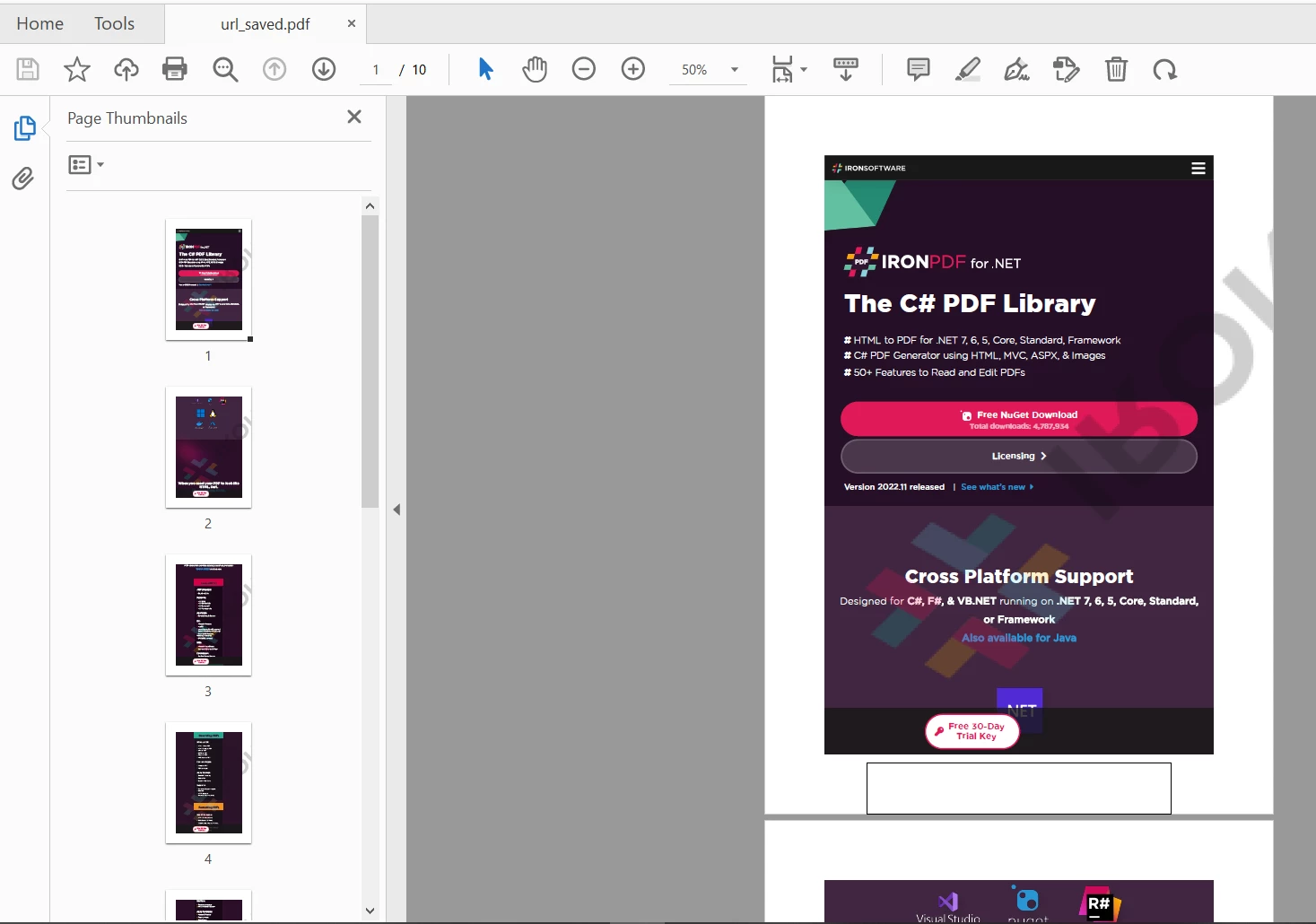
IronPDF URL出力
HTML入力文字列をPDFに変換
次のサンプルコードは、HTML文字列を使用してJavaでPDFをレンダリングする方法を示しています。 単にHTML文字列やドキュメントを使用して新しいドキュメントに変換します。
import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Set the license key and log path
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
// Convert an HTML string to a PDF
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1> ~Hello World~ </h1> Made with IronPDF!");
// Save the PDF document to a file
myPdf.saveAs(Paths.get("html_saved.pdf"));import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Set the license key and log path
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
// Convert an HTML string to a PDF
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1> ~Hello World~ </h1> Made with IronPDF!");
// Save the PDF document to a file
myPdf.saveAs(Paths.get("html_saved.pdf"));出力は以下の通りです。

IronPDF HTML出力
3.2. Apache PDFBoxを使用する
PDFBoxも異なるフォーマットから新しいPDFドキュメントを生成できますが、URLやHTML文字列から直接変換することはできません。
次のコードサンプルは、いくつかのテキストを含むドキュメントを作成します:
import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.common.*;
import org.apache.pdfbox.pdmodel.font.*;
import org.apache.pdfbox.pdmodel.graphics.image.*;
import org.apache.pdfbox.pdmodel.interactive.annotation.*;
import org.apache.pdfbox.pdmodel.interactive.form.*;
import java.io.IOException;
public class PDFBoxExample {
public static void main(String[] args) throws IOException {
// Create a document object
PDDocument document = new PDDocument();
// Add a blank page to the document
PDPage blankPage = new PDPage();
document.addPage(blankPage);
// Retrieve the page of the document
PDPage paper = document.getPage(0);
try (PDPageContentStream contentStream = new PDPageContentStream(document, paper)) {
// Begin the content stream
contentStream.beginText();
// Set the font to the content stream
contentStream.setFont(PDType1Font.TIMES_ROMAN, 12);
// Set the position for the line
contentStream.newLineAtOffset(25, 700);
String text = "This is the sample document and we are adding content to it.";
// Add text in the form of a string
contentStream.showText(text);
// End the content stream
contentStream.endText();
System.out.println("Content added");
// Save the document
document.save("C:/PdfBox_Examples/my_doc.pdf");
System.out.println("PDF created");
}
// Closing the document
document.close();
}
}import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.common.*;
import org.apache.pdfbox.pdmodel.font.*;
import org.apache.pdfbox.pdmodel.graphics.image.*;
import org.apache.pdfbox.pdmodel.interactive.annotation.*;
import org.apache.pdfbox.pdmodel.interactive.form.*;
import java.io.IOException;
public class PDFBoxExample {
public static void main(String[] args) throws IOException {
// Create a document object
PDDocument document = new PDDocument();
// Add a blank page to the document
PDPage blankPage = new PDPage();
document.addPage(blankPage);
// Retrieve the page of the document
PDPage paper = document.getPage(0);
try (PDPageContentStream contentStream = new PDPageContentStream(document, paper)) {
// Begin the content stream
contentStream.beginText();
// Set the font to the content stream
contentStream.setFont(PDType1Font.TIMES_ROMAN, 12);
// Set the position for the line
contentStream.newLineAtOffset(25, 700);
String text = "This is the sample document and we are adding content to it.";
// Add text in the form of a string
contentStream.showText(text);
// End the content stream
contentStream.endText();
System.out.println("Content added");
// Save the document
document.save("C:/PdfBox_Examples/my_doc.pdf");
System.out.println("PDF created");
}
// Closing the document
document.close();
}
}
PDFBox 位置出力
ただし、上記のコード例から contentStream.newLineAtOffset(25, 700); を削除してプロジェクトを実行すると、ページの下部に出力がある PDF が生成されます。 これはいくつかの開発者にとって非常に迷惑かもしれません。なぜなら、テキストを(x,y)座標で調整しなければならないからです。 y = 0 はテキストが下部に表示されることを意味します。

位置決め出力なしのPDFBox
4. 画像をドキュメントに
4.1. IronPDFを使用
IronPDFは複数の画像を簡単に単一のPDFに変換することができます。 単一のドキュメントに複数の画像を追加するためのコードは以下の通りです:
import com.ironsoftware.ironpdf.*;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
// Reference to the directory containing the images that we desire to convert
List<Path> images = new ArrayList<>();
images.add(Paths.get("imageA.png"));
images.add(Paths.get("imageB.png"));
images.add(Paths.get("imageC.png"));
images.add(Paths.get("imageD.png"));
images.add(Paths.get("imageE.png"));
// Render all targeted images as PDF content and save them together in one document.
PdfDocument merged = PdfDocument.fromImage(images);
merged.saveAs(Paths.get("output.pdf"));import com.ironsoftware.ironpdf.*;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
// Reference to the directory containing the images that we desire to convert
List<Path> images = new ArrayList<>();
images.add(Paths.get("imageA.png"));
images.add(Paths.get("imageB.png"));
images.add(Paths.get("imageC.png"));
images.add(Paths.get("imageD.png"));
images.add(Paths.get("imageE.png"));
// Render all targeted images as PDF content and save them together in one document.
PdfDocument merged = PdfDocument.fromImage(images);
merged.saveAs(Paths.get("output.pdf"));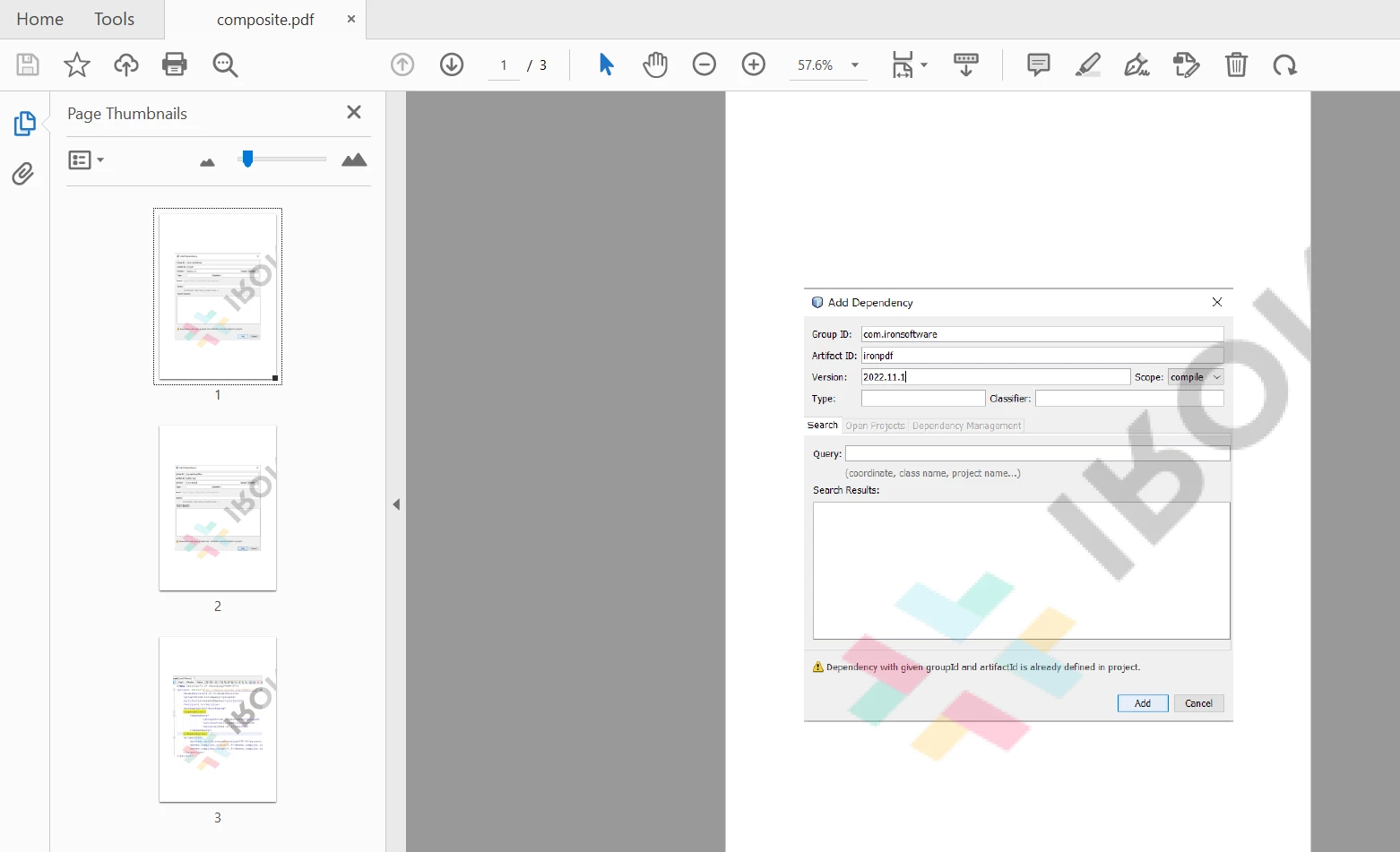
IronPDFイメージの出力
4.2. Apache PDFBoxを使用する
import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.graphics.image.*;
import java.io.IOException;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
public class ImageToPdf {
public static void main(String[] args) {
// Reference to the directory containing the images that we desire to convert
Path imageDirectory = Paths.get("assets/images");
// Create an empty list to contain Paths to images from the directory.
List<Path> imageFiles = new ArrayList<>();
PDDocument doc = new PDDocument();
// Use a DirectoryStream to populate the list with paths for each image in the directory that we want to convert
try (DirectoryStream<Path> stream = Files.newDirectoryStream(imageDirectory, "*.{png,jpg}")) {
for (Path entry : stream) {
imageFiles.add(entry);
}
for (int i = 0; i < imageFiles.size(); i++) {
// Add a Page
PDPage blankPage = new PDPage();
doc.addPage(blankPage);
PDPage page = doc.getPage(i);
// Create PDImageXObject object
PDImageXObject pdImage = PDImageXObject.createFromFile(imageFiles.get(i).toString(), doc);
// Create the PDPageContentStream object
PDPageContentStream contents = new PDPageContentStream(doc, page);
// Drawing the image in the document
contents.drawImage(pdImage, 0, 0);
System.out.println("Image inserted");
// Closing the PDPageContentStream object
contents.close();
}
// Saving the document
doc.save("C:/PdfBox_Examples/sample.pdf");
// Closing the document
doc.close();
} catch (IOException exception) {
throw new RuntimeException(String.format("Error converting images to PDF from directory: %s: %s",
imageDirectory, exception.getMessage()), exception);
}
}
}import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.graphics.image.*;
import java.io.IOException;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
public class ImageToPdf {
public static void main(String[] args) {
// Reference to the directory containing the images that we desire to convert
Path imageDirectory = Paths.get("assets/images");
// Create an empty list to contain Paths to images from the directory.
List<Path> imageFiles = new ArrayList<>();
PDDocument doc = new PDDocument();
// Use a DirectoryStream to populate the list with paths for each image in the directory that we want to convert
try (DirectoryStream<Path> stream = Files.newDirectoryStream(imageDirectory, "*.{png,jpg}")) {
for (Path entry : stream) {
imageFiles.add(entry);
}
for (int i = 0; i < imageFiles.size(); i++) {
// Add a Page
PDPage blankPage = new PDPage();
doc.addPage(blankPage);
PDPage page = doc.getPage(i);
// Create PDImageXObject object
PDImageXObject pdImage = PDImageXObject.createFromFile(imageFiles.get(i).toString(), doc);
// Create the PDPageContentStream object
PDPageContentStream contents = new PDPageContentStream(doc, page);
// Drawing the image in the document
contents.drawImage(pdImage, 0, 0);
System.out.println("Image inserted");
// Closing the PDPageContentStream object
contents.close();
}
// Saving the document
doc.save("C:/PdfBox_Examples/sample.pdf");
// Closing the document
doc.close();
} catch (IOException exception) {
throw new RuntimeException(String.format("Error converting images to PDF from directory: %s: %s",
imageDirectory, exception.getMessage()), exception);
}
}
}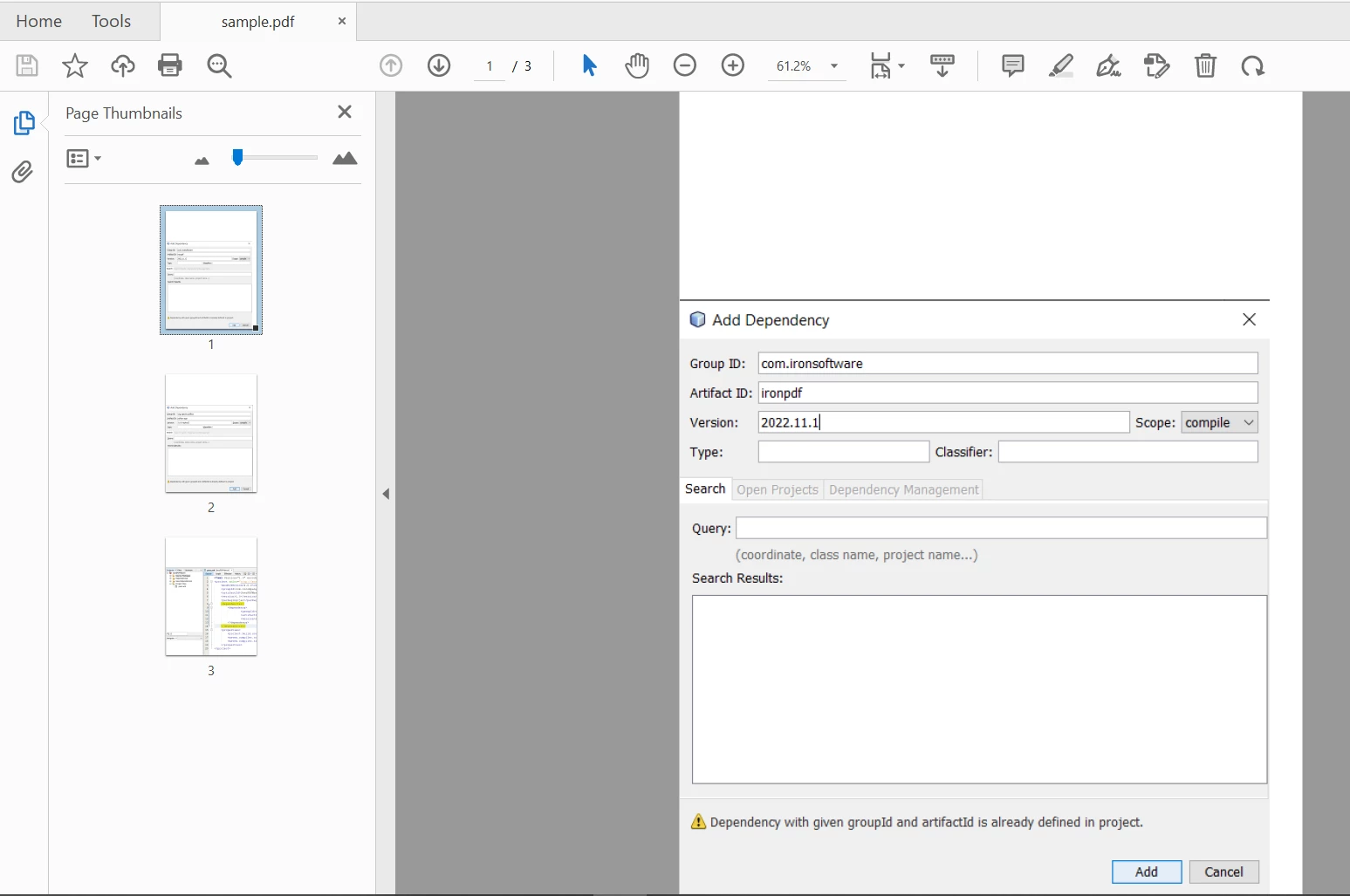
PDFBox 画像の出力
5. ドキュメントの暗号化
5.1. IronPDFを使用
IronPDFでPDFをパスワードで暗号化するためのコードは以下の通りです:
import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Open a document (or create a new one from HTML)
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/composite.pdf"));
// Edit security settings
SecurityOptions securityOptions = new SecurityOptions();
securityOptions.setOwnerPassword("top-secret");
securityOptions.setUserPassword("sharable");
// Change or set the document encryption password
SecurityManager securityManager = pdf.getSecurity();
securityManager.setSecurityOptions(securityOptions);
pdf.saveAs(Paths.get("assets/secured.pdf"));import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Open a document (or create a new one from HTML)
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/composite.pdf"));
// Edit security settings
SecurityOptions securityOptions = new SecurityOptions();
securityOptions.setOwnerPassword("top-secret");
securityOptions.setUserPassword("sharable");
// Change or set the document encryption password
SecurityManager securityManager = pdf.getSecurity();
securityManager.setSecurityOptions(securityOptions);
pdf.saveAs(Paths.get("assets/secured.pdf"));5.2. Apache PDFBoxを使用する
Apache PDFBoxもドキュメントの暗号化を提供して、ファイルをより安全にします。 メタデータのような追加情報も追加できます。 コードは次の通りです:
import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.encryption.*;
import java.io.File;
import java.io.IOException;
public class PDFEncryption {
public static void main(String[] args) throws IOException {
// Load an existing document
File file = new File("C:/PdfBox_Examples/sample.pdf");
PDDocument document = PDDocument.load(file);
// Create access permission object
AccessPermission ap = new AccessPermission();
// Create StandardProtectionPolicy object
StandardProtectionPolicy spp = new StandardProtectionPolicy("1234", "1234", ap);
// Setting the length of the encryption key
spp.setEncryptionKeyLength(128);
// Set the access permissions
spp.setPermissions(ap);
// Protect the document
document.protect(spp);
System.out.println("Document encrypted");
// Save the document
document.save("C:/PdfBox_Examples/encrypted.pdf");
// Close the document
document.close();
}
}import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.encryption.*;
import java.io.File;
import java.io.IOException;
public class PDFEncryption {
public static void main(String[] args) throws IOException {
// Load an existing document
File file = new File("C:/PdfBox_Examples/sample.pdf");
PDDocument document = PDDocument.load(file);
// Create access permission object
AccessPermission ap = new AccessPermission();
// Create StandardProtectionPolicy object
StandardProtectionPolicy spp = new StandardProtectionPolicy("1234", "1234", ap);
// Setting the length of the encryption key
spp.setEncryptionKeyLength(128);
// Set the access permissions
spp.setPermissions(ap);
// Protect the document
document.protect(spp);
System.out.println("Document encrypted");
// Save the document
document.save("C:/PdfBox_Examples/encrypted.pdf");
// Close the document
document.close();
}
}6. 価格とライセンス
IronPDFの価格とライセンス
IronPDFはシンプルなPDFアプリケーションの開発に無料で使用でき、商用利用のためにいつでもライセンスを取得できます。IronPDFはシングルプロジェクトライセンス、シングルデベロッパーライセンス、代理店および多国籍組織のためのライセンス、およびSaaS、OEM再配布ライセンスを提供しており、サポートもあります。 All licenses are available with a free trial, a 30-day money-back guarantee, and one year of software support and upgrades.
Lite パッケージは $999 で利用できます。 IronPDF製品には継続的な費用は一切ありません。 より詳しい情報は、製品のIronPDFライセンスページで入手できます。
IronPDF のライセンス
Apache PDFBoxの価格とライセンス
Apache PDFBoxは無料で利用可能です。 それは個人用、内部用、または商用の目的に関係なく無料です。
Apacheライセンス2.0(現バージョン)をApacheライセンス2.0テキストから含めることができます。 ライセンスのコピーを含めるには、単にあなたの作品に含めてください。 また、次の通知をあなたのソースコードの上部にコメントとして添付することができます。
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.結論
比較で、IronPDFは機能性と製品サポートの両方でApache PDFBoxに対して上位に立っています。 また、SaaSおよびOEMサポートも提供され、これは現代のソフトウェア開発において不可欠な要件です。 ただし、このライブラリはApache PDFBoxのように商用利用に無償ではありません。
大規模なソフトウェアアプリケーションを持つ企業は、ソフトウェア開発中に問題が発生したときに問題を解決するために、サードパーティのベンダーからの継続的なバグ修正やサポートを必要とする場合があります。 これは、Apache PDFBoxのような多くのオープンソースソリューションに欠けているもので、コミュニティの開発者たちのボランティアによるサポートに頼って維持されています。 要するに、IronPDFはビジネスおよび市場での使用に最適であり、Apache PDFBoxは個人および非商用アプリケーションに最も適しています。
IronPDFの機能をテストするための無料トライアルもあります。 試してみてまたはIronPDFを購入する。
今すぐIron SuiteのすべてのIron Software製品を大幅に割引された価格で入手できます。この素晴らしいお得情報について詳しくはIron Suiteのウェブページをご覧ください。
よくある質問
Java で HTML を PDF に変換するにはどうすればよいですか?
IronPDF の Java ライブラリを使用して HTML を PDF に変換できます。このライブラリは、HTML ストリング、ファイル、または URL を簡単に PDF に変換するための方法を提供しています。
IronPDF for Java を使用する利点は何ですか?
IronPDF for Java は、HTML から PDF への変換、画像変換、カスタム用紙設定、Web サイトのログインやカスタム HTTP ヘッダーをサポートする機能を提供しています。使いやすさを考慮して設計されており、商業サポートを提供しています。
IronPDF は画像を PDF に変換できますか?
はい、IronPDF は画像を PDF に変換できます。この機能により、さまざまな画像フォーマットからの PDF ドキュメントを最小限の労力で生成できます。
Apache PDFBox は IronPDF と機能面でどのように異なりますか?
Apache PDFBox は、テキスト抽出、フォーム処理、デジタル署名には優れていますが、直接的な HTML から PDF への変換はできません。しかし、IronPDF は直接的な HTML や URL から PDF への変換を提供し、高度な PDF 操作機能を備えています。
IronPDF は企業での使用に適していますか?
はい、IronPDF は商業サポート、堅牢な機能、ライセンスオプションがあるため、企業での使用に非常に適しています。ビジネスアプリケーションに理想的です。
HTML を PDF に変換する際によくある問題は何ですか?
一般的な問題には、複雑な HTML/CSS の不正確なレンダリング、欠落した画像、誤ったページレイアウトが含まれます。IronPDF は、カスタム用紙設定や画像サポートなどの機能でこれらの問題に対処します。
IronPDF を Java プロジェクトに統合するにはどうすればよいですか?
Maven から JAR ファイルをダウンロードするか、プロジェクトの pom.xml ファイルに依存関係として追加することで、IronPDF を Java プロジェクトに統合できます。
Apache PDFBox は何に使われますか?
Apache PDFBox は、PDF ドキュメントの作成、編集、操作に使用されます。テキスト抽出、ドキュメントの分割と結合、フォームの記入、デジタル署名をサポートします。
IronPDF にはライセンスのコストがかかりますか?
IronPDF は無料のトライアルを提供し、基本的な開発には無料ですが、商業的な利用にはライセンスが必要です。さまざまなニーズに応じたライセンスオプションが利用可能です。
なぜ誰かが IronPDF よりも Apache PDFBox を選ぶのですか?
HTML から PDF への変換を必要としない場合、個人用または非商業用として無料のオープンソースソリューションを必要としている場合、Apache PDFBox が選ばれることがあります。