
PythonでのBeautifulSoupによるWebスクレイピング
Python 開発者は、Beautiful Soup と IronPDF の組み合わせのおかげで、動的な PDF を作成し、ウェブスクレイピングを合理化できるようになりました。 開発者は HTML や XML ファイルの解析に優れたことで知られている Beautiful Soup を使用して、Web ソースからすべてのデータを簡単かつ正確に抽出できます。 一方、IronPDF はプログラムで PDF ドキュメントを生成するために使用できる滑らかな統合と堅実な機能を備えた強力なツールです。
これら 2 つの強力なツールを組み合わせることで、開発者は請求書の作成、コンテンツのアーカイブ、レポートの作成などのプロセスを比類のない効率で自動化できます。 この入門的な調査では、Beautiful Soup Python ライブラリと IronPDF の詳細について説明し、それぞれの利点と、それを組み合わせた場合の革新的な可能性を強調します。 Python 開発者がウェブスクレーパーと PDF 作成を完全に活用して待ち構えている機会を探ってください。
HTML/XML 解析
Beautiful Soup は HTML タグや XML ドキュメントを解析し、それを操作可能な解析ツリーに変換するのが非常に得意です。 誤った HTML 要素にうまく対応し、開発者は不完全なデータを解析の問題を心配せずに扱うことができます。
HTMLページ上の特定の項目を見つける
Beautiful Soup の使いやすいナビゲーション技術により、HTML ページ上の特定のアイテムを簡単に見つけることができます。 開発者はselectなどの技術を使用して、ツリー構造をナビゲートし、タグ、属性、またはCSSセレクタに基づいて要素を正確にターゲットすることができます。
タグの特性と内容にアクセスする方法
Beautiful Soup は、解析ツリー内に見つかった要素の特性と内容を取得するための簡単な方法を提供します。 開発者はタグにリンクされたカスタム属性だけでなく、idなどの属性も取得できます。 追加処理のために、要素の内部 HTML 要素やテキスト コンテンツにもアクセスできます。
検索とフィルタリング
Beautiful Soup には、さまざまな基準に従ってコンポーネントを見つけることができる強力な検索およびフィルタリング機能があります。 より複雑な一致パターンには、正規表現を使用することもできます。 特定のタグを検索し、特性や CSS クラスに基づいて項目をフィルタリングできます。 ウェブページを解析用に取得するためにrequestsライブラリを使用してこれをさらに合理化できます。 HTML/XML ドキュメントから特定のデータを抽出する能力は、この柔軟性によって強化されます。
解析ツリーをナビゲートする
ドキュメント構造内で、開発者は解析ツリーで上下左右に移動できます。 Beautiful Soup により、親、兄弟、子要素へのアクセスが可能になり、ドキュメント階層を詳細に確認できます。
データ抽出
Beautiful Soup の基本的な機能は、HTML や XML テキストからデータを抽出する機能です。 開発者は、Web ページからテキスト、リンク、写真、テーブル、およびその他のコンテンツ項目を簡単に抽出できます。 ナビゲーション、フィルタリング、およびトラバーサル アルゴリズムを統合することにより、複雑なドキュメントから特定のデータ ポイントやコンテンツの全体を抽出することができます。
エンコーディングとエンティティの処理
Beautiful Soup は文字エンコーディングや HTML Web エンティティを自動的に処理し、エンコーディングの問題や特殊文字にかかわらず、テキストデータが正確に処理されるようにします。 この機能により、エンティティのデコードや手動のエンコーディング コンバージョンを必要とせずに、さまざまなソースからの Web 素材を扱うのが容易になります。
解析ツリーの修正
Beautiful Soup は抽出を促進するだけでなく、開発者が解析ツリーを動的に変更できるようにします。 必要に応じて、ドキュメントの構造を再編成したり、タグや属性を追加したり削除したり変更したり、新しい要素を追加したりすることができます。 この機能により、データクリーニング、コンテンツ拡張、構造変更などのオペレーションをドキュメント内で実行できるようになります。
Python 用の Beautiful Soup を作成および設定する
パーサーの選択
Beautiful Soup は、HTML や XML ドキュメントを処理するためにパーサーを必要とします。 デフォルトでPythonの組み込みhtml.parserを利用します。 特定の文書に対してより効率的または互換性のあるパーサーを使用するために、html5libのような異なるパーサーを指定することができます。 BeautifulSoupオブジェクトを構築する過程で、パーサーを提供できます。
from bs4 import BeautifulSoup
# Specify the parser (e.g., 'lxml' or 'html5lib')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'lxml')from bs4 import BeautifulSoup
# Specify the parser (e.g., 'lxml' or 'html5lib')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'lxml')解析の選択肢の設定
Beautiful Soup は解析の動作を変更するためのいくつかの選択肢を提供します。 たとえば、HTML エンティティを Unicode 文字に変換する機能をオフにしたり、より厳しい解析オプションをアクティブにすることができます。 BeautifulSoupオブジェクトが作成されるとき、これらの設定は引数として提供されます。 これはエンティティ変換をオフにする方法の例です。
from bs4 import BeautifulSoup
# Disable entity conversion
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', convert_entities=False)from bs4 import BeautifulSoup
# Disable entity conversion
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', convert_entities=False)エンコーディングの検出
Beautiful Soup はドキュメントのエンコーディングを自動的に検出しようとします。 しかし、特にコンテンツが不明瞭であったり、エンコーディングの問題がある場合には、エンコーディングを明示的に指定する必要があるかもしれません。 BeautifulSoupオブジェクトを作成する際、エンコーディングを定義するオプションがあります。
from bs4 import BeautifulSoup
# Specify the encoding (e.g., 'utf-8')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')from bs4 import BeautifulSoup
# Specify the encoding (e.g., 'utf-8')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')出力フォーマットの設定
デフォルトでは、Beautiful Soup は解析されたコンテンツを読みやすくするために改行とインデントを追加します。 一方、formatterオプションを与えて出力のフォーマットを変更できます。 例として、きれいな印刷をオフにするには次のようにします。
from bs4 import BeautifulSoup
# Disable pretty-printing
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', formatter=None)from bs4 import BeautifulSoup
# Disable pretty-printing
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', formatter=None)Tagサブクラス
どのクラスをBeautiful SoupがTagオブジェクトに使用するかを変更できます。 これにより、Beautiful Soup の機能を拡張したり、他のライブラリと統合したりすることができます。 Tagのサブクラスをパラメーターとして渡すことができます。
開始方法
IronPDF とは何ですか?
C#、VB.NET、その他の .NET 言語でプログラム的に PDF ドキュメントを生成、編集、修正するために、IronPDF は強力な .NET ライブラリです。 動的に高品質な PDF を作成するための豊富な機能セットを提供するため、多くのアプリケーションで人気のあるオプションです。
IronPDF の機能
- PDF 生成: IronPDFを使用すると、開発者は HTML タグ、テキスト、画像、その他のファイル形式を PDF に変換したり、PDF ドキュメントの作成を新たに開始したりできます。 動的にレポート、請求書、領収書などのドキュメントを作成するために、この機能は非常に役立ちます。
- HTML から PDF への変換: IronPDF を使用すると、開発者はJavaScriptや CSS スタイルを含む HTML 構造を PDF ドキュメントに簡単に変換できます。 これにより、HTML テンプレート、Web ページ、動的に作成された素材から PDF を作成できます。
- PDF ドキュメントの編集と操作: IronPDF は、既存の PDF ドキュメントに対して幅広い編集および操作機能を提供します。 開発者は複数の PDF ファイルを結合して別々のドキュメントに分割したり、ページを抽出したり、ブックマーク、注釈、透かしを追加したりすることで、PDF を要求に応じて変更できます。
インストール
まず、IronPDF と Beautiful Soup をインストールする必要があります。これには Python のパッケージマネージャーである Pip を使用できます。
pip install beautifulsoup4
pip install ironpdfpip install beautifulsoup4
pip install ironpdfライブラリをインポートする
その後、必要なライブラリを使用して Python スクリプトをインポートします。
from bs4 import BeautifulSoup
from ironpdf import IronPdffrom bs4 import BeautifulSoup
from ironpdf import IronPdfBeautiful Soup を使用したウェブスクレイピング
Beautiful Soup を使用して Web サイトから情報を抽出します。ある Web ページの記事のタイトルとコンテンツを取得したいと想像してください。
# HTML content of the article
html_content = """
<html>
<head>
<title>Hello</title>
</head>
<body>
<h1>IronPDF</h1>
<p>This is a sample content of the article.</p>
</body>
</html>
"""
# Create a BeautifulSoup object
soup = BeautifulSoup(html_content, 'html.parser')
# Extract title and content
title = soup.find('title').text
content = soup.find('h1').text + soup.find('p').text
print('Title:', title)
print('Content:', content)# HTML content of the article
html_content = """
<html>
<head>
<title>Hello</title>
</head>
<body>
<h1>IronPDF</h1>
<p>This is a sample content of the article.</p>
</body>
</html>
"""
# Create a BeautifulSoup object
soup = BeautifulSoup(html_content, 'html.parser')
# Extract title and content
title = soup.find('title').text
content = soup.find('h1').text + soup.find('p').text
print('Title:', title)
print('Content:', content)IronPDF で PDF を生成する
次に 、抽出されたデータを使用して PDF ドキュメントを作成するために IronPDF を利用します。
from ironpdf import IronPdf, ChromePdfRenderer
# Initialize IronPDF
# Create a new PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(
"<html><head><title>{}</title></head><body><h1>{}</h1><p>{}</p></body></html>".format(title, title, content)
)
# Save the PDF document to a file
pdf.SaveAs("sample_article.pdf")from ironpdf import IronPdf, ChromePdfRenderer
# Initialize IronPDF
# Create a new PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(
"<html><head><title>{}</title></head><body><h1>{}</h1><p>{}</p></body></html>".format(title, title, content)
)
# Save the PDF document to a file
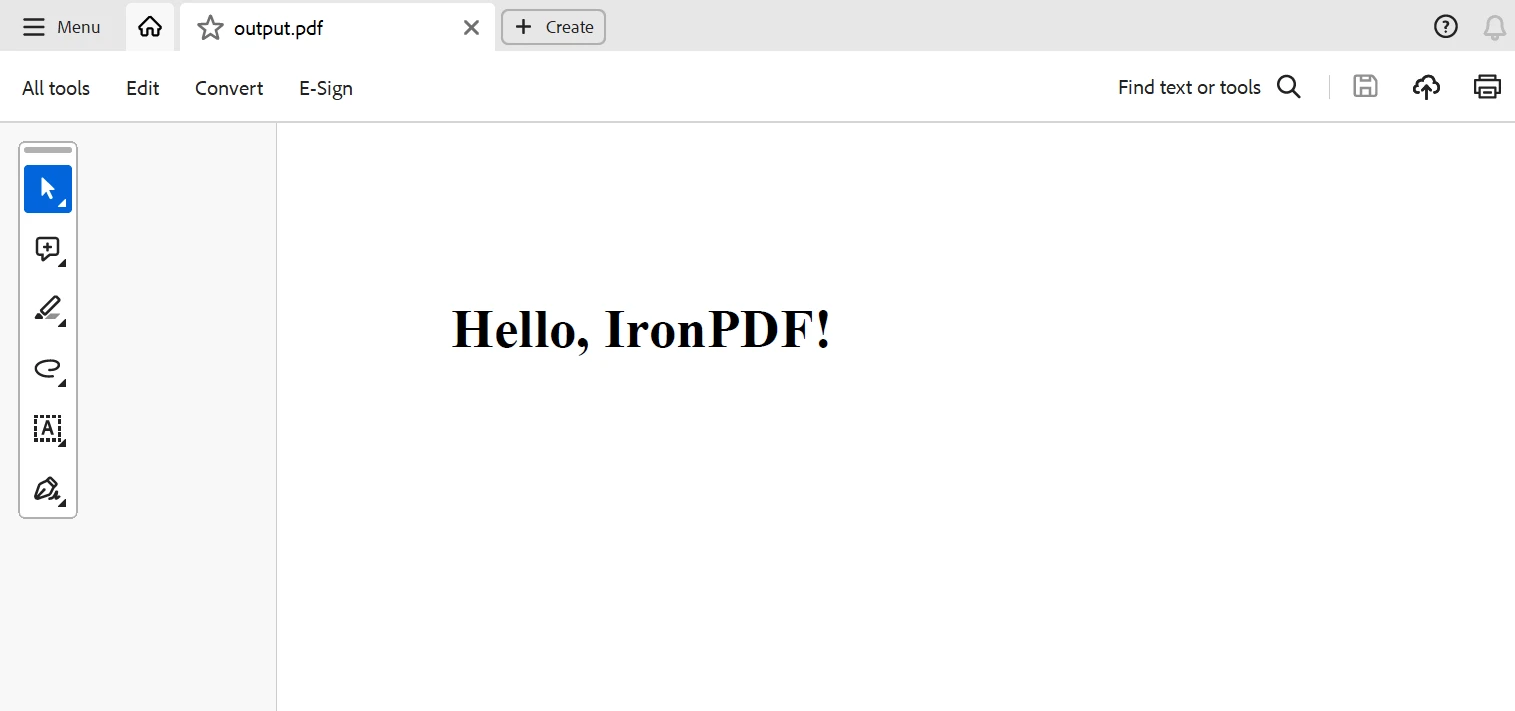
pdf.SaveAs("sample_article.pdf")このスクリプトはサンプル記事のタイトルとテキストを取得し、HTMLデータをsample_article.pdfという名前のPDFファイルとして保存します。このファイルは現在のディレクトリに保存されます。
結論
結論として、データ抽出とドキュメント作成ワークフローを最適化しようとしている開発者にとって、Beautiful Soup Python と IronPDF は強力な組み合わせです。 IronPDF の強力な機能によりプロフェッショナルグレードの PDF ドキュメントを動的に生成することが可能であり、Beautiful Soup の簡単な解析スキルにより Web ソースから有用なデータを抽出できます。
これらの 2 つのライブラリが組み合わさることで、開発者は請求書、レポート、Web スクレイピングの作成などさまざまな操作を自動化するために必要なリソースを手に入れることができます。 Beautiful Soup と IronPDF のコラボレーションにより、複雑な HTML コードからデータを抽出したり、カスタマイズされた PDF 出版物を即座に作成したりするかどうかにかかわらず、開発者は迅速かつ効果的に目標を達成できます。
IronPDF は、バンドルで購入すると手頃な価格であり、ライセンスは生涯有効です。 パッケージは$799で、複数のシステムに対する一度限りの支払いのため、優れた価値を提供します。 ライセンス保有者は、24 時間体制のオンラインエンジニアリングサポートにアクセスできます。 料金の詳細については、Web サイトをご覧ください。Iron Software のサービスについて詳しくはこちらの Web サイトをご覧ください。
















