
Scraping web avec BeautifulSoup en Python
Les développeurs Python peuvent désormais créer des PDF dynamiques et rationaliser le web scraping grâce à la combinaison de Beautiful Soup et IronPDF. Les développeurs peuvent facilement et précisément extraire toutes les données des sources web avec Beautiful Soup, qui est bien connu pour son habileté à analyser les fichiers HTML et XML. IronPDF, quant à lui, est un outil puissant avec une intégration fluide et des capacités solides qui peuvent être utilisées pour générer des documents PDF par programmation.
Ensemble, ces deux outils puissants permettent aux développeurs d'automatiser des processus tels que la création de factures, l'archivage de contenu et la génération de rapports avec une efficacité inégalée. Nous explorerons les nuances de la bibliothèque Python Beautiful Soup et d'IronPDF dans cette analyse introductive, en soulignant à la fois leurs mérites séparés et leur potentiel révolutionnaire lorsqu'ils sont combinés. Accompagnons-nous pour explorer les opportunités qui attendent les développeurs Python en utilisant pleinement l'extracteur web et la création de PDF.
Analyse HTML/XML
Beautiful Soup est très doué pour analyser les balises HTML et les documents XML, les transformant en arbres d'analyse manipulables qui peuvent être explorés. Il prend en charge doucement les éléments HTML incorrects, de sorte que les développeurs peuvent traiter les données incomplètes sans se soucier des problèmes d'analyse.
Recherche d'éléments spécifiques sur la page HTML
Les techniques de navigation conviviales de Beautiful Soup facilitent la recherche d'éléments spécifiques sur la page HTML. En utilisant des techniques comme search, find_all et select, les développeurs peuvent naviguer dans la structure arborescente et cibler précisément les éléments en fonction des balises, des attributs ou des sélecteurs CSS.
Accéder aux caractéristiques et aux contenus des balises
Beautiful Soup fournit des méthodes faciles pour récupérer les caractéristiques et le contenu d'un élément une fois qu'il a été localisé à l'intérieur de l'arbre d'analyse. Les développeurs peuvent obtenir n'importe quel attribut personnalisé lié à la balise, ainsi que l'attribut href et d'autres tels que class et id. Pour un traitement supplémentaire, ils peuvent également accéder à l'élément HTML interne ou au contenu textuel de l'élément.
Recherche et filtrage
Beautiful Soup dispose de puissantes fonctionnalités de recherche et de filtrage qui permettent aux développeurs de localiser les composants en fonction de différents critères. Ils peuvent également utiliser des expressions régulières pour des motifs de correspondance plus complexes. Ils peuvent rechercher des balises particulières et filtrer les éléments en fonction des caractéristiques ou des classes CSS. Vous pouvez encore simplifier cela avec la bibliothèque requests pour récupérer des pages Web à analyser. La capacité d'extraire des données spécifiques des documents HTML/XML est facilitée par cette flexibilité.
Les développeurs peuvent extraire facilement le texte, les liens, les photos, les tableaux et d'autres contenus depuis les pages web.
À l'intérieur de la structure du document, les développeurs peuvent se déplacer vers le haut, le bas et latéralement dans l'arbre d'analyse. L'accès aux éléments parents, frères et enfants est rendu possible par Beautiful Soup, ce qui facilite l'exploration détaillée de la hiérarchie du document.
Extraction de données
Une fonction fondamentale de Beautiful Soup est la capacité d'extraire des données de textes HTML et XML. Les développeurs peuvent facilement extraire des pages web le texte, les liens, les photos, les tableaux et d'autres éléments de contenu. À partir de documents complexes, ils peuvent extraire certains points de données ou des blocs de contenu entiers en intégrant des algorithmes de navigation, de filtrage et de parcours.
Prise en charge des encodages et des entités
Beautiful Soup gère automatiquement les encodages de caractères et les entités web HTML, s'assurant que les données textuelles sont traitées avec précision malgré les problèmes d'encodage ou les caractères spéciaux. Cette fonctionnalité facilite le travail avec le matériel web provenant de diverses sources en supprimant la nécessité de décoder les entités ou de convertir manuellement les encodages.
Modification de l'arbre d'analyse
Beautiful Soup ne facilite pas seulement l'extraction, il permet également aux développeurs de modifier dynamiquement l'arbre d'analyse. Au besoin, ils peuvent restructurer la structure du document, ajouter, supprimer ou modifier des balises et des attributs, ou ajouter de nouveaux éléments. Cette fonctionnalité permet d'effectuer des opérations au sein du document, comme le nettoyage de données, l'enrichissement de contenu et la modification de structure.
Créer et configurer Beautiful Soup pour Python
Choisir un analyseur
Pour traiter les documents HTML ou XML, Beautiful Soup a besoin d'un analyseur. Il utilise par défaut la fonction intégrée de Python html.parser. Pour une meilleure efficacité ou une plus grande compatibilité avec des documents spécifiques, vous pouvez spécifier différents analyseurs comme lxml ou html5lib. Lors de la construction d'un objet BeautifulSoup, vous pouvez fournir l'analyseur syntaxique :
from bs4 import BeautifulSoup
# Specify the parser (e.g., 'lxml' or 'html5lib')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'lxml')from bs4 import BeautifulSoup
# Specify the parser (e.g., 'lxml' or 'html5lib')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'lxml')Configurer les options d'analyse
Beautiful Soup offre quelques choix pour modifier le fonctionnement de l'analyse. Vous pouvez, par exemple, désactiver les fonctions qui transforment les entités HTML en caractères Unicode ou activer une option d'analyse plus stricte. Lorsqu'un objet BeautifulSoup est créé, ces paramètres sont fournis en tant qu'arguments. Voici un exemple de la façon de désactiver la conversion d'entités :
from bs4 import BeautifulSoup
# Disable entity conversion
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', convert_entities=False)from bs4 import BeautifulSoup
# Disable entity conversion
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', convert_entities=False)Détection d'encodage
Beautiful Soup fait un effort automatique pour déterminer l'encodage du document. Mais parfois, surtout lorsque le contenu est flou ou a des problèmes d'encodage, vous pourriez devoir préciser l'encodage explicitement. Lors de la création de l'objet BeautifulSoup, vous avez la possibilité de définir l'encodage :
from bs4 import BeautifulSoup
# Specify the encoding (e.g., 'utf-8')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')from bs4 import BeautifulSoup
# Specify the encoding (e.g., 'utf-8')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')Formatage de la sortie
Par défaut, Beautiful Soup ajoute des sauts de ligne et des indentations au contenu analysé pour le rendre plus facile à lire. En revanche, lors de la construction de l'objet BeautifulSoup, vous pouvez utiliser l'option formatter pour modifier la mise en forme de la sortie. À titre d'illustration, pour désactiver l'édition soignée :
from bs4 import BeautifulSoup
# Disable pretty-printing
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', formatter=None)from bs4 import BeautifulSoup
# Disable pretty-printing
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', formatter=None)Sous-classes NavigableString et Tag
Vous pouvez modifier les classes utilisées par Beautiful Soup pour les objets NavigableString et Tag. Cela pourrait aider à étendre les capacités de Beautiful Soup ou à l'intégrer avec d'autres bibliothèques. Lors de la construction de l'objet BeautifulSoup, vous pouvez passer des sous-classes de NavigableString et Tag comme paramètres.
Commencer
Qu'est-ce qu'IronPDF ?
Pour produire, éditer et modifier des documents PDF par programmation en C#, VB.NET, et d'autres langages .NET, IronPDF est une puissante bibliothèque .NET. C'est une option populaire pour de nombreuses applications car elle offre aux développeurs un ensemble de fonctionnalités étendu pour créer dynamiquement des PDF de haute qualité.
Caractéristiques de IronPDF
- Génération de PDF : Avec IronPDF, les développeurs peuvent transformer une balise HTML, du texte, des images et d'autres formats de fichiers en PDF ou créer des documents PDF à partir de zéro. Pour créer dynamiquement des rapports, des factures, des reçus et d'autres documents, cette capacité est très utile.
- Conversion de HTML en PDF : IronPDF permet aux développeurs de convertir facilement la structure HTML (y compris les styles JavaScript et CSS) en documents PDF. Cela permet de créer des PDFs à partir de modèles HTML, de pages web, et de matériel dynamique.
- Édition et manipulation de documents PDF : IronPDF offre un large éventail de fonctionnalités d'édition et de manipulation pour les documents PDF préexistants. Pour modifier les PDFs à leurs spécifications, les développeurs peuvent combiner plusieurs fichiers PDF, les diviser en documents distincts, extraire des pages, et ajouter des signets, annotations et filigranes, entre autres choses.
Installation
IronPDF et Beautiful Soup doivent d'abord être installés. PiP, le Package Manager pour Python, peut être utilisé pour cela.
pip install beautifulsoup4
pip install ironpdfpip install beautifulsoup4
pip install ironpdfImporter des bibliothèques
Ensuite, importez votre script Python en utilisant les bibliothèques requises.
from bs4 import BeautifulSoup
from ironpdf import IronPdffrom bs4 import BeautifulSoup
from ironpdf import IronPdfWeb Scraping avec Beautiful Soup
Utilisez Beautiful Soup pour extraire des informations d'un site web. Imaginons que nous souhaitions récupérer le titre et le contenu d'un article depuis une page web.
# HTML content of the article
html_content = """
<html>
<head>
<title>Hello</title>
</head>
<body>
<h1>IronPDF</h1>
<p>This is a sample content of the article.</p>
</body>
</html>
"""
# Create a BeautifulSoup object
soup = BeautifulSoup(html_content, 'html.parser')
# Extract title and content
title = soup.find('title').text
content = soup.find('h1').text + soup.find('p').text
print('Title:', title)
print('Content:', content)# HTML content of the article
html_content = """
<html>
<head>
<title>Hello</title>
</head>
<body>
<h1>IronPDF</h1>
<p>This is a sample content of the article.</p>
</body>
</html>
"""
# Create a BeautifulSoup object
soup = BeautifulSoup(html_content, 'html.parser')
# Extract title and content
title = soup.find('title').text
content = soup.find('h1').text + soup.find('p').text
print('Title:', title)
print('Content:', content)Génération de PDF avec IronPDF
Utilisons maintenant IronPDF pour créer un document PDF avec les données extraites.
from ironpdf import IronPdf, ChromePdfRenderer
# Initialize IronPDF
# Create a new PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(
"<html><head><title>{}</title></head><body><h1>{}</h1><p>{}</p></body></html>".format(title, title, content)
)
# Save the PDF document to a file
pdf.SaveAs("sample_article.pdf")from ironpdf import IronPdf, ChromePdfRenderer
# Initialize IronPDF
# Create a new PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(
"<html><head><title>{}</title></head><body><h1>{}</h1><p>{}</p></body></html>".format(title, title, content)
)
# Save the PDF document to a file
pdf.SaveAs("sample_article.pdf")Ce script prendra le titre et le texte de l'article d'exemple, les extraira et stockera les données HTML sous forme de fichier PDF appelé sample_article.pdf qui sera enregistré dans le répertoire actuel.
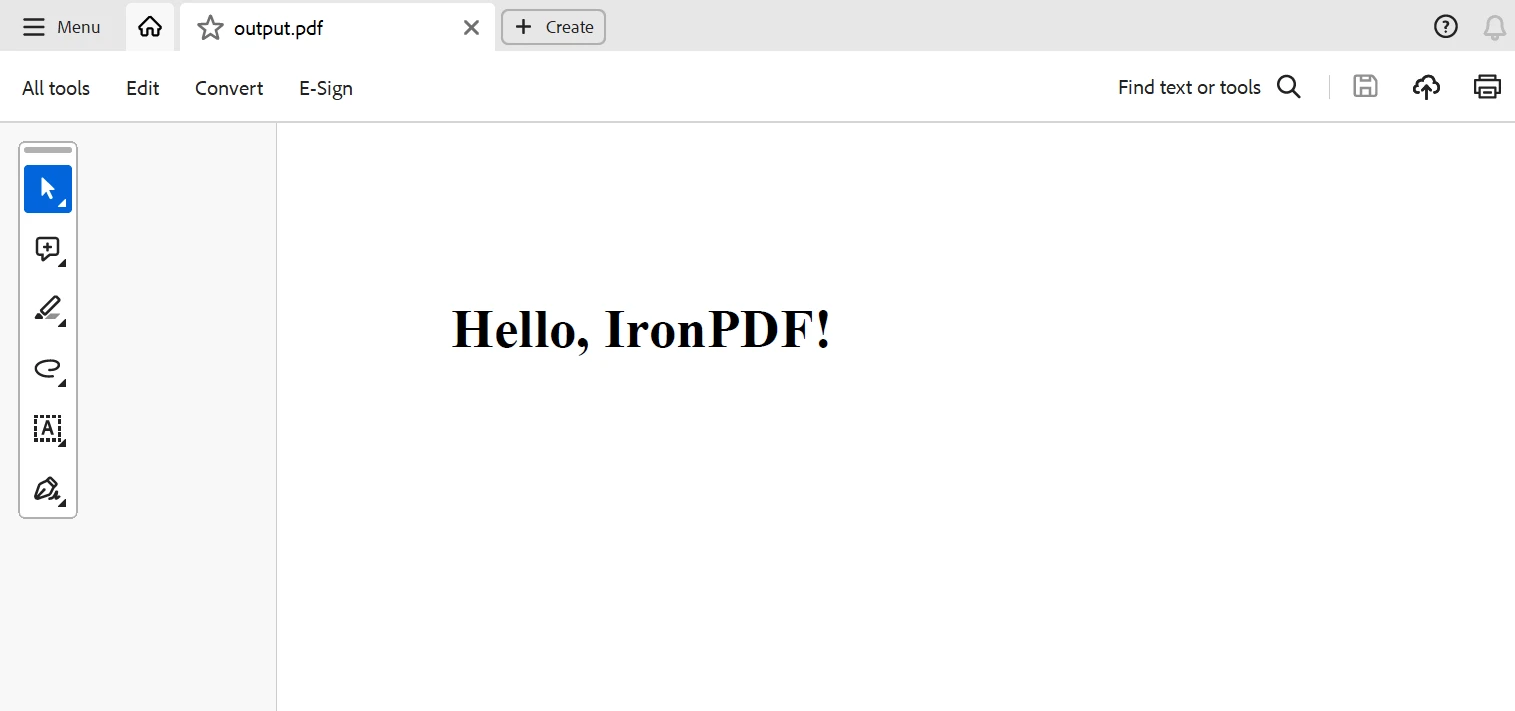
Conclusion
En conclusion, les développeurs cherchant à optimiser leur flux de travail d'extraction de données et de création de documents trouveront une combinaison puissante de Beautiful Soup Python et IronPDF. Les fonctionnalités robustes d'IronPDF permettent la génération dynamique de documents PDF de qualité professionnelle, tandis que les compétences d'analyse facile de Beautiful Soup permettent l'extraction de données utiles de sources Web.
Combinées, ces deux bibliothèques fournissent aux développeurs les ressources nécessaires pour automatiser une variété d'opérations, y compris la création de factures, de rapports et le web scraping. La collaboration entre Beautiful Soup et IronPDF permet aux développeurs d'atteindre leurs objectifs rapidement et efficacement, qu'il s'agisse d'extraire des données de codes HTML complexes ou de créer instantanément des publications PDF personnalisées.
IronPDF est proposé à un prix raisonnable lorsqu'il est acheté en lot et est livré avec une licence à vie. Comme le forfait ne coûte que $999, soit un paiement unique pour plusieurs systèmes, il offre un excellent rapport qualité-prix. Les titulaires de licences peuvent accéder à un support ingénieur en ligne 24h/24 et 7j/7. Pour plus d'informations sur le tarif, veuillez consulter le site Web. Pour en savoir plus sur les offres d'Iron Software, consultez ce site Web.
















