
Web Scraping com BeautifulSoup em Python
Os desenvolvedores Python agora podem criar PDFs dinâmicos e agilizar a extração de dados da web graças à combinação do Beautiful Soup e do IronPDF. Com o Beautiful Soup, conhecido por sua habilidade em analisar arquivos HTML e XML, os desenvolvedores podem extrair com facilidade e precisão todos os dados de fontes da web. O IronPDF, por sua vez, é uma ferramenta poderosa com integração perfeita e recursos sólidos que podem ser usados para gerar documentos PDF programaticamente.
Juntas, essas duas ferramentas poderosas permitem que os desenvolvedores automatizem processos como a criação de faturas, o arquivamento de conteúdo e a geração de relatórios com uma eficiência incomparável. Nesta análise introdutória, vamos explorar as nuances da biblioteca Beautiful Soup for Python e do IronPDF , destacando tanto seus méritos individuais quanto seu potencial revolucionário quando combinados. Venha conosco enquanto exploramos as oportunidades que aguardam os desenvolvedores Python, utilizando plenamente as ferramentas de web scraping e a criação de PDFs.
Análise sintática de HTML/XML
O Beautiful Soup é muito bom em analisar tags HTML e documentos XML, transformando-os em árvores de análise manipuláveis que podem ser exploradas. Ele acomoda elementos HTML incorretos de forma suave, permitindo que os desenvolvedores lidem com dados incompletos sem se preocuparem com problemas de análise.
Como encontrar itens específicos em uma página HTML
As técnicas de navegação intuitivas do Beautiful Soup facilitam a localização de itens específicos na página HTML. Usando técnicas como search, find_all e select, os desenvolvedores podem navegar na estrutura da árvore e direcionar elementos precisamente com base em tags, atributos ou seletores CSS.
Acessando as características e o conteúdo das tags
O Beautiful Soup oferece métodos fáceis para recuperar as características e o conteúdo de um elemento assim que ele for localizado dentro da árvore de análise sintática. Os desenvolvedores podem obter qualquer atributo personalizado vinculado à tag, assim como o atributo href e outros, como class e id. Para processamento adicional, eles também podem acessar o elemento HTML interno ou o conteúdo de texto do elemento.
Pesquisa e filtragem
O Beautiful Soup possui recursos robustos de busca e filtragem que permitem aos desenvolvedores localizar componentes de acordo com diferentes padrões. Eles também podem usar expressões regulares para padrões de correspondência mais complexos. Eles podem pesquisar por tags específicas e filtrar itens com base em características ou classes CSS. Você pode simplificar ainda mais isso com a biblioteca requests para buscar páginas da web para análise. Essa flexibilidade facilita a extração de dados específicos de documentos HTML/XML.
Navegando na árvore de análise sintática
Dentro da estrutura do documento, os desenvolvedores podem navegar para cima, para baixo e para os lados na árvore de análise sintática. O Beautiful Soup possibilita o acesso a elementos pai, irmão e filho, facilitando a exploração detalhada da hierarquia do documento.
Extração de dados
Uma função fundamental do Beautiful Soup é a capacidade de extrair dados de textos HTML e XML. Textos, links, fotos, tabelas e outros elementos de conteúdo podem ser facilmente extraídos de páginas da web por desenvolvedores. A partir de documentos complexos, eles conseguem extrair determinados pontos de dados ou blocos inteiros de conteúdo, integrando algoritmos de navegação, filtragem e busca.
Cuidando de codificações e entidades
O Beautiful Soup cuida automaticamente da codificação de caracteres e das entidades web HTML, garantindo que os dados de texto sejam processados com precisão, apesar de problemas de codificação ou caracteres especiais. Essa funcionalidade facilita o trabalho com material da web proveniente de diversas fontes, eliminando a necessidade de decodificação de entidades ou conversão manual de codificação.
Modificação da árvore de análise sintática
O Beautiful Soup não só facilita a extração, como também permite que os desenvolvedores alterem dinamicamente a árvore de análise sintática. Conforme necessário, eles podem reestruturar a estrutura do documento, adicionar, remover ou alterar tags e atributos, ou adicionar novos elementos. Essa funcionalidade permite realizar operações dentro do documento, como limpeza de dados, enriquecimento de conteúdo e alteração estrutural.
Crie e configure o Beautiful Soup for Python.
Escolhendo um analisador sintático
Para processar documentos HTML ou XML, o Beautiful Soup precisa de um analisador sintático. Ele faz uso do html.parser embutido do Python por padrão. Para melhor eficiência ou mais compatibilidade com documentos específicos, você pode especificar analisadores diferentes, como lxml ou html5lib. No processo de construção de um objeto BeautifulSoup, você pode fornecer o analisador:
from bs4 import BeautifulSoup
# Specify the parser (e.g., 'lxml' or 'html5lib')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'lxml')from bs4 import BeautifulSoup
# Specify the parser (e.g., 'lxml' or 'html5lib')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'lxml')Configurando as opções de análise sintática
O Beautiful Soup oferece algumas opções para alterar o funcionamento da análise sintática. Você pode, por exemplo, desativar funções que transformam entidades HTML em caracteres Unicode ou ativar uma opção de análise mais rigorosa. Quando um objeto BeautifulSoup é criado, essas configurações são fornecidas como argumentos. Esta é uma ilustração de como desativar a conversão de entidades:
from bs4 import BeautifulSoup
# Disable entity conversion
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', convert_entities=False)from bs4 import BeautifulSoup
# Disable entity conversion
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', convert_entities=False)Detecção de codificação
O Beautiful Soup tenta determinar automaticamente a codificação do documento. Mas, ocasionalmente, especialmente quando o conteúdo não está claro ou apresenta problemas de codificação, pode ser necessário especificar a codificação explicitamente. Ao criar o objeto BeautifulSoup, você tem a opção de definir a codificação:
from bs4 import BeautifulSoup
# Specify the encoding (e.g., 'utf-8')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')from bs4 import BeautifulSoup
# Specify the encoding (e.g., 'utf-8')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')Formatação de saída
Por padrão, o Beautiful Soup adiciona quebras de linha e recuos ao conteúdo analisado para facilitar a leitura. Por outro lado, ao construir o objeto BeautifulSoup, você pode dar a opção formatter para alterar o formato de saída. Por exemplo, para desativar a formatação gráfica:
from bs4 import BeautifulSoup
# Disable pretty-printing
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', formatter=None)from bs4 import BeautifulSoup
# Disable pretty-printing
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', formatter=None)Subclasses NavigableString e Tag
Você pode alterar quais classes o Beautiful Soup usa para objetos NavigableString e Tag. Isso poderia ajudar a expandir as capacidades do Beautiful Soup ou integrá-lo com outras bibliotecas. Ao construir o objeto BeautifulSoup, você pode passar subclasses de NavigableString e Tag como parâmetros.
Começando
O que é o IronPDF?
Para produzir, editar e modificar documentos PDF programaticamente em C#, VB .NET e outras linguagens .NET , o IronPDF é uma poderosa biblioteca .NET . É uma opção popular para muitos aplicativos, pois oferece aos desenvolvedores um amplo conjunto de recursos para a criação dinâmica de PDFs de alta qualidade.
Funcionalidades do IronPDF
- Geração de PDF: Com o IronPDF, os desenvolvedores podem transformar tags HTML, textos, imagens e outros formatos de arquivo em PDFs ou começar do zero na criação de documentos PDF. Essa funcionalidade é bastante útil para criar relatórios, faturas, recibos e outros documentos de forma dinâmica.
- Conversão de HTML para PDF: O IronPDF permite que os desenvolvedores convertam facilmente a estrutura HTML — incluindo estilos JavaScript e CSS — em documentos PDF. Isso possibilita a criação de PDFs a partir de modelos HTML, páginas da web e material criado dinamicamente.
- Edição e manipulação de documentos PDF: O IronPDF oferece uma ampla gama de recursos de edição e manipulação para documentos PDF preexistentes. Para alterar PDFs de acordo com suas especificações, os desenvolvedores podem combinar vários arquivos PDF, dividi-los em documentos distintos, extrair páginas e adicionar marcadores, anotações e marcas d'água, entre outras coisas.
Instalação
O IronPDF e o Beautiful Soup precisam ser instalados primeiro. O pip, gerenciador de pacotes do Python, pode ser usado para isso.
pip install beautifulsoup4 ironpdf
Importar bibliotecas
Em seguida, importe seu script Python usando as bibliotecas necessárias.
from bs4 import BeautifulSoup
from ironpdf import IronPdffrom bs4 import BeautifulSoup
from ironpdf import IronPdfWeb Scraping com Beautiful Soup
Utilize o Beautiful Soup para extrair informações de um site. Imagine que desejamos recuperar o título e o conteúdo de um artigo de uma página da web.
# HTML content of the article
html_content = """
<html>
<head>
<title>Hello</title>
</head>
<body>
<h1>IronPDF</h1>
<p>This is a sample content of the article.</p>
</body>
</html>
"""
# Create a BeautifulSoup object
soup = BeautifulSoup(html_content, 'html.parser')
# Extract title and content
title = soup.find('title').text
content = soup.find('h1').text + soup.find('p').text
print('Title:', title)
print('Content:', content)# HTML content of the article
html_content = """
<html>
<head>
<title>Hello</title>
</head>
<body>
<h1>IronPDF</h1>
<p>This is a sample content of the article.</p>
</body>
</html>
"""
# Create a BeautifulSoup object
soup = BeautifulSoup(html_content, 'html.parser')
# Extract title and content
title = soup.find('title').text
content = soup.find('h1').text + soup.find('p').text
print('Title:', title)
print('Content:', content)Gerando PDF com o IronPDF
Vamos agora utilizar o IronPDF para criar um documento PDF com os dados que foram extraídos.
from ironpdf import IronPdf, ChromePdfRenderer
# Initialize IronPDF
# Create a new PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(
"<html><head><title>{}</title></head><body><h1>{}</h1><p>{}</p></body></html>".format(title, title, content)
)
# Save the PDF document to a file
pdf.SaveAs("sample_article.pdf")from ironpdf import IronPdf, ChromePdfRenderer
# Initialize IronPDF
# Create a new PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(
"<html><head><title>{}</title></head><body><h1>{}</h1><p>{}</p></body></html>".format(title, title, content)
)
# Save the PDF document to a file
pdf.SaveAs("sample_article.pdf")Este script irá pegar o título e o texto do artigo de exemplo, raspá-lo e armazenar os dados HTML como um arquivo PDF chamado sample_article.pdf que será salvo no diretório atual.
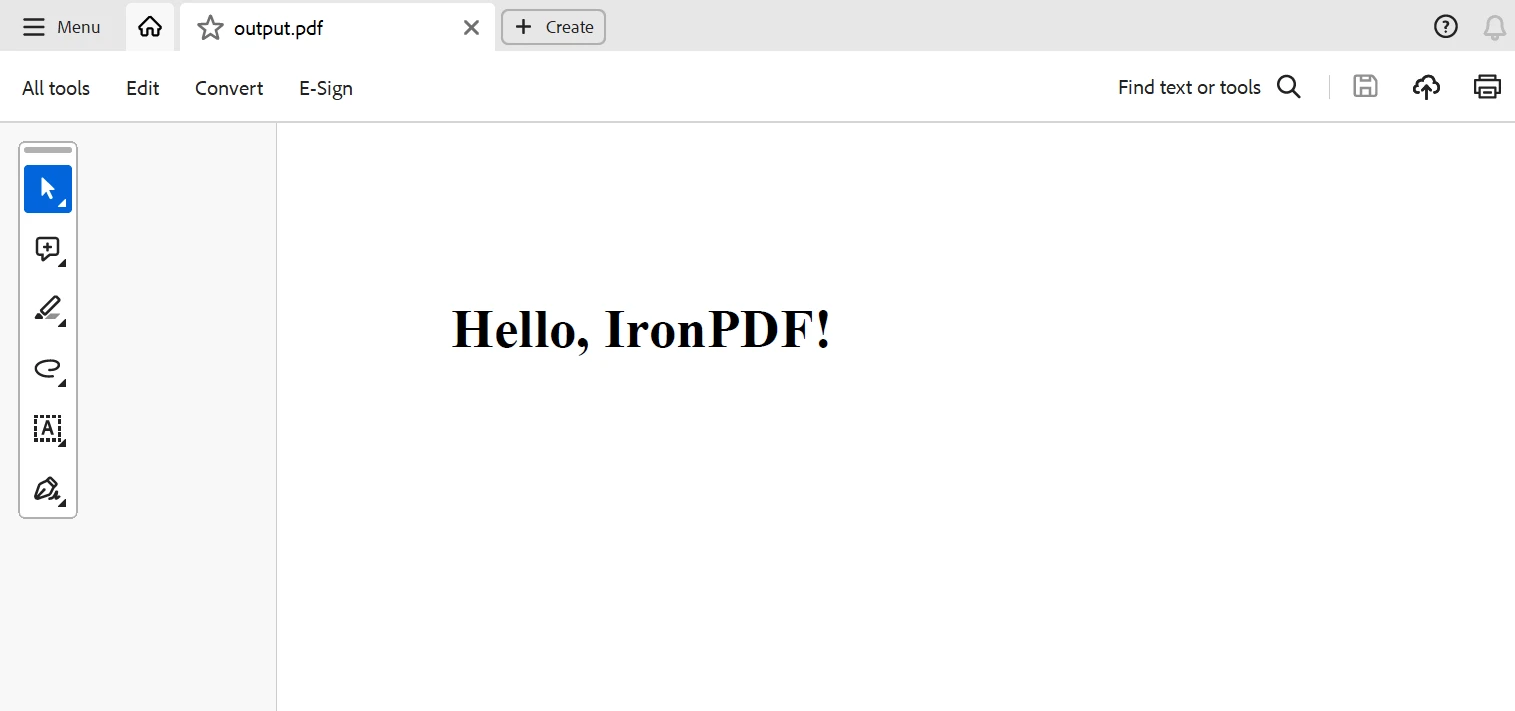
Conclusão
Em resumo, os desenvolvedores que buscam otimizar seu fluxo de trabalho de extração de dados e criação de documentos encontrarão uma poderosa combinação de Beautiful Soup Python e IronPDF. Os recursos robustos do IronPDF permitem a geração dinâmica de documentos PDF de nível profissional, enquanto a facilidade de análise do Beautiful Soup possibilita a extração de dados úteis de fontes da web.
Quando combinadas, essas duas bibliotecas fornecem aos desenvolvedores os recursos necessários para automatizar uma variedade de operações, incluindo a criação de faturas, relatórios e extração de dados da web. A colaboração entre Beautiful Soup e IronPDF permite que os desenvolvedores alcancem seus objetivos de forma rápida e eficaz, seja extraindo dados de códigos HTML complexos ou criando instantaneamente publicações em PDF personalizadas.
O IronPDF tem um preço razoável quando adquirido em pacote e inclui uma licença vitalícia. Como o pacote custa apenas $999, que é um pagamento único para vários sistemas, ele oferece um excelente valor. Os titulares de licença podem acessar suporte técnico online 24 horas por dia, 7 dias por semana. Para obter mais informações sobre a cobrança, visite o site. Para saber mais sobre os produtos e serviços da Iron Software, acesse este site.
















