


Convertendo HTML para PDF em Python
IronPDF oferece aos desenvolvedores Python um caminho direto do HTML para arquivos PDF prontos para produção Notícias: sem ferramentas de design intermediárias, sem motores de layout proprietários, sem pipeline de renderização separado. A classe ChromePdfRenderer da biblioteca usa um motor baseado em Chromium sob o capô, então qualquer HTML que exiba corretamente no Chrome será convertido com precisão para PDF. Este tutorial percorre cada método de conversão suportado — strings HTML, arquivos HTML locais e URLs ao vivo — e depois cobre as opções de renderização que permitem controlar tamanho de página, margens, cabeçalhos, rodapés e mais.
Um tutorial complementar está disponível para converter HTML para PDF em aplicações .NET se você precisar do fluxo de trabalho C# ou VB.NET.
Início Rápido: Converta HTML para PDF em Python
Como converter HTML para PDF em Python

- Instale o IronPDF for Python via pip
- Importe a biblioteca com
from ironpdf import * - Instanciar
ChromePdfRenderer - Chame
RenderHtmlAsPdf,RenderUrlAsPdfouRenderHtmlFileAsPdf - Salve o resultado com
pdf.SaveAs("output.pdf")
Índice
- Como você instala o IronPDF for Python?
- Como você configura o IronPDF antes de converter?
- Como você converte uma string HTML para PDF?
- Como você converte uma URL para PDF?
- Como você converte um arquivo HTML para PDF?
- Como você controla opções de renderização de PDF?
- Como você adiciona cabeçalhos e rodapés personalizados?
- Quais são os próximos passos?
Começando
Como você instala o IronPDF for Python?
IronPDF é distribuído via pip, o gerenciador de pacotes padrão do Python. Execute o seguinte comando em um terminal para instalar a versão mais recente:
pip install ironpdf
Para fixar uma versão específica — útil em pipelines de CI ou em ambientes conteinerizados — anexe o número da versão:
pip install ironpdf==2024.x.x
{i:(IronPDF for Python é construído sobre a biblioteca IronPDF .NET e requer o SDK .NET 6.0 ou posterior. Instale o SDK antes de executar qualquer código IronPDF Python.)}]
Na primeira vez que IronPDF é inicializado, ele baixa um binário do Chromium compatível. Este download leva um momento em uma máquina nova, mas ocorre apenas uma vez por ambiente. Execuções subsequentes iniciam muito mais rápido porque o binário é armazenado em cache localmente.
Guia prático e exemplos de código
Como você configura o IronPDF antes de converter?
Duas tarefas de configuração valem serem completadas antes da primeira chamada de conversão: definir uma chave de licença e — opcionalmente — configurar um local de arquivo de log.
Importando o Pacote
Todo arquivo Python que usa o IronPDF precisa desta única linha de importação. Coloque-a no topo do arquivo:
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/import.pyfrom ironpdf import *
Todas as classes do IronPDF - ChromePdfRenderer, PdfDocument, License, Logger, e o resto - ficam acessíveis através deste importação curinga.
Definindo uma Chave de Licença
Sem uma chave de licença, o IronPDF adiciona uma marca d'água em mosaico a cada PDF gerado. A marca d'água é adequada para desenvolvimento e testes, mas implantações de produção requerem uma chave válida.
PDFs gerados sem uma chave de licença incluem uma marca d'água em mosaico. Visite a página de licenciamento para obter uma chave.
Defina a chave antes de qualquer outra chamada do IronPDF:
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/set-license.pyfrom ironpdf import *
# Set the license key before any PDF operations
License.LicenseKey = "IRONPDF-MYLICENSE-KEY-1EF01"
Inicie um teste gratuito para receber uma chave temporária ou compre uma licença para uso irrestrito em produção.
Configurando Saída de Log
IronPDF grava saída de diagnóstico para um arquivo nomeado Default.log no diretório de trabalho do script. Para redirecionar o registro para um caminho diferente ou capturar mais detalhes para depuração, defina as propriedades Logger antes da primeira conversão:
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/configure-logging.pyfrom ironpdf import *
# Configure logging before running any conversions
Logger.EnableDebugging = True
Logger.LogFilePath = "ironpdf-debug.log"
Logger.LoggingMode = Logger.LoggingModes.All
Logger.LogFilePath deve ser definido antes da primeira chamada de conversão PDF. Alterações feitas posteriormente não têm efeito na sessão atual.Logs detalhados são mais úteis ao diagnosticar por que uma página HTML específica não é renderizada como esperado — eles capturam solicitações de rede, eventos de carregamento de CSS e o tempo de execução do JavaScript.
Como converter uma string HTML em PDF?
Converter uma string HTML na memória é a abordagem mais direta e funciona bem quando o HTML é gerado programaticamente — por exemplo, a partir de um template Jinja2 ou de um relatório orientado a banco de dados.
Conversão Básica de String HTML
Instancie ChromePdfRenderer, passe a string HTML para RenderHtmlAsPdf e chame SaveAs no PdfDocument retornado:
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/html-string-basic.pyfrom ironpdf import *
renderer = ChromePdfRenderer()
# Convert an HTML string to a PDF document
pdf = renderer.RenderHtmlAsPdf("<h1>Hello from IronPDF!</h1><p>Generated in Python.</p>")
pdf.SaveAs("hello.pdf")

RenderHtmlAsPdf processa HTML exatamente como o Chrome faria, incluindo CSS e JavaScript.
O ChromePdfRenderer processa HTML, CSS e JavaScript da mesma forma que um navegador moderno faz. Qualquer conteúdo que seja exibido corretamente no Chrome resultará em um PDF preciso.
String HTML com Ativos Externos
Quando a string HTML referencia ativos locais - folhas de estilo, imagens, scripts - passe o caminho do diretório como segundo argumento para RenderHtmlAsPdf. IronPDF usa este caminho como a URL base ao resolver referências relativas:
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/html-string-assets.pyfrom ironpdf import *
html_content = """
<html>
<head>
<title>Styled Report</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>Monthly Report</h1>
<img src='assets/logo.png' alt='Company logo'>
<p>Data as of Q1 2024.</p>
</body>
</html>
"""
renderer = ChromePdfRenderer()
# The second argument sets the base path for resolving relative asset URLs
pdf = renderer.RenderHtmlAsPdf(html_content, "./")
pdf.SaveAs("styled-report.pdf")

CSS e imagens externas carregam corretamente quando você fornece um caminho base a RenderHtmlAsPdf.
O caminho base pode apontar para qualquer diretório local ou compartilhamento de rede. Ativos em subdiretórios são resolvidos em relação a ele. Para mais padrões envolvendo strings HTML complexas, veja o exemplo de código de string HTML para PDF.
Minha biblioteca favorita desse tipo é o IronPDF. Ele permite a manipulação rápida e eficiente de arquivos PDF. Além disso, possui muitos recursos valiosos, como a exportação para o formato PDF/A e a assinatura digital de documentos PDF.
Com o IronOCR, podemos economizar US$ 40.000 por ano em processamento manual, ao mesmo tempo que aumentamos a produtividade e liberamos recursos para tarefas de alto impacto. Eu o recomendo fortemente.
O IronSuite desempenha um papel crucial nas nossas operações. Estas são ferramentas que aumentam a eficiência no negócio, incluindo a criação de plantas baixas e melhoria na gestão de inventário.
Como converter um URL em PDF?
O método RenderUrlAsPdf busca uma URL ao vivo, espera que a página carregue completamente - incluindo qualquer conteúdo acionado por JavaScript - e converte o resultado renderizado em PDF. Isso o torna adequado para capturar dashboards, relatórios ou qualquer página onde o estado visual final dependa da execução do JavaScript.
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/url-to-pdf.pyfrom ironpdf import *
renderer = ChromePdfRenderer()
# Fetch and convert a live web page to PDF
pdf = renderer.RenderUrlAsPdf("https://en.wikipedia.org/wiki/Portable_Document_Format")
pdf.SaveAs("wikipedia-pdf.pdf")
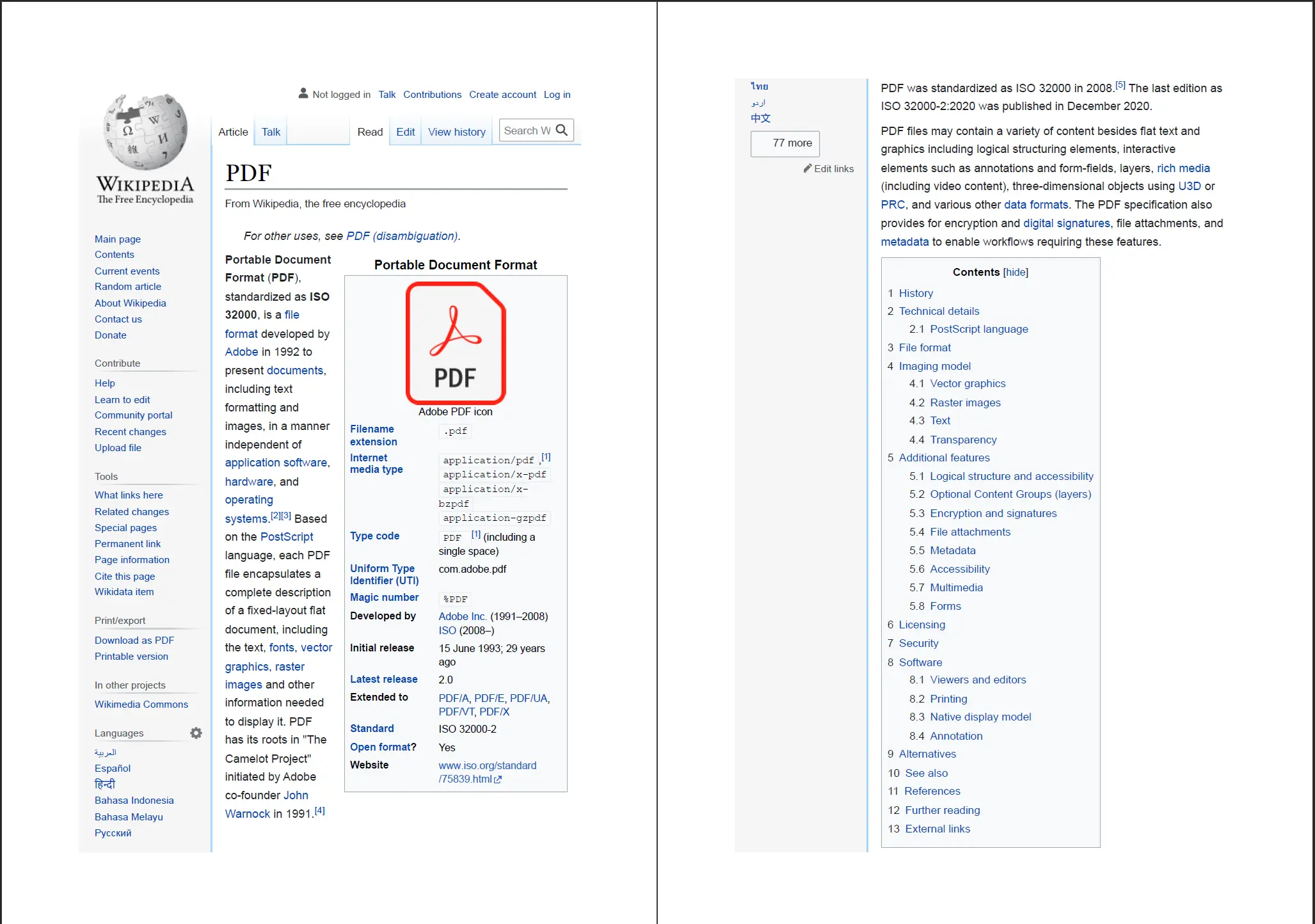
IronPDF busca a URL ao vivo e renderiza a página completa — JavaScript incluído — antes de gerar o PDF.
ChromePdfRenderer antes de chamar RenderUrlAsPdf. Veja o guia de credenciais de login HTTP para detalhes.Quando a página alvo carrega conteúdo assíncrono, o IronPDF espera que o motor de renderização Chromium sinalize que o documento está completamente pintado. Para páginas com JavaScript pesado ou solicitações de rede atrasadas, considere ajustar as propriedades de WaitFor em ChromePdfRenderOptions (coberto na seção de opções de renderização abaixo). O exemplo de código de URL para PDF mostra padrões de configuração adicionais.
Como você converte um arquivo HTML para PDF?
RenderHtmlFileAsPdf aceita um caminho para um arquivo HTML local e o converte diretamente. Caminhos relativos dentro do HTML — para arquivos CSS, imagens ou JavaScript — são resolvidos automaticamente em relação ao próprio diretório do arquivo HTML, portanto, nenhum argumento de caminho base é necessário.
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/html-file-to-pdf.pyfrom ironpdf import *
renderer = ChromePdfRenderer()
# Convert a local HTML file (and its linked CSS/JS) to PDF
pdf = renderer.RenderHtmlFileAsPdf("invoices/TestInvoice1.html")
pdf.SaveAs("invoice.pdf")
Este método é particularmente útil para geração de documentos do lado do servidor onde um template HTML já foi escrito para o disco — um padrão comum ao usar Django ou Flask para renderizar templates Jinja2 para arquivos antes de convertê-los para PDF para download.
IronPDF resolve quaisquer tags <link>, <script> e <img> em relação à localização do arquivo HTML, para que folhas de estilo vinculadas, fontes embutidas e imagens apareçam no PDF exatamente como fazem em um navegador. O processo espelha como RenderHtmlAsPdf lida com ativos inline, com a diferença de que nenhum caminho de base explícito precisa ser fornecido.
Como você controla opções de renderização de PDF?
ChromePdfRenderOptions é o objeto de configuração passado para ChromePdfRenderer (ou diretamente para qualquer um dos métodos de renderização) para controlar layout de página, margens, tamanho do papel e outras características de saída. Definir opções antes da conversão é a maneira padrão de personalizar a saída do PDF.
Tamanho e Orientação do Papel
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/render-options-paper.pyfrom ironpdf import *
renderer = ChromePdfRenderer()
# Configure page layout before rendering
renderer.RenderingOptions.PaperSize = PdfPaperSize.A4
renderer.RenderingOptions.PaperOrientation = PdfPaperOrientation.Landscape
renderer.RenderingOptions.MarginTop = 20
renderer.RenderingOptions.MarginBottom = 20
renderer.RenderingOptions.MarginLeft = 15
renderer.RenderingOptions.MarginRight = 15
pdf = renderer.RenderHtmlAsPdf("<h1>Landscape Report</h1><p>Content here.</p>")
pdf.SaveAs("landscape-a4.pdf")
As margens são expressas em milímetros. PdfPaperSize suporta todos os tamanhos padrão ISO - A0 até A10, Carta, Legal, Tabloid - bem como Custom para dimensões arbitrárias definidas por CustomPaperWidth e CustomPaperHeight.
Dimensões Customizadas do Papel
Quando os tamanhos de papel padrão não correspondem ao requisito de saída — por exemplo, um formato de impressora de recibo ou etiqueta — defina a largura e a altura explicitamente:
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/render-options-custom-size.pyfrom ironpdf import *
renderer = ChromePdfRenderer()
# Set a custom paper size (in millimetres)
renderer.RenderingOptions.PaperSize = PdfPaperSize.Custom
renderer.RenderingOptions.CustomPaperWidth = 80 # 80 mm receipt roll width
renderer.RenderingOptions.CustomPaperHeight = 200
pdf = renderer.RenderHtmlAsPdf("<h2>Receipt</h2><p>Total: $12.50</p>")
pdf.SaveAs("receipt.pdf")
Habilitando Execução de JavaScript
Por padrão, o IronPDF executa JavaScript durante a renderização. Se uma página depende do JavaScript para gerar conteúdo visível — gráficos, tabelas de dados, valores de formulário dinâmicos — esse comportamento significa que o PDF renderizado reflete o estado final do DOM. Para desabilitar o JavaScript para páginas onde ele não é necessário:
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/render-options-javascript.pyfrom ironpdf import *
renderer = ChromePdfRenderer()
# Disable JavaScript for static HTML pages
renderer.RenderingOptions.EnableJavaScript = False
pdf = renderer.RenderHtmlAsPdf("<p>Static content only.</p>")
pdf.SaveAs("static.pdf")
Desabilitar o JavaScript reduz o tempo de renderização para documentos HTML simples e estáticos.
Para mais detalhes de configuração de renderização, veja configurações de geração de PDF e o exemplo de tamanho de papel personalizado.
Como você adiciona cabeçalhos e rodapés personalizados?
Cabeçalhos e rodapés no IronPDF são aplicados através de objetos HtmlHeaderFooter ou TextHeaderFooter anexados ao RenderingOptions do renderizador. HtmlHeaderFooter oferece total controle HTML e CSS - ideal para cabeçalhos de carta com logotipos. TextHeaderFooter é mais simples e cobre a maioria dos requisitos baseados em texto, incluindo números de página dinâmicos.
Cabeçalho e Rodapé Baseados em Texto
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/headers-footers-text.pyfrom ironpdf import *
renderer = ChromePdfRenderer()
# Add a text header with the document title
renderer.RenderingOptions.TextHeader = TextHeaderFooter()
renderer.RenderingOptions.TextHeader.CenterText = "Quarterly Report — Q1 2024"
renderer.RenderingOptions.TextHeader.DrawDividerLine = True
renderer.RenderingOptions.TextHeader.FontSize = 10
# Add a footer with page numbers
renderer.RenderingOptions.TextFooter = TextHeaderFooter()
renderer.RenderingOptions.TextFooter.RightText = "Page {page} of {total-pages}"
renderer.RenderingOptions.TextFooter.FontSize = 9
renderer.RenderingOptions.TextFooter.DrawDividerLine = True
html = "<h1>Executive Summary</h1><p>Revenue increased 12% year-over-year.</p>"
pdf = renderer.RenderHtmlAsPdf(html)
pdf.SaveAs("report-with-footer.pdf")
Os placeholders {page} e {total-pages} são substituídos durante a renderização com os valores corretos. Outros placeholders disponíveis incluem {date}, {time} e {url}.
Cabeçalho baseado em HTML com logotipo
Quando um cabeçalho personalizado é necessário - um logotipo de empresa, uma faixa de cor ou um bloco de endereço formatado - use HtmlHeaderFooter em vez:
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/headers-footers-html.pyfrom ironpdf import *
renderer = ChromePdfRenderer()
header_html = """
<div style="font-family: Arial, sans-serif; border-bottom: 2px solid #003366; padding: 8px 0;">
<img src='assets/logo.png' style='height: 40px; float: left;' alt='Company logo'>
<span style='float: right; font-size: 11px; color: #666;'>Confidential</span>
<div style='clear:both;'></div>
</div>
"""
renderer.RenderingOptions.HtmlHeader = HtmlHeaderFooter()
renderer.RenderingOptions.HtmlHeader.HtmlFragment = header_html
renderer.RenderingOptions.HtmlHeader.BaseUrl = "./"
html_body = "<h1>Project Status Update</h1><p>All milestones on track.</p>"
pdf = renderer.RenderHtmlAsPdf(html_body, "./")
pdf.SaveAs("branded-report.pdf")
BaseUrl em HtmlHeaderFooter para o mesmo caminho de base usado para o corpo do documento. Isso garante que imagens e folhas de estilo referenciadas dentro do HTML do cabeçalho sejam resolvidas corretamente.O cabeçalho e rodapé aparecem em todas as páginas do PDF gerado, incluindo documentos de várias páginas. Para um exemplo funcional com metadados de nível de página no rodapé, veja o exemplo de código de cabeçalhos e rodapés HTML.
Ajustes de Margem para Cabeçalhos e Rodapés
Ao adicionar um cabeçalho ou rodapé, aumente a margem correspondente para que o conteúdo não se sobreponha ao corpo da página:
:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/headers-footers-margins.pyfrom ironpdf import *
renderer = ChromePdfRenderer()
renderer.RenderingOptions.MarginTop = 30 # Make room for header
renderer.RenderingOptions.MarginBottom = 20 # Make room for footer
renderer.RenderingOptions.TextHeader = TextHeaderFooter()
renderer.RenderingOptions.TextHeader.CenterText = "Internal Use Only"
renderer.RenderingOptions.TextFooter = TextHeaderFooter()
renderer.RenderingOptions.TextFooter.CenterText = "Page {page} of {total-pages}"
pdf = renderer.RenderHtmlAsPdf("<h1>Internal Document</h1><p>Body content.</p>")
pdf.SaveAs("margined-report.pdf")
Para documentos críticos para layout, combine ajustes de margem com configurações PaperSize para corresponder exatamente a saída a uma especificação de impressão. Controles adicionais de layout - como preenchimentos de fundo IronSoftwareSystemDrawingColor e regras CSS @page - estão detalhados no exemplo de margens personalizadas.
Quais são os próximos passos?
Este tutorial abordou os três principais métodos de conversão de HTML para PDF e as opções de renderização que controlam sua saída. Os guias a seguir desenvolvem essa base e cobrem tarefas mais especializadas:
- Configurações de Geração de PDF - Exploração aprofundada de
ChromePdfRenderOptions: DPI, renderização de fundo, tipo de mídia CSS, estratégias de espera do JavaScript, e modo de impressão versus tela. - Cabeçalhos e Rodapés HTML — Modelos de cabeçalho e rodapé com marca, com logotipos, números de página, datas e layouts de múltiplas colunas.
- Margens Personalizadas e Tamanho de Papel — Ajuste fino da geometria da página para saída pronta para impressão e formatos não padrão.
- Adicionar Marcas d'Água a PDFs — Carimbo de texto ou imagens em PDFs existentes ou recém-gerados.
- Extrair Texto de PDFs — Ler conteúdo textual de PDFs gerados ou existentes de forma programática.
Comece um teste gratuito de 30 dias para gerar PDFs ilimitados e sem marcas d'água durante a avaliação. Quando estiver pronto para produção, veja as opções de licenciamento para equipes e implantações empresariais.
Perguntas frequentes
Como posso converter uma string HTML para PDF em Python?
Instancie ChromePdfRenderer, depois chame renderer.RenderHtmlAsPdf(html_string). O método aceita qualquer HTML válido, incluindo CSS embutido e JavaScript. Salve o PdfDocument retornado com pdf.SaveAs("output.pdf").
Como instalo o IronPDF for Python?
Execute pip install ironpdf de um terminal. O IronPDF for Python requer o SDK .NET 6.0 ou posterior, que deve ser instalado separadamente antes do primeiro uso.
O IronPDF pode converter uma URL ao vivo para PDF em Python?
Sim. Use renderer.RenderUrlAsPdf("https://example.com"). O IronPDF busca a página usando um motor Chromium, aguarda o JavaScript terminar de executar, e então gera o PDF do DOM completamente renderizado.
Como posso converter um arquivo HTML local para PDF?
Chame renderer.RenderHtmlFileAsPdf("path/to/file.html"). O IronPDF resolve todos os caminhos de ativos relativos — folhas de estilo, imagens, scripts — em relação ao diretório do arquivo HTML automaticamente.
Como posso remover a marca d'água de PDFs gerados pelo IronPDF?
Defina uma chave de licença válida com License.LicenseKey = "YOUR-KEY" antes de qualquer operação de PDF. Sem uma chave, o IronPDF adiciona uma marca d'água aplicável para desenvolvimento, mas não para uso em produção.
Quais opções de renderização o IronPDF expõe para Python?
Propriedades em renderer.RenderingOptions controlam o tamanho do papel (PaperSize), orientação (PaperOrientation), margens (MarginTop, MarginLeft, etc.), dimensões personalizadas (CustomPaperWidth, CustomPaperHeight), execução de JavaScript (EnableJavaScript), e mais.
Como posso adicionar números de página a um PDF com IronPDF em Python?
Atribua um TextHeaderFooter a renderer.RenderingOptions.TextFooter e inclua o placeholder {page} ou {total-pages} em uma das propriedades de texto, como RightText ou CenterText.
Posso adicionar um cabeçalho de logotipo para cada página de um PDF gerado?
Sim. Use HtmlHeaderFooter com um fragmento HTML que inclua uma tag <img>. Atribua-o a renderer.RenderingOptions.HtmlHeader e defina BaseUrl para que o caminho da imagem seja resolvido corretamente.
O IronPDF suporta tamanhos de papel personalizados em Python?
Sim. Defina renderer.RenderingOptions.PaperSize para PdfPaperSize.Custom, depois atribua CustomPaperWidth e CustomPaperHeight em milímetros para definir qualquer dimensão de página arbitrária.
Qual versão .NET o IronPDF for Python requer?
O IronPDF for Python requer o SDK .NET 6.0 ou posterior. O SDK está disponível gratuitamente na página de download do Microsoft .NET e deve ser instalado antes de instalar ou executar o IronPDF via pip.


Ainda está rolando a tela?
Quer provas rápidas?
executar um exemplo Veja seu HTML se transformar em um PDF.












