


IronPDF offre aux développeurs Python un chemin direct du balisage HTML vers des fichiers PDF prêts à la production — sans outils de conception intermédiaires, sans moteurs de mise en page propriétaires, sans pipeline de rendu séparé. La classe ChromePdfRenderer de la bibliothèque utilise un moteur basé sur Chromium en arrière-plan, de sorte que tout code HTML s'affichant correctement dans Chrome sera converti avec précision au format PDF. Ce tutoriel explique chaque méthode de conversion prise en charge — chaînes de HTML, fichiers HTML locaux et URL en direct — puis couvre les options de rendu qui vous permettent de contrôler la taille des pages, les marges, les en-têtes, les pieds de page, et plus.
Un tutoriel complémentaire est disponible pour convertir HTML en PDF dans des applications .NET si vous avez besoin du flux de travail C# ou VB.NET.
Démarrage rapide : convertir HTML en PDF en Python
Comment convertir du HTML en PDF en Python

- Installer IronPDF for Python via pip
- Importez la bibliothèque avec
from ironpdf import * - Instancier
ChromePdfRenderer - Appelez
RenderHtmlAsPdf,RenderUrlAsPdf, ouRenderHtmlFileAsPdf - Enregistrez le résultat avec
pdf.SaveAs("output.pdf")
Table des matières
- Comment installer IronPDF for Python ?
- Comment configurer IronPDF avant de convertir ?
- Comment convertir une chaîne HTML en PDF ?
- Comment convertir une URL en PDF ?
- Comment convertir un fichier HTML en PDF ?
- Comment contrôler les options de rendu PDF ?
- Comment ajouter des en-têtes et pieds de page personnalisés ?
- Quelles sont les prochaines étapes ?
Commencer
Comment installer IronPDF en Python ?
IronPDF est distribué via pip, le gestionnaire de packages standard de Python. Exécutez la commande suivante dans un terminal pour installer la dernière version :
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/install.sh
pip install ironpdf//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/install.sh
pip install ironpdfPour ancrer une version spécifique — utile dans les pipelines CI ou les environnements conteneurisés — ajoutez le numéro de version :
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/install-versioned.sh
pip install ironpdf==2024.x.x//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/install-versioned.sh
pip install ironpdf==2024.x.xLa première fois qu'IronPDF s'initialise, il télécharge un binaire Chromium compatible. Ce téléchargement prend un moment sur une machine neuve mais ne se produit qu'une fois par environnement. Les exécutions suivantes démarrent beaucoup plus rapidement car le binaire est mis en cache localement.
Guide pratique et exemples de code
Comment configurer IronPDF avant de convertir ?
Deux tâches de configuration valent la peine d'être complétées avant le premier appel de conversion : définir une clé de licence et — optionnellement — configurer un emplacement de fichier journal.
Importer le package
Chaque fichier Python qui utilise IronPDF nécessite cette ligne unique d'importation. Placez-la en haut du fichier :
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/import.py
from ironpdf import *//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/import.py
from ironpdf import *Toutes les classes IronPDF — ChromePdfRenderer, PdfDocument, License, Logger et les autres — deviennent disponibles via cette importation par caractère générique.
Définir une clé de licence
Sans clé de licence, IronPDF ajoute un filigrane en mosaïque à chaque PDF généré. Le filigrane convient au développement et aux tests, mais les déploiements en production nécessitent une clé valide.
Les PDF générés sans clé de licence incluent un filigrane en mosaïque. Visitez la page de licence pour obtenir une clé.
Définissez la clé avant tout autre appel IronPDF :
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/set-license.py
from ironpdf import *
# Set the license key before any PDF operations
License.LicenseKey = "IRONPDF-MYLICENSE-KEY-1EF01"//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/set-license.py
from ironpdf import *
# Set the license key before any PDF operations
License.LicenseKey = "IRONPDF-MYLICENSE-KEY-1EF01"Commencez un essai gratuit pour recevoir une clé temporaire, ou achetez une licence pour une utilisation en production sans restriction.
Configuration de la sortie des journaux
IronPDF écrit les informations de diagnostic dans un fichier nommé Default.log dans le répertoire de travail du script. Pour rediriger la journalisation vers un autre chemin ou capturer plus de détails à des fins de débogage, définissez les propriétés Logger avant la première conversion :
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/configure-logging.py
from ironpdf import *
# Configure logging before running any conversions
Logger.EnableDebugging = True
Logger.LogFilePath = "ironpdf-debug.log"
Logger.LoggingMode = Logger.LoggingModes.All//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/configure-logging.py
from ironpdf import *
# Configure logging before running any conversions
Logger.EnableDebugging = True
Logger.LogFilePath = "ironpdf-debug.log"
Logger.LoggingMode = Logger.LoggingModes.AllLogger.LogFilePath doit être défini avant le premier appel de conversion PDF/A. Les modifications faites après n'ont aucun effet sur la session en cours.Les journaux détaillés sont les plus utiles pour diagnostiquer pourquoi une page HTML particulière ne se rend pas comme prévu — ils capturent les requêtes réseau, les événements de chargement CSS et le timing d'exécution JavaScript.
Comment convertir une chaîne HTML en PDF ?
Convertir une chaîne HTML en mémoire est l'approche la plus directe et fonctionne bien lorsque le HTML est généré de manière programmatique — par exemple, à partir d'un modèle Jinja2 ou d'un rapport piloté par une base de données.
Conversion de chaîne HTML de base
Instanciez ChromePdfRenderer, transmettez la chaîne HTML à RenderHtmlAsPdf, puis appelez SaveAs sur le PdfDocument renvoyé :
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/html-string-basic.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Convert an HTML string to a PDF document
pdf = renderer.RenderHtmlAsPdf("<h1>Hello from IronPDF!</h1><p>Generated in Python.</p>")
pdf.SaveAs("hello.pdf")//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/html-string-basic.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Convert an HTML string to a PDF document
pdf = renderer.RenderHtmlAsPdf("<h1>Hello from IronPDF!</h1><p>Generated in Python.</p>")
pdf.SaveAs("hello.pdf")
RenderHtmlAsPdf traite le HTML exactement comme le ferait Chrome, y compris le CSS et JavaScript.
Le ChromePdfRenderer traite le HTML, le CSS et le JavaScript de la même manière qu'un navigateur moderne. Tout contenu qui s'affiche correctement dans Chrome produira un PDF précis.
Chaîne HTML avec actifs externes
Lorsque la chaîne HTML fait référence à des ressources locales (feuilles de style, images, scripts), transmettez le chemin d'accès au répertoire en tant que deuxième argument à RenderHtmlAsPdf. IronPDF utilise ce chemin comme URL de base lors de la résolution des références relatives :
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/html-string-assets.py
from ironpdf import *
html_content = """
<html>
<head>
<title>Styled Report</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>Monthly Report</h1>
<img src='assets/logo.png' alt='Company logo'>
<p>Data as of Q1 2024.</p>
</body>
</html>
"""
renderer = ChromePdfRenderer()
# The second argument sets the base path for resolving relative asset URLs
pdf = renderer.RenderHtmlAsPdf(html_content, "./")
pdf.SaveAs("styled-report.pdf")//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/html-string-assets.py
from ironpdf import *
html_content = """
<html>
<head>
<title>Styled Report</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>Monthly Report</h1>
<img src='assets/logo.png' alt='Company logo'>
<p>Data as of Q1 2024.</p>
</body>
</html>
"""
renderer = ChromePdfRenderer()
# The second argument sets the base path for resolving relative asset URLs
pdf = renderer.RenderHtmlAsPdf(html_content, "./")
pdf.SaveAs("styled-report.pdf")
Les CSS externes et les images se chargent correctement lorsque vous fournissez un chemin de base à RenderHtmlAsPdf.
Le chemin de base peut pointer vers n'importe quel répertoire local ou un partage réseau. Les actifs dans les sous-répertoires sont résolus par rapport à celui-ci. Pour plus de modèles impliquant des chaînes HTML complexes, voir l'exemple de code HTML string to PDF.
Comment convertir une URL en PDF ?
La méthode RenderUrlAsPdf récupère une URL active, attend que la page soit entièrement chargée — y compris tout contenu généré par JavaScript — et convertit le résultat affiché au format PDF. Cela le rend adapté pour capturer des tableaux de bord, des rapports ou toute page où l'état visuel final dépend de l'exécution JavaScript.
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/url-to-pdf.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Fetch and convert a live web page to PDF
pdf = renderer.RenderUrlAsPdf("https://en.wikipedia.org/wiki/Portable_Document_Format")
pdf.SaveAs("wikipedia-pdf.pdf")//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/url-to-pdf.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Fetch and convert a live web page to PDF
pdf = renderer.RenderUrlAsPdf("https://en.wikipedia.org/wiki/Portable_Document_Format")
pdf.SaveAs("wikipedia-pdf.pdf")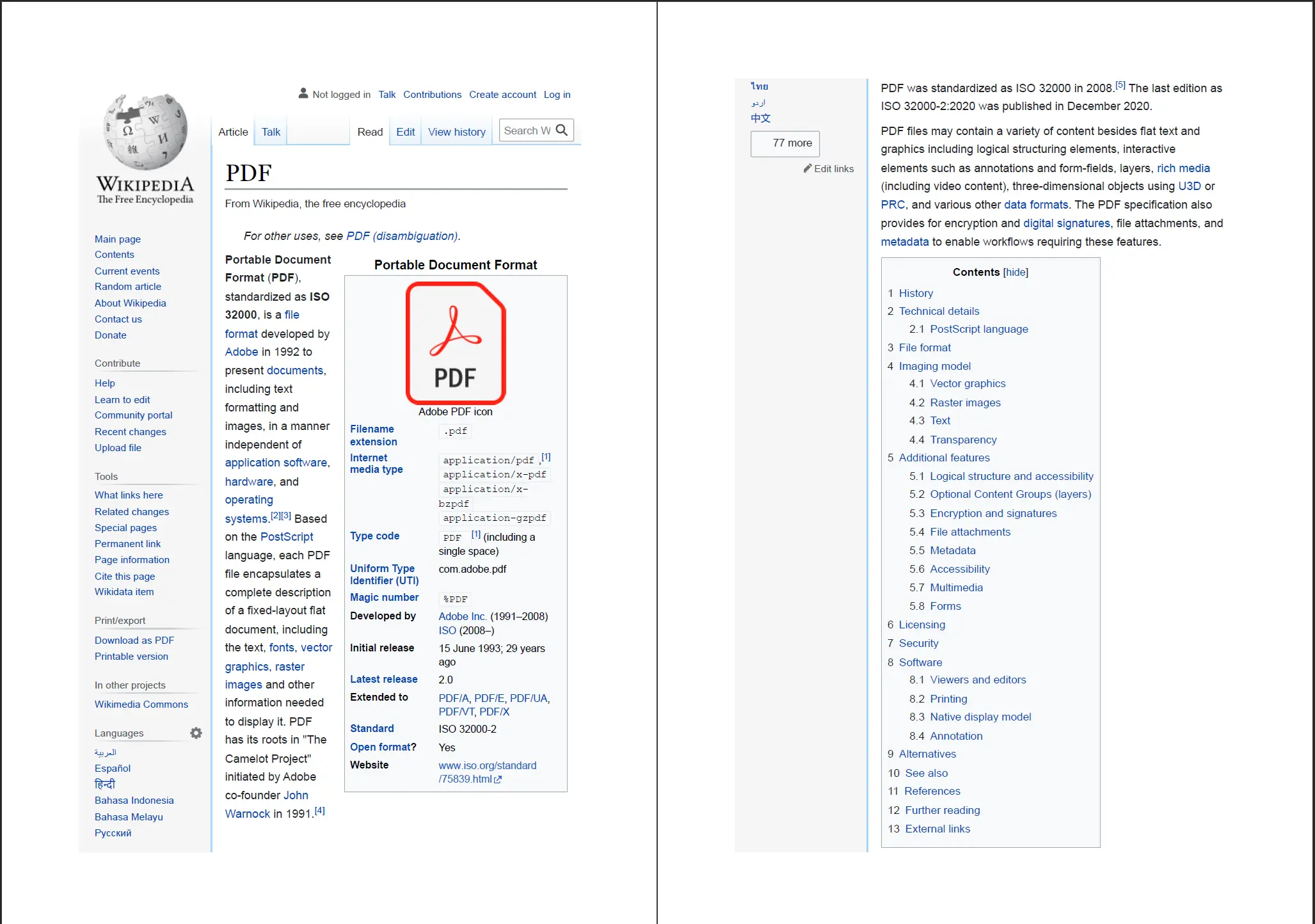
IronPDF récupère l'URL en direct et rend la page complète — JavaScript inclus — avant de générer le PDF.
ChromePdfRenderer avant d'appeler RenderUrlAsPdf. Voir le guide HTTP login credentials guide pour plus de détails.Lorsque la page cible charge du contenu asynchrone, IronPDF attend que le moteur de rendu Chromium signale que le document est complètement peint. Pour les pages comportant beaucoup de JavaScript ou des requêtes réseau différées, envisagez d'ajuster les propriétés WaitFor sur ChromePdfRenderOptions (abordées dans la section sur les options de rendu ci-dessous). L'exemple de code URL to PDF montre des modèles de configuration supplémentaires.
Comment convertir un fichier HTML en PDF ?
RenderHtmlFileAsPdf accepte un chemin d'accès à un fichier HTML local et le convertit directement. Les chemins relatifs à l'intérieur du HTML — vers les fichiers CSS, images, ou JavaScript — sont résolus automatiquement par rapport au propre répertoire du fichier HTML, il n'est donc pas nécessaire d'argumenter un chemin de base.
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/html-file-to-pdf.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Convert a local HTML file (and its linked CSS/JS) to PDF
pdf = renderer.RenderHtmlFileAsPdf("invoices/TestInvoice1.html")
pdf.SaveAs("invoice.pdf")//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/html-file-to-pdf.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Convert a local HTML file (and its linked CSS/JS) to PDF
pdf = renderer.RenderHtmlFileAsPdf("invoices/TestInvoice1.html")
pdf.SaveAs("invoice.pdf")Cette méthode est particulièrement utile pour la génération de documents côté serveur où un modèle HTML a déjà été enregistré sur le disque — un modèle courant lors de l'utilisation de Django ou Flask pour rendre des modèles Jinja2 sur les fichiers avant de les convertir en PDF pour le téléchargement.
IronPDF résout toutes les balises <link>, <script> et <img> relatives à l'emplacement du fichier HTML, de sorte que les feuilles de style liées, les polices intégrées et les images apparaissent dans le PDF exactement comme elles le font dans un navigateur. Le processus reflète la manière dont RenderHtmlAsPdf gère les ressources intégrées, à la différence qu'aucun chemin de base explicite ne doit être fourni.
Comment contrôlez-vous les options de rendu PDF ?
ChromePdfRenderOptions est l'objet de configuration transmis à ChromePdfRenderer (ou directement à l'une des méthodes de rendu) pour contrôler la mise en page, les marges, le format du papier et d'autres caractéristiques de sortie. Définir les options avant la conversion est la méthode standard pour adapter la sortie PDF.
Taille et orientation du papier
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/render-options-paper.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Configure page layout before rendering
renderer.RenderingOptions.PaperSize = PdfPaperSize.A4
renderer.RenderingOptions.PaperOrientation = PdfPaperOrientation.Landscape
renderer.RenderingOptions.MarginTop = 20
renderer.RenderingOptions.MarginBottom = 20
renderer.RenderingOptions.MarginLeft = 15
renderer.RenderingOptions.MarginRight = 15
pdf = renderer.RenderHtmlAsPdf("<h1>Landscape Report</h1><p>Content here.</p>")
pdf.SaveAs("landscape-a4.pdf")//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/render-options-paper.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Configure page layout before rendering
renderer.RenderingOptions.PaperSize = PdfPaperSize.A4
renderer.RenderingOptions.PaperOrientation = PdfPaperOrientation.Landscape
renderer.RenderingOptions.MarginTop = 20
renderer.RenderingOptions.MarginBottom = 20
renderer.RenderingOptions.MarginLeft = 15
renderer.RenderingOptions.MarginRight = 15
pdf = renderer.RenderHtmlAsPdf("<h1>Landscape Report</h1><p>Content here.</p>")
pdf.SaveAs("landscape-a4.pdf")Les marges sont exprimées en millimètres. PdfPaperSize prend en charge tous les formats ISO standard — A0 à A10, Letter, Legal, Tabloid — ainsi que Custom pour les dimensions arbitraires définies par CustomPaperWidth et CustomPaperHeight.
Dimensions de papier personnalisées
Lorsque les tailles de papier standard ne correspondent pas à l'exigence de sortie — par exemple, un format d'imprimante de reçu ou d'étiquette — définissez explicitement la largeur et la hauteur :
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/render-options-custom-size.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Set a custom paper size (in millimetres)
renderer.RenderingOptions.PaperSize = PdfPaperSize.Custom
renderer.RenderingOptions.CustomPaperWidth = 80 # 80 mm receipt roll width
renderer.RenderingOptions.CustomPaperHeight = 200
pdf = renderer.RenderHtmlAsPdf("<h2>Receipt</h2><p>Total: $12.50</p>")
pdf.SaveAs("receipt.pdf")//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/render-options-custom-size.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Set a custom paper size (in millimetres)
renderer.RenderingOptions.PaperSize = PdfPaperSize.Custom
renderer.RenderingOptions.CustomPaperWidth = 80 # 80 mm receipt roll width
renderer.RenderingOptions.CustomPaperHeight = 200
pdf = renderer.RenderHtmlAsPdf("<h2>Receipt</h2><p>Total: $12.50</p>")
pdf.SaveAs("receipt.pdf")Activer l'exécution JavaScript
Par défaut, IronPDF exécute JavaScript lors du rendu. Si une page dépend de JavaScript pour générer un contenu visible — graphiques, tableaux de données, valeurs de formulaire dynamiques — ce comportement signifie que le PDF rendu reflète l'état final du DOM. Pour désactiver JavaScript sur les pages où il n'est pas nécessaire :
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/render-options-javascript.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Disable JavaScript for static HTML pages
renderer.RenderingOptions.EnableJavaScript = False
pdf = renderer.RenderHtmlAsPdf("<p>Static content only.</p>")
pdf.SaveAs("static.pdf")//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/render-options-javascript.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Disable JavaScript for static HTML pages
renderer.RenderingOptions.EnableJavaScript = False
pdf = renderer.RenderHtmlAsPdf("<p>Static content only.</p>")
pdf.SaveAs("static.pdf")Désactiver JavaScript réduit le temps de rendu pour les documents HTML simples et statiques.
Pour plus de détails sur la configuration du rendu, voir les paramètres de génération de PDF et l'exemple de taille de papier personnalisée.
Comment ajoutez-vous des en-têtes et pieds de page personnalisés ?
Les en-têtes et les pieds de page dans IronPDF sont appliqués via les objets HtmlHeaderFooter ou TextHeaderFooter associés au RenderingOptions du moteur de rendu. HtmlHeaderFooter vous offre un contrôle total sur le HTML et le CSS — idéal pour les en-têtes de lettre personnalisés avec logos. TextHeaderFooter est plus simple et couvre la plupart des exigences textuelles, y compris les numéros de page dynamiques.
En-tête et pied de page basés sur le texte
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/headers-footers-text.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Add a text header with the document title
renderer.RenderingOptions.TextHeader = TextHeaderFooter()
renderer.RenderingOptions.TextHeader.CenterText = "Quarterly Report — Q1 2024"
renderer.RenderingOptions.TextHeader.DrawDividerLine = True
renderer.RenderingOptions.TextHeader.FontSize = 10
# Add a footer with page numbers
renderer.RenderingOptions.TextFooter = TextHeaderFooter()
renderer.RenderingOptions.TextFooter.RightText = "Page {page} of {total-pages}"
renderer.RenderingOptions.TextFooter.FontSize = 9
renderer.RenderingOptions.TextFooter.DrawDividerLine = True
html = "<h1>Executive Summary</h1><p>Revenue increased 12% year-over-year.</p>"
pdf = renderer.RenderHtmlAsPdf(html)
pdf.SaveAs("report-with-footer.pdf")//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/headers-footers-text.py
from ironpdf import *
renderer = ChromePdfRenderer()
# Add a text header with the document title
renderer.RenderingOptions.TextHeader = TextHeaderFooter()
renderer.RenderingOptions.TextHeader.CenterText = "Quarterly Report — Q1 2024"
renderer.RenderingOptions.TextHeader.DrawDividerLine = True
renderer.RenderingOptions.TextHeader.FontSize = 10
# Add a footer with page numbers
renderer.RenderingOptions.TextFooter = TextHeaderFooter()
renderer.RenderingOptions.TextFooter.RightText = "Page {page} of {total-pages}"
renderer.RenderingOptions.TextFooter.FontSize = 9
renderer.RenderingOptions.TextFooter.DrawDividerLine = True
html = "<h1>Executive Summary</h1><p>Revenue increased 12% year-over-year.</p>"
pdf = renderer.RenderHtmlAsPdf(html)
pdf.SaveAs("report-with-footer.pdf")Les espaces réservés {page} et {total-pages} sont remplacés au moment du rendu par les valeurs correctes. D'autres espaces réservés sont disponibles, notamment {date}, {time} et {url}.
En-tête basé sur le HTML avec logo
Lorsqu'un en-tête de marque est requis (logo d'entreprise, bande de couleur ou bloc d'adresse formaté), utilisez plutôt HtmlHeaderFooter :
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/headers-footers-html.py
from ironpdf import *
renderer = ChromePdfRenderer()
header_html = """
<div style="font-family: Arial, sans-serif; border-bottom: 2px solid #003366; padding: 8px 0;">
<img src='assets/logo.png' style='height: 40px; float: left;' alt='Company logo'>
<span style='float: right; font-size: 11px; color: #666;'>Confidential</span>
<div style='clear:both;'></div>
</div>
"""
renderer.RenderingOptions.HtmlHeader = HtmlHeaderFooter()
renderer.RenderingOptions.HtmlHeader.HtmlFragment = header_html
renderer.RenderingOptions.HtmlHeader.BaseUrl = "./"
html_body = "<h1>Project Status Update</h1><p>All milestones on track.</p>"
pdf = renderer.RenderHtmlAsPdf(html_body, "./")
pdf.SaveAs("branded-report.pdf")//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/headers-footers-html.py
from ironpdf import *
renderer = ChromePdfRenderer()
header_html = """
<div style="font-family: Arial, sans-serif; border-bottom: 2px solid #003366; padding: 8px 0;">
<img src='assets/logo.png' style='height: 40px; float: left;' alt='Company logo'>
<span style='float: right; font-size: 11px; color: #666;'>Confidential</span>
<div style='clear:both;'></div>
</div>
"""
renderer.RenderingOptions.HtmlHeader = HtmlHeaderFooter()
renderer.RenderingOptions.HtmlHeader.HtmlFragment = header_html
renderer.RenderingOptions.HtmlHeader.BaseUrl = "./"
html_body = "<h1>Project Status Update</h1><p>All milestones on track.</p>"
pdf = renderer.RenderHtmlAsPdf(html_body, "./")
pdf.SaveAs("branded-report.pdf")BaseUrl sur HtmlHeaderFooter avec le même chemin de base que celui utilisé pour le corps du document. Cela garantit que les images et les feuilles de style référencées dans le HTML de l'en-tête se résolvent correctement.L'en-tête et le pied de page apparaissent sur chaque page du PDF généré, y compris les documents multipages. Pour un exemple pratique avec des métadonnées au niveau de la page dans le pied de page, voir l'exemple de code des en-têtes et pieds de page HTML.
Ajustements de marge pour les en-têtes et pieds de page
Lors de l'ajout d'un en-tête ou d'un pied de page, augmentez la marge correspondante pour que le contenu ne se chevauche pas avec le corps de la page :
//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/headers-footers-margins.py
from ironpdf import *
renderer = ChromePdfRenderer()
renderer.RenderingOptions.MarginTop = 30 # Make room for header
renderer.RenderingOptions.MarginBottom = 20 # Make room for footer
renderer.RenderingOptions.TextHeader = TextHeaderFooter()
renderer.RenderingOptions.TextHeader.CenterText = "Internal Use Only"
renderer.RenderingOptions.TextFooter = TextHeaderFooter()
renderer.RenderingOptions.TextFooter.CenterText = "Page {page} of {total-pages}"
pdf = renderer.RenderHtmlAsPdf("<h1>Internal Document</h1><p>Body content.</p>")
pdf.SaveAs("margined-report.pdf")//:path=/static-assets/pdf/content-code-examples/tutorials/html-to-pdf/headers-footers-margins.py
from ironpdf import *
renderer = ChromePdfRenderer()
renderer.RenderingOptions.MarginTop = 30 # Make room for header
renderer.RenderingOptions.MarginBottom = 20 # Make room for footer
renderer.RenderingOptions.TextHeader = TextHeaderFooter()
renderer.RenderingOptions.TextHeader.CenterText = "Internal Use Only"
renderer.RenderingOptions.TextFooter = TextHeaderFooter()
renderer.RenderingOptions.TextFooter.CenterText = "Page {page} of {total-pages}"
pdf = renderer.RenderHtmlAsPdf("<h1>Internal Document</h1><p>Body content.</p>")
pdf.SaveAs("margined-report.pdf")Pour les documents où la mise en page est critique, combinez les ajustements de marge avec les paramètres PaperSize afin que le résultat corresponde exactement aux spécifications de PRINT. Les contrôles de mise en page supplémentaires — tels que les remplissages d'arrière-plan IronSoftwareSystemDrawingColor et les règles CSS @page — sont détaillés dans l'exemple de marges personnalisées.
Quelles sont les prochaines étapes?
Ce didacticiel a couvert les trois méthodes de conversion HTML en PDF de base et les options de rendu qui contrôlent leur sortie. Les guides suivants s'appuient sur cette base et couvrent des tâches plus spécialisées :
- Paramètres de génération de PDF — Analyse approfondie de
ChromePdfRenderOptions: DPI, rendu d'arrière-plan, type de média CSS, stratégies d'attente JavaScript et mode PRINT vs mode écran. - En-têtes et pieds de page HTML — Modèles d'en-tête et pied de page de marque avec logos, numéros de page, dates, et mises en page multicolonnes.
- Marges personnalisées et taille de papier — Réglez finement la géométrie de la page pour une sortie prête à l'impression et des formats non standard.
- Ajouter des filigranes aux PDF — Apposez des filigranes de texte ou d'image sur des PDF existants ou nouvellement générés.
- Extraire du texte des PDF — Lisez le contenu textuel de PDF générés ou existants de manière programmatique.
Commencez un essai gratuit de 30 jours pour générer des PDF illimités et sans filigrane pendant l'évaluation. Lorsque vous êtes prêt pour la production, consultez les options de licence pour les équipes et les déploiements en entreprise.
Questions Fréquemment Posées
Comment convertir une chaîne HTML en PDF en Python ?
Instanciez ChromePdfRenderer, puis appelez renderer.RenderHtmlAsPdf(html_string). La méthode accepte tout HTML valide, y compris CSS et JavaScript en ligne. Enregistrez le PdfDocument retourné avec pdf.SaveAs("output.pdf").
Comment installer IronPDF for Python ?
Exécutez pip install ironpdf depuis un terminal. IronPDF for Python nécessite le .NET 6.0 SDK ou une version ultérieure, qui doit être installée séparément avant la première utilisation.
IronPDF peut-il convertir une URL en direct en PDF en Python ?
Oui. Utilisez renderer.RenderUrlAsPdf("https://example.com"). IronPDF récupère la page en utilisant un moteur Chromium, attend que JavaScript ait terminé son exécution, puis génère le PDF à partir du DOM entièrement rendu.
Comment convertir un fichier HTML local en PDF ?
Appelez renderer.RenderHtmlFileAsPdf("path/to/file.html"). IronPDF résout automatiquement tous les chemins de ressources relatifs - feuilles de style, images, scripts - relatifs au répertoire du fichier HTML.
Comment supprimer le filigrane des PDF générés par IronPDF ?
Définissez une clé de licence valide avec License.LicenseKey = "YOUR-KEY" avant toute opération PDF. Sans clé, IronPDF ajoute un filigrane en mosaïque adapté au développement mais pas pour l'utilisation en production.
Quelles options de rendu IronPDF expose-t-il for Python ?
Les propriétés sur renderer.RenderingOptions contrôlent la taille du papier (PaperSize), l'orientation (PaperOrientation), les marges (MarginTop, MarginLeft, etc.), les dimensions personnalisées (CustomPaperWidth, CustomPaperHeight), l'exécution de JavaScript (EnableJavaScript), et plus encore.
Comment ajouter des numéros de page à un PDF avec IronPDF en Python ?
Attribuez un TextHeaderFooter à renderer.RenderingOptions.TextFooter et incluez l'espace réservé {page} ou {total-pages} dans l'une des propriétés de texte comme RightText ou CenterText.
Puis-je ajouter un en-tête de logo de marque à chaque page d'un PDF généré ?
Oui. Utilisez HtmlHeaderFooter avec un fragment HTML qui inclut une balise renderer.RenderingOptions.HtmlHeader et définissez BaseUrl pour que le chemin de l'image soit résolu correctement.
IronPDF prend-il en charge les tailles de papier personnalisées en Python ?
Oui. Définissez renderer.RenderingOptions.PaperSize sur PdfPaperSize.Custom, puis attribuez CustomPaperWidth et CustomPaperHeight en millimètres pour définir toute dimension de page arbitraire.
Quelle version de .NET IronPDF for Python nécessite-t-il ?
IronPDF for Python nécessite le SDK .NET 6.0 ou une version ultérieure. Le SDK est disponible gratuitement à partir de la page de téléchargement Microsoft .NET et doit être installé avant d'installer ou d'exécuter IronPDF avec pip.


Vous faites encore défiler ?
Vous voulez une preuve rapidement ?
exécuter un échantillon Regardez votre code HTML se transformer en PDF.












