


Fusionner des fichiers PDF en un seul PDF à l'aide de Python
IronPDF for Python offre une solution directe pour fusionner plusieurs documents PDF en un seul fichier à l'aide de la méthode PdfDocument.Merge(), prenant en charge à la fois la fusion de deux fichiers et les opérations par lots pour combiner efficacement de nombreux PDF.
Le PDF (Portable Document Format) est la norme pour le partage de documents qui doivent apparaître de manière identique sur toutes les plateformes et applications. Que vous consolidiez des rapports, combiniez des documents numérisés ou assembliez des formulaires multi-parties, fusionner du contenu PDF provenant de diverses sources est une exigence récurrente dans les flux de travail commerciaux et de traitement des données.
IronPDF gère cette opération en Python avec un seul appel de méthode. Ce guide couvre l'installation, la fusion simple de deux fichiers et les opérations de lot pour combiner plusieurs documents à la fois.
Démarrage rapide : Fusionner des fichiers PDF en Python
#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/quickstart.py
from ironpdf import *
renderer = ChromePdfRenderer()
pdf_a = renderer.RenderHtmlAsPdf("<p>Document A</p>")
pdf_b = renderer.RenderHtmlAsPdf("<p>Document B</p>")
merged = PdfDocument.Merge([pdf_a, pdf_b])
merged.SaveAs("merged.pdf")#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/quickstart.py
from ironpdf import *
renderer = ChromePdfRenderer()
pdf_a = renderer.RenderHtmlAsPdf("<p>Document A</p>")
pdf_b = renderer.RenderHtmlAsPdf("<p>Document B</p>")
merged = PdfDocument.Merge([pdf_a, pdf_b])
merged.SaveAs("merged.pdf")Flux de travail minimal (5 étapes)
- Installer la bibliothèque Python pour fusionner des fichiers PDF
- Utilisez
RenderHtmlAsPdfpour générer des fichiers PDF individuels, ou chargez les existants avecPdfDocument.FromFile - Appliquez la méthode
Mergepour combiner des fichiers PDF en un seulPdfDocument - Enregistrez le document fusionné avec
SaveAs - Pour plusieurs PDF, passez une liste d'objets
PdfDocumentàMerge
Comment installer IronPDF for Python ?
IronPDF est disponible en tant que package Python via pip. Il nécessite Python 3.x et fonctionne sur Windows et Linux sans aucune dépendance système supplémentaire pour les opérations de fusion standard. Le package est livré avec un moteur de rendu basé sur Chrome qui gère la conversion de HTML en PDF en interne.
Installez la bibliothèque IronPdf à l'aide de pip avec la commande suivante :
#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/install.sh
pip install ironpdf#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/install.sh
pip install ironpdfPour des instructions d'installation détaillées et de l'aide pour des problèmes courants tels que les erreurs "Module Non Défini" ou les problèmes de permission, référez-vous à la documentation officielle.
Quelles instructions d'importation sont nécessaires ?
Dans votre script Python, incluez les instructions d'importation suivantes pour accéder aux fonctionnalités de génération et de fusion de PDF d'IronPDF :
#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/imports.py
from ironpdf import *
# Set your license key for production use
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/imports.py
from ironpdf import *
# Set your license key for production use
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Pour les applications de production, configurez votre clé de licence pour débloquer l'ensemble des fonctionnalités d'IronPDF. Un essai gratuit est disponible - commencez votre essai gratuit pour débuter sans achat.
Comment fusionner deux fichiers PDF en Python?
La fusion de fichiers PDF en Python se déroule en deux étapes : la création des documents PDF sources, puis leur combinaison à l'aide de PdfDocument.Merge(). La méthode accepte une liste d'objets PdfDocument et génère un nouveau document combiné dans l'ordre où les éléments apparaissent dans la liste.
Ci-dessous un exemple complet fonctionnel :
#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/merge-two-pdfs.py
from ironpdf import *
# HTML content for the first PDF
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
# HTML content for the second PDF
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
# Initialize renderer
renderer = ChromePdfRenderer()
# Convert each HTML string to a PDF document
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
# Merge the two documents into one
merged = PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
# Save the merged result to disk
merged.SaveAs("Merged.pdf")#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/merge-two-pdfs.py
from ironpdf import *
# HTML content for the first PDF
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
# HTML content for the second PDF
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
# Initialize renderer
renderer = ChromePdfRenderer()
# Convert each HTML string to a PDF document
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
# Merge the two documents into one
merged = PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
# Save the merged result to disk
merged.SaveAs("Merged.pdf")Pourquoi utiliser RenderHtmlAsPdf pour la génération de PDF?
L'exemple ci-dessus utilise deux chaînes HTML, chacune représentant un document de deux pages. RenderHtmlAsPdf convertit chaque chaîne en un objet PdfDocument à l'aide du moteur de rendu basé sur Chrome d'IronPDF, qui produit des résultats précis à partir de contenu HTML, CSS et JavaScript. Cette approche est bien adaptée pour générer des rapports ou des documents pilotés par des données à partir de modèles web. Pour des scénarios de rendu plus complexes, voir le tutoriel HTML vers PDF.
PdfDocument.FromFile("path/to/file.pdf") et les transmettre directement à la méthode Merge. Cela est utile lors de la combinaison de rapports préexistants ou de documents générés à l'extérieur.Comment fonctionne la méthode de fusion?
PdfDocument.Merge prend une liste Python d'objets PdfDocument comme seul argument. Il combine les documents dans l'ordre de la liste, plaçant toutes les pages du premier document avant toutes les pages du second, et ainsi de suite. Le résultat est un nouveau PdfDocument qui peut être modifié ou enregistré. Le nombre de pages, les signets et le contenu intégré de chaque document source sont tous préservés dans la sortie.
La méthode accepte tout mélange de documents rendus et chargés depuis des fichiers dans la même liste. Cela signifie que vous pouvez combiner une sortie HTML nouvellement rendue avec des PDF existants à partir du disque en un seul appel, ce qui est utile lorsqu'une partie d'un rapport est générée dynamiquement et qu'une autre partie est un modèle statique.
Comment sauvegarder le PDF fusionné ?
Transmettez le chemin de sortie souhaité à SaveAs pour enregistrer le document fusionné sur le disque :
#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/save-merged.py
# Save the merged document
merged.SaveAs("Merged.pdf")
# Optionally compress images before saving to reduce file size
merged.CompressImages(90)
merged.SaveAs("Merged_Compressed.pdf")#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/save-merged.py
# Save the merged document
merged.SaveAs("Merged.pdf")
# Optionally compress images before saving to reduce file size
merged.CompressImages(90)
merged.SaveAs("Merged_Compressed.pdf")Après l'enregistrement, vous pouvez appliquer un traitement supplémentaire tel que la compression PDF pour réduire la taille des fichiers des documents fusionnés.
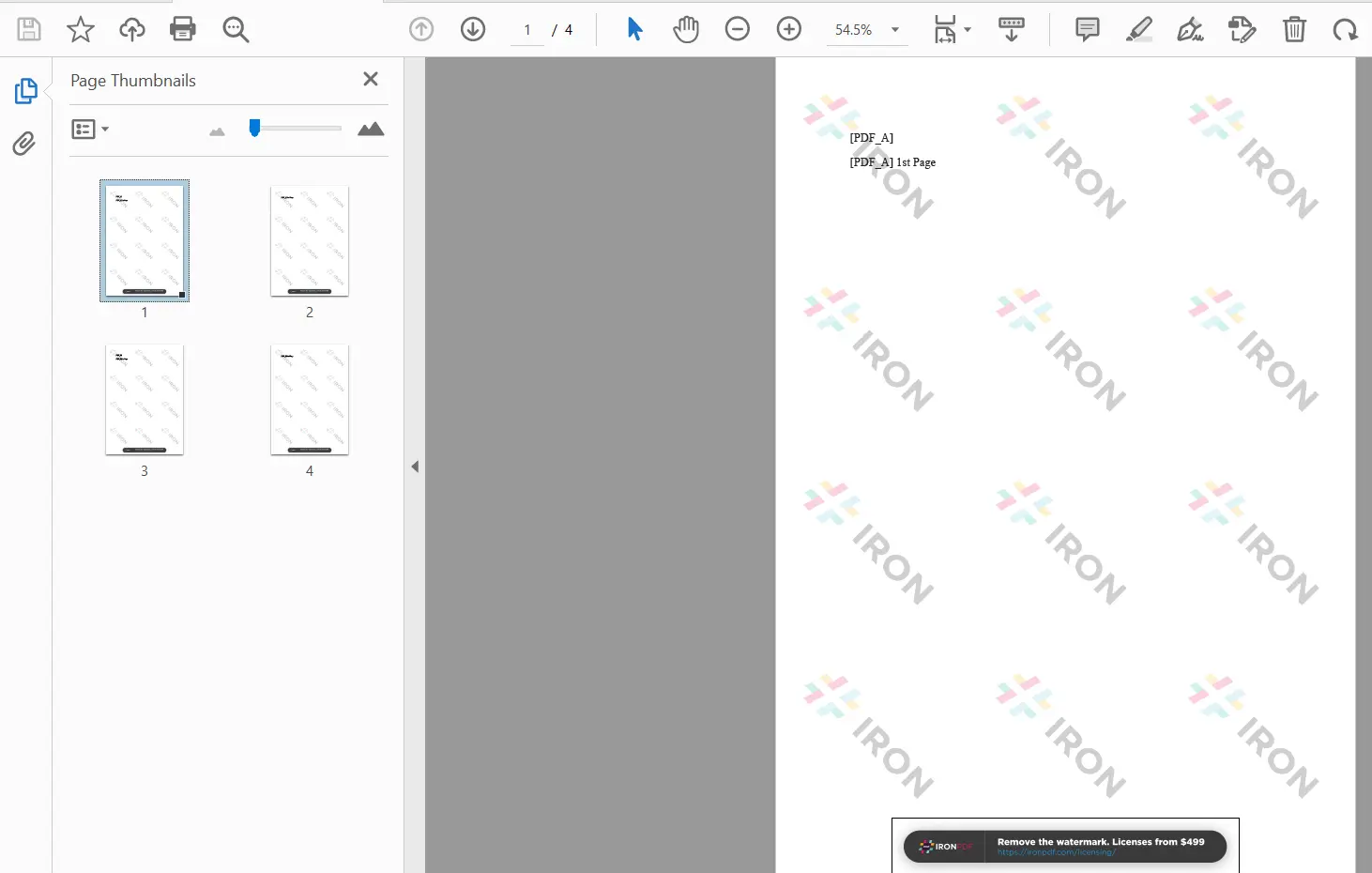
Sortie PDF fusionnée affichant les pages des deux documents source
Comment puis-je fusionner plus de deux fichiers PDF en Python ?
Le traitement par lots dans IronPDF suit le même schéma que la fusion de deux documents. La seule différence est que davantage d'objets PdfDocument sont ajoutés à la liste avant l'appel à PdfDocument.Merge. La méthode s'adapte pour gérer des dizaines ou des centaines de documents en une seule opération.
Il s'agit de la même API que vous fusionniez 2 ou 200 documents. Pour des scénarios à haut volume tels que l'agrégation de rapports nocturnes ou les pipelines d'assemblage de documents, IronPDF prend également en charge la génération parallèle de PDF pour accélérer la phase de rendu avant la fusion.
Le processus implique deux étapes:
- Créez une liste Python contenant les objets
PdfDocumentà fusionner - Passez la liste en argument à
PdfDocument.Merge
Comment puis-je combiner plusieurs PDFs avec une liste ?
Le code ci-dessous fusionne quatre documents rendus en HTML en un seul appel :
#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/merge-multiple-pdfs.py
from ironpdf import *
# HTML content for each document
html_a = """<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
html_c = """<p> [PDF_C] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_C] 2nd Page</p>"""
html_d = """<p> [PDF_D] Content Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_D] Summary Page</p>"""
renderer = ChromePdfRenderer()
# Render all four documents
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
pdfdoc_c = renderer.RenderHtmlAsPdf(html_c)
pdfdoc_d = renderer.RenderHtmlAsPdf(html_d)
# Collect into a list and merge
pdfs = [pdfdoc_a, pdfdoc_b, pdfdoc_c, pdfdoc_d]
pdf = PdfDocument.Merge(pdfs)
# Save the combined document
pdf.SaveAs("merged_multiple.pdf")#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/merge-multiple-pdfs.py
from ironpdf import *
# HTML content for each document
html_a = """<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
html_c = """<p> [PDF_C] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_C] 2nd Page</p>"""
html_d = """<p> [PDF_D] Content Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_D] Summary Page</p>"""
renderer = ChromePdfRenderer()
# Render all four documents
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
pdfdoc_c = renderer.RenderHtmlAsPdf(html_c)
pdfdoc_d = renderer.RenderHtmlAsPdf(html_d)
# Collect into a list and merge
pdfs = [pdfdoc_a, pdfdoc_b, pdfdoc_c, pdfdoc_d]
pdf = PdfDocument.Merge(pdfs)
# Save the combined document
pdf.SaveAs("merged_multiple.pdf")La liste transmise à Merge détermine l'ordre des pages dans le document final. Réorganiser les éléments dans la liste modifie l'ordre de sortie sans code supplémentaire. Si vous devez trier les documents avant la fusion (par exemple, par date ou par numéro de rapport), triez d'abord la liste Python, puis transmettez-la à Merge.
Comment puis-je fusionner des fichiers PDF existants à partir du disque ?
Lorsque vous combinez des fichiers PDF préexistants plutôt que des fichiers nouvellement générés, chargez chaque fichier avec PdfDocument.FromFile avant la fusion. C'est le schéma typique lors de la manipulation de fichiers produits par d'autres systèmes - documents scannés, exportations de rapports tiers ou PDFs générés par différents outils. IronPDF lit le fichier en mémoire sous la forme d'un objet PdfDocument, qui peut ensuite être fusionné, modifié ou inspecté avant l'enregistrement final.
#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/merge-existing-pdfs.py
from ironpdf import *
# Load existing PDF files from disk
existing_pdf1 = PdfDocument.FromFile("report1.pdf")
existing_pdf2 = PdfDocument.FromFile("report2.pdf")
existing_pdf3 = PdfDocument.FromFile("report3.pdf")
# Merge all loaded documents
merged_existing = PdfDocument.Merge([existing_pdf1, existing_pdf2, existing_pdf3])
# Save the combined result
merged_existing.SaveAs("merged_reports.pdf")#:path=/static-assets/pdf/content-code-examples/how-to/python-merge-pdf/merge-existing-pdfs.py
from ironpdf import *
# Load existing PDF files from disk
existing_pdf1 = PdfDocument.FromFile("report1.pdf")
existing_pdf2 = PdfDocument.FromFile("report2.pdf")
existing_pdf3 = PdfDocument.FromFile("report3.pdf")
# Merge all loaded documents
merged_existing = PdfDocument.Merge([existing_pdf1, existing_pdf2, existing_pdf3])
# Save the combined result
merged_existing.SaveAs("merged_reports.pdf")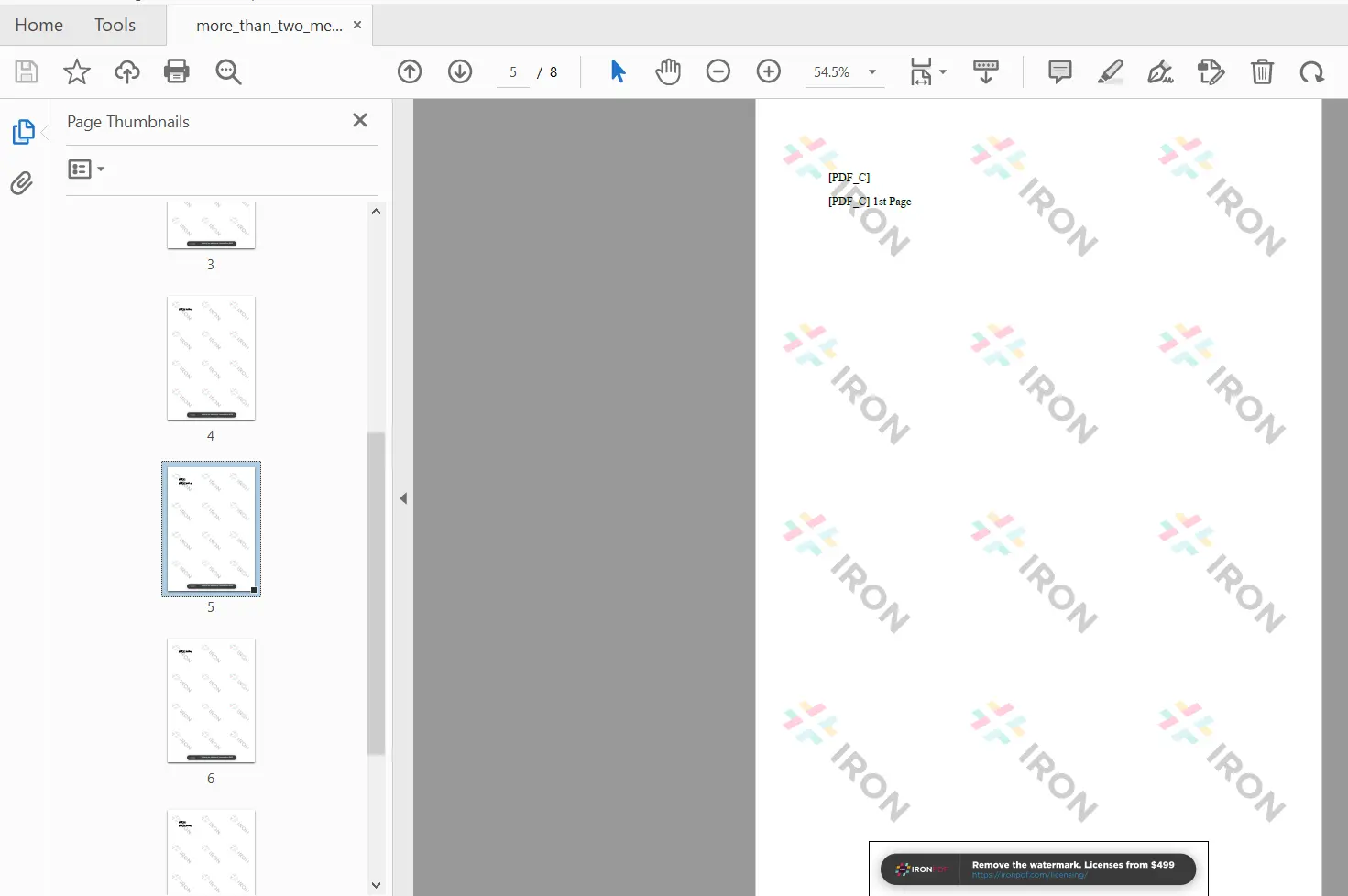
Résultat de la fusion de plusieurs documents montrant les pages des quatre PDF source
Quelles sont les prochaines étapes pour la fusion de PDFs en Python ?
Ce guide a présenté les deux principaux modèles de fusion de PDF avec IronPDF : le rendu de contenu HTML en documents PDF et leur combinaison à l'aide de PdfDocument.Merge, ainsi que le chargement de fichiers existants depuis le disque pour une combinaison par lots. Les deux approches partagent la même API et s'adaptent aux fusions simples de deux fichiers jusqu'aux lots de documents importants.
IronPDF prend en charge des opérations post-fusion supplémentaires telles que l'ajout d'entêtes et de pieds de page, l'application de filigranes pour l'image de marque, l'extraction de texte du document combiné, et le remplissage de formulaires PDF de manière programmatique.
La bibliothèque prend en charge Python 3.x sur Windows et Linux. Pour plus d'opérations PDF en Python, explorez la division de PDFs, la conversion de PDFs en images, et l'impression de PDFs. Pour la liste complète des exemples de code Python, visitez la page des exemples IronPDF for Python.
Commencez votre essai gratuit pour tester la fusion de PDFs dans votre environnement, ou consultez les options de licence pour les déploiements en production.
Prêt à voir ce que vous pouvez faire d'autre? Découvrez la page du tutoriel IronPDF Python ici : tutoriels IronPDF for Python
Téléchargez le produit logiciel.
Questions Fréquemment Posées
Comment fusionner plusieurs fichiers PDF en un seul à l'aide de Python ?
Installez IronPDF avec pip install ironpdf, puis appelez PdfDocument.Merge() avec une liste Python d'objets PdfDocument. La méthode renvoie un nouveau document combiné que vous enregistrez avec SaveAs.
Puis-je fusionner des fichiers PDF existants depuis le disque au lieu de ceux rendus ?
Oui. Utilisez PdfDocument.FromFile('path/to/file.pdf') pour charger chaque PDF existant, puis passez les objets chargés à PdfDocument.Merge(). Vous pouvez mélanger des documents chargés par fichier et fraîchement rendus dans la même liste.
La fusion de PdfDocument conserve-t-elle la mise en forme et les polices des documents ?
Oui. IronPDF conserve les polices, les images, les annotations et les mises en page de toutes les sources pendant la fusion. L'apparence d'origine de chaque document source est maintenue dans le PDF final fusionné.
Comment contrôler l'ordre des pages dans le PDF fusionné ?
L'ordre des pages dans la sortie correspond à celui des objets PdfDocument dans la liste Python passé à Merge. Réorganisez les éléments de la liste avant d'appeler Merge pour contrôler la séquence.
Puis-je compresser le PDF fusionné pour réduire la taille du fichier ?
Oui. Après la fusion, appelez CompressImages(quality) sur le PdfDocument fusionné avant d'appeler SaveAs. Une valeur de qualité de 90 offre un bon équilibre entre compression et fidélité visuelle.
IronPDF for Python est-il multiplateforme ?
Oui. IronPDF for Python prend en charge Python 3.x sur Windows et Linux. La même API PdfDocument.Merge() fonctionne sur les deux plateformes sans modifications de configuration.
Puis-je ajouter des métadonnées au document PDF fusionné ?
Oui. Après la fusion, définissez des propriétés de métadonnées telles que pdf.MetaData.Author et pdf.MetaData.Title sur le PdfDocument fusionné avant de sauvegarder.


Vous faites encore défiler ?
Vous voulez une preuve rapidement ?
exécuter un échantillon Regardez votre code HTML se transformer en PDF.












