
Python에서 BeautifulSoup을 사용한 웹 스크래핑
이제 Python 개발자는 Beautiful Soup와 IronPDF 결합하여 동적 PDF를 생성하고 웹 스크래핑을 간소화할 수 있습니다. 개발자는 HTML 및 XML 파일 파싱 능력이 뛰어난 것으로 잘 알려진 Beautiful Soup을 사용하여 웹 소스에서 모든 데이터를 쉽고 정확하게 추출할 수 있습니다. 한편, IronPDF 는 원활한 통합과 탄탄한 기능을 갖춘 강력한 도구로, 프로그래밍 방식으로 PDF 문서를 생성하는 데 사용할 수 있습니다.
이 두 가지 강력한 도구를 결합하면 개발자는 송장 생성, 콘텐츠 보관, 보고서 생성과 같은 프로세스를 비교할 수 없는 효율성으로 자동화할 수 있습니다. 이 입문 과정에서는 Beautiful Soup Python 라이브러리와 IronPDF 의 미묘한 차이점을 자세히 살펴보고, 각각의 장점과 결합 시 발휘되는 혁신적인 잠재력을 강조합니다. 웹 스크래핑과 PDF 생성 기능을 완벽하게 활용하여 Python 개발자에게 어떤 기회가 기다리고 있는지 함께 살펴보겠습니다.
HTML/XML 파싱
Beautiful Soup는 HTML 태그와 XML 문서를 분석하여 탐색 가능한 구문 트리로 변환하는 데 매우 뛰어납니다. 이 기능은 잘못된 HTML 요소를 부드럽게 처리하므로 개발자는 구문 분석 문제에 대한 걱정 없이 불완전한 데이터를 처리할 수 있습니다.
HTML 페이지에서 특정 항목 찾기
Beautiful Soup의 사용자 친화적인 탐색 기능 덕분에 HTML 페이지에서 특정 항목을 쉽게 찾을 수 있습니다. search, find_all, 그리고 select 같은 기술을 사용하여, 개발자들은 트리 구조를 탐색하고 태그, 속성, 또는 CSS 선택자를 기반으로 요소를 정확하게 찾을 수 있습니다.
태그 특성 및 내용 접근
Beautiful Soup는 구문 분석 트리 내에서 요소를 찾은 후 해당 요소의 특성과 내용을 쉽게 가져올 수 있는 방법을 제공합니다. 개발자는 태그에 연결된 사용자 정의 속성뿐만 아니라 href 속성 및 class, id와 같은 다른 속성도 얻을 수 있습니다. 추가 처리를 위해 요소의 내부 HTML 요소 또는 텍스트 콘텐츠에 접근할 수도 있습니다.
검색 및 필터링
Beautiful Soup는 개발자가 다양한 표준에 따라 구성 요소를 찾을 수 있도록 강력한 검색 및 필터링 기능을 제공합니다. 또한 보다 복잡한 패턴 일치를 위해 정규 표현식을 사용할 수도 있습니다. 특정 태그를 검색하거나 특징 또는 CSS 클래스를 기준으로 항목을 필터링할 수 있습니다. 이것을 더욱 간소화하기 위해 requests 라이브러리를 사용하여 웹 페이지를 가져와서 구문 분석할 수 있습니다. 이러한 유연성 덕분에 HTML/XML 문서에서 특정 데이터를 추출하는 것이 용이해집니다.
구문 트리 탐색하기
문서 구조 내에서 개발자는 구문 분석 트리에서 위, 아래 및 좌우로 이동할 수 있습니다. Beautiful Soup 덕분에 부모, 형제 및 자식 요소에 접근할 수 있어 문서 계층 구조를 자세히 탐색하기가 더 쉬워집니다.
데이터 추출
Beautiful Soup의 핵심 기능 중 하나는 HTML 및 XML 텍스트에서 데이터를 추출하는 기능입니다. 개발자는 웹 페이지에서 텍스트, 링크, 사진, 표 및 기타 콘텐츠 항목을 쉽게 추출할 수 있습니다. 복잡한 문서에서 탐색, 필터링 및 순회 알고리즘을 통합하여 특정 데이터 포인트 또는 전체 콘텐츠 덩어리를 추출할 수 있습니다.
인코딩 및 엔티티 관리
Beautiful Soup는 문자 인코딩 및 HTML 웹 엔티티를 자동으로 처리하여 인코딩 문제나 특수 문자에 관계없이 텍스트 데이터가 정확하게 처리되도록 합니다. 이 기능은 엔티티 디코딩이나 수동 인코딩 변환이 필요 없도록 하여 다양한 출처의 웹 자료를 더 쉽게 다룰 수 있도록 해줍니다.
구문 트리 수정
Beautiful Soup는 추출을 용이하게 할 뿐만 아니라 개발자가 구문 분석 트리를 동적으로 변경할 수 있도록 해줍니다. 필요에 따라 문서 구조를 재구성하거나, 태그 및 속성을 추가, 제거 또는 변경하거나, 새 요소를 추가할 수 있습니다. 이 기능을 통해 데이터 정리, 콘텐츠 보강, 구조 변경과 같은 문서 내 작업을 수행할 수 있습니다.
Python용 Beautiful Soup 생성 및 구성
파서 선택하기
Beautiful Soup이 HTML 또는 XML 문서를 처리하려면 파서가 필요합니다. 기본적으로 Python의 내장 html.parser을(를) 사용합니다. 특정 문서와의 더 나은 효율성이나 호환성을 위해 lxml이나 html5lib와 같은 다른 파서를 지정할 수 있습니다. BeautifulSoup 객체를 생성하는 과정에서, 파서를 제공할 수 있습니다:
from bs4 import BeautifulSoup
# Specify the parser (e.g., 'lxml' or 'html5lib')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'lxml')from bs4 import BeautifulSoup
# Specify the parser (e.g., 'lxml' or 'html5lib')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'lxml')구문 분석 옵션 설정하기
Beautiful Soup는 구문 분석 작동 방식을 변경할 수 있는 몇 가지 옵션을 제공합니다. 예를 들어 HTML 엔티티를 유니코드 문자로 변환하는 기능을 끄거나 더 엄격한 구문 분석 옵션을 활성화할 수 있습니다. BeautifulSoup 객체가 생성되면, 이러한 설정이 인수로 제공됩니다. 다음은 엔티티 변환을 끄는 방법을 보여주는 예시입니다.
from bs4 import BeautifulSoup
# Disable entity conversion
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', convert_entities=False)from bs4 import BeautifulSoup
# Disable entity conversion
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', convert_entities=False)인코딩 감지
Beautiful Soup는 문서의 인코딩을 자동으로 파악하려고 시도합니다. 하지만 때때로, 특히 내용이 불분명하거나 인코딩에 문제가 있는 경우에는 인코딩 방식을 명시적으로 지정해야 할 수도 있습니다. BeautifulSoup 객체를 생성할 때, 인코딩을 정의하는 옵션이 있습니다:
from bs4 import BeautifulSoup
# Specify the encoding (e.g., 'utf-8')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')from bs4 import BeautifulSoup
# Specify the encoding (e.g., 'utf-8')
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')출력 형식
Beautiful Soup는 기본적으로 파싱된 콘텐츠에 줄 바꿈과 들여쓰기를 추가하여 읽기 쉽게 만듭니다. 반면, BeautifulSoup 객체를 구성할 때, 출력 형식을 변경할 수 있는 formatter 옵션을 제공할 수 있습니다. 예를 들어, 보기 좋게 인쇄하는 기능을 끄려면 다음과 같이 하세요.
from bs4 import BeautifulSoup
# Disable pretty-printing
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', formatter=None)from bs4 import BeautifulSoup
# Disable pretty-printing
html_content = "<html>Your HTML content here</html>"
soup = BeautifulSoup(html_content, 'html.parser', formatter=None)NavigableString 및 Tag 서브클래스
Beautiful Soup에서 NavigableString 및 Tag 객체에 사용하는 클래스를 변경할 수 있습니다. 이는 Beautiful Soup의 기능을 확장하거나 다른 라이브러리와 통합하는 데 도움이 될 수 있습니다. BeautifulSoup 객체를 생성할 때, NavigableString 및 Tag의 서브클래스를 매개변수로 전달할 수 있습니다.
시작하기
IronPDF 란 무엇인가요?
IronPDF C#, VB .NET 및 기타 .NET 언어로 PDF 문서를 프로그래밍 방식으로 생성, 편집 및 수정하는 데 사용할 수 있는 강력한 .NET 라이브러리입니다. 이 기능은 개발자에게 고품질 PDF를 동적으로 생성할 수 있는 광범위한 기능을 제공하기 때문에 많은 앱에서 널리 사용되는 옵션입니다.
IronPDF 의 특징
- PDF 생성: IronPDF 사용하면 개발자는 HTML 태그, 텍스트, 그림 및 기타 파일 형식을 PDF로 변환하거나 PDF 문서를 처음부터 새로 생성할 수 있습니다. 이 기능은 보고서, 송장, 영수증 및 기타 문서를 동적으로 생성하는 데 매우 유용합니다.
- HTML을 PDF로 변환: IronPDF 사용하면 개발자는 JavaScript 및 CSS 스타일을 포함한 HTML 구조를 PDF 문서로 쉽게 변환할 수 있습니다. 이를 통해 HTML 템플릿, 웹 페이지 및 동적으로 생성된 자료에서 PDF를 생성할 수 있습니다.
- PDF 문서 편집 및 조작: IronPDF 기존 PDF 문서에 대한 다양한 편집 및 조작 기능을 제공합니다. 개발자는 PDF를 원하는 사양에 맞게 수정하기 위해 여러 PDF 파일을 결합하거나, 개별 문서로 분할하거나, 페이지를 추출하거나, 책갈피, 주석, 워터마크 등을 추가할 수 있습니다.
설치
IronPDF 와 Beautiful Soup를 먼저 설치해야 합니다. Python 패키지 관리자인 Pip을 사용하면 설치할 수 있습니다.
pip install beautifulsoup4 ironpdf
라이브러리 가져오기
다음으로, 필요한 라이브러리를 사용하여 Python 스크립트를 가져옵니다.
from bs4 import BeautifulSoup
from ironpdf import IronPdffrom bs4 import BeautifulSoup
from ironpdf import IronPdfBeautiful Soup을 이용한 웹 스크래핑
Beautiful Soup를 활용하여 웹사이트에서 정보를 추출해 보겠습니다. 예를 들어 웹페이지에서 기사의 제목과 내용을 가져오고 싶다고 가정해 봅시다.
# HTML content of the article
html_content = """
<html>
<head>
<title>Hello</title>
</head>
<body>
<h1>IronPDF</h1>
<p>This is a sample content of the article.</p>
</body>
</html>
"""
# Create a BeautifulSoup object
soup = BeautifulSoup(html_content, 'html.parser')
# Extract title and content
title = soup.find('title').text
content = soup.find('h1').text + soup.find('p').text
print('Title:', title)
print('Content:', content)# HTML content of the article
html_content = """
<html>
<head>
<title>Hello</title>
</head>
<body>
<h1>IronPDF</h1>
<p>This is a sample content of the article.</p>
</body>
</html>
"""
# Create a BeautifulSoup object
soup = BeautifulSoup(html_content, 'html.parser')
# Extract title and content
title = soup.find('title').text
content = soup.find('h1').text + soup.find('p').text
print('Title:', title)
print('Content:', content)IronPDF 사용하여 PDF 생성하기
이제 IronPDF 사용하여 추출한 데이터를 포함하는 PDF 문서를 만들어 보겠습니다.
from ironpdf import IronPdf, ChromePdfRenderer
# Initialize IronPDF
# Create a new PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(
"<html><head><title>{}</title></head><body><h1>{}</h1><p>{}</p></body></html>".format(title, title, content)
)
# Save the PDF document to a file
pdf.SaveAs("sample_article.pdf")from ironpdf import IronPdf, ChromePdfRenderer
# Initialize IronPDF
# Create a new PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(
"<html><head><title>{}</title></head><body><h1>{}</h1><p>{}</p></body></html>".format(title, title, content)
)
# Save the PDF document to a file
pdf.SaveAs("sample_article.pdf")이 스크립트는 샘플 기사의 제목과 텍스트를 가져와서 그것을 추출하고, HTML 데이터를 sample_article.pdf라는 PDF 파일로 저장할 것입니다. 이는 현재 디렉토리에 저장됩니다.
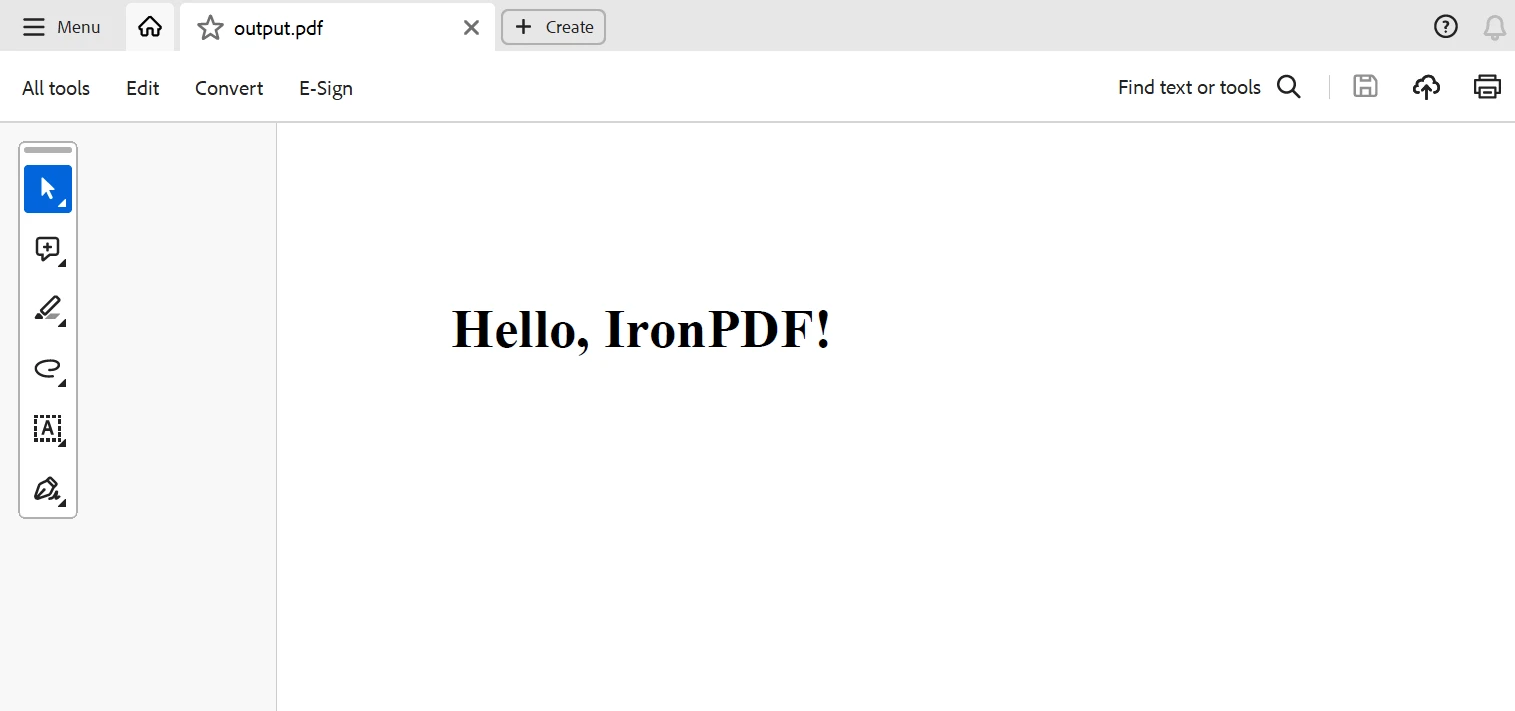
결론
결론적으로, 데이터 추출 및 문서 생성 워크플로를 최적화하려는 개발자는 Beautiful Soup Python과 IronPDF 의 강력한 조합을 발견하게 될 것입니다. IronPDF의 강력한 기능은 전문가 수준의 PDF 문서를 동적으로 생성할 수 있도록 해주며, Beautiful Soup의 간편한 구문 분석 기능은 웹 소스에서 유용한 데이터를 추출할 수 있도록 해줍니다.
이 두 라이브러리를 결합하면 개발자는 송장 생성, 보고서 작성, 웹 스크래핑 등 다양한 작업을 자동화하는 데 필요한 리소스를 확보할 수 있습니다. Beautiful Soup와 IronPDF 의 협력을 통해 개발자는 복잡한 HTML 코드에서 데이터를 추출하거나 맞춤형 PDF 문서를 즉시 생성하는 등 목표를 신속하고 효과적으로 달성할 수 있습니다.
IronPDF 패키지로 구매할 경우 가격이 합리적이며 평생 라이선스가 제공됩니다. 패키지의 비용은 $999이며 여러 시스템에 대한 일회성 결제이므로 뛰어난 가치를 제공합니다. 라이선스 보유자는 24시간 온라인 엔지니어링 지원을 받을 수 있습니다. 요금에 대한 자세한 내용은 웹사이트를 참조하십시오. Iron Software의 제품에 대한 자세한 내용은 이 웹사이트를 방문하십시오.
















