
Python을 이용한 분산 컴퓨팅
분산형 Python
급변하는 기술 분야에서 확장 가능하고 효율적인 컴퓨팅 솔루션에 대한 필요성이 그 어느 때보다 커지고 있습니다. 분산 컴퓨팅은 대규모 분산 데이터 처리, 동시 사용자 요청 및 계산 집약적인 작업과 관련된 업무에 점점 더 필수적인 요소가 되고 있습니다. 개발자들이 분산 Python을 최대한 활용할 수 있도록, 이 글에서는 분산 Python의 응용 분야, 원칙 및 도구를 살펴보겠습니다.
PDF 문서를 동적으로 생성하고 수정하는 것은 웹 개발 분야에서 흔히 요구되는 사항입니다. PDF 파일을 프로그램으로 생성하는 기능은 송장, 보고서 및 인증서를 신속하게 생성하는 데 유용합니다.
Python의 광범위한 생태계와 다재다능함 덕분에 다양한 PDF 라이브러리를 다룰 수 있습니다. IronPDF은 개발자가 PDF 생성 과정을 간소화하고 작업 병렬 처리 및 분산 컴퓨팅도 가능하게 함으로써 인프라를 최대한 활용하도록 돕는 강력한 솔루션입니다.
분산 Python 이해하기
기본적으로 분산 Python은 계산 작업을 더 작은 단위로 나누고 여러 노드 또는 처리 장치에 분산시키는 프로세스입니다. 이러한 노드는 네트워크에 연결된 개별 머신, 시스템 내의 개별 CPU 코어, 원격 객체, 원격 함수, 원격 또는 함수 호출 실행, 심지어 단일 프로세스 내의 개별 스레드일 수도 있습니다. 목표는 작업 부하를 병렬화하여 성능, 확장성 및 내결함성을 향상시키는 것입니다.
Python은 사용 편의성, 적응성 및 탄탄한 라이브러리 생태계 덕분에 분산 컴퓨팅 워크로드에 매우 적합한 선택입니다. Python은 Celery, Dask, Apache Spark 같은 강력한 프레임워크부터 multiprocessing, threading 같은 내장 모듈에 이르기까지 모든 규모와 사용 사례에 걸쳐 분산 컴퓨팅을 위한 다양한 도구를 제공합니다.
구체적인 내용을 살펴보기 전에, 분산 Python이 기반으로 하는 기본 개념과 원칙을 먼저 살펴보겠습니다.
병렬 처리 vs. 동시 처리
병렬 처리는 여러 작업을 동시에 수행하는 것을 의미하며, 동시성은 동시에 진행될 필요는 없지만 여러 작업이 동시에 진행될 수 있도록 처리하는 것과 관련이 있습니다. 분산 Python은 수행해야 할 작업과 시스템 설계에 따라 병렬 처리와 동시 처리를 모두 지원합니다.
업무 분배
병렬 및 분산 컴퓨팅의 핵심 요소는 여러 노드 또는 처리 장치에 작업을 분산하는 것입니다. 효율적인 작업 분배는 컴퓨팅 프로그램의 함수 실행이 여러 코어에 걸쳐 병렬화되든, 데이터 처리 파이프라인이 더 작은 단계로 나뉘든 관계없이 전반적인 성능, 효율성 및 자원 사용을 최적화하는 데 매우 중요합니다.
의사소통 및 조정
분산 시스템에서 노드 간의 효과적인 의사소통과 조정은 원격 기능 실행, 복잡한 워크플로, 데이터 교환 및 연산 동기화를 원활하게 수행하는 데 필수적입니다.
분산 Python 프로그램은 메시지 큐, 분산 데이터 구조, 원격 프로시저 호출(RPC)과 같은 기술을 활용하여 원격 함수 실행과 실제 함수 실행 간의 원활한 조정 및 통신을 가능하게 합니다.
신뢰성 및 오류 방지
시스템이 서로 다른 머신에 노드 또는 처리 장치를 추가하여 증가하는 작업 부하를 수용할 수 있는 능력을 확장성이라고 합니다. 반대로, 내결함성은 기계 고장, 네트워크 분할, 노드 충돌과 같은 오작동에도 불구하고 시스템이 안정적으로 작동할 수 있도록 설계하는 것을 의미합니다.
여러 대의 머신에 걸쳐 분산 애플리케이션의 안정성과 복원력을 보장하기 위해, 분산형 Python 프레임워크에는 종종 내결함성 및 자동 확장 기능이 포함됩니다.
분산 Python의 응용
데이터 처리 및 분석: Apache Spark, Dask 같은 분산 Python 프레임워크를 사용하여 대규모 데이터 세트를 병렬로 처리할 수 있으며, 이를 통해 대량 처리, 실시간 스트림 처리, 대규모 머신러닝 같은 작업을 분산 Python 애플리케이션에서 수행할 수 있게 됩니다.
마이크로서비스를 사용한 웹 개발: Flask, Django 같은 Python 웹 프레임워크를 Celery 같은 분산 작업 대기열과 함께 사용하여 확장 가능한 웹 애플리케이션 및 마이크로서비스 아키텍처를 생성할 수 있습니다. 웹 애플리케이션은 분산 캐싱, 비동기 요청 처리, 백그라운드 작업 처리와 같은 기능을 쉽게 통합할 수 있습니다.
과학 컴퓨팅 및 시뮬레이션: Python의 강력한 과학 라이브러리 및 분산 컴퓨팅 프레임워크 생태계를 통해 고성능 컴퓨팅(HPC)과 머신 클러스터를 이용한 병렬 시뮬레이션이 가능해집니다. 응용 분야에는 금융 위험 분석, 기후 모델링, 머신 러닝 응용 프로그램, 물리학 및 계산 생물학 시뮬레이션 등이 포함됩니다.
엣지 컴퓨팅 및 사물 인터넷(IoT): IoT 장치와 엣지 컴퓨팅 설계가 확산됨에 따라, 센서 데이터 처리, 엣지 컴퓨팅 프로세스 조정, 분산 애플리케이션 구축, 그리고 최신 엣지 애플리케이션에 분산 머신 러닝 모델을 적용하는 데 있어 분산 Python의 중요성이 점점 커지고 있습니다.
분산형 Python의 생성 및 사용
Dask-ML을 활용한 분산 머신러닝
Dask-ML라는 강력한 라이브러리는 머신러닝 관련 작업을 위한 평행 컴퓨팅 프레임워크 Dask을 확장합니다. 여러 대의 머신으로 구성된 클러스터에서 작업을 여러 코어 또는 프로세서에 분산시키면 Python 개발자는 대규모 데이터 세트에 머신 러닝 모델을 학습시키고 적용하는 작업을 효율적으로 분산 방식으로 수행할 수 있습니다.
import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")Ray를 사용한 병렬 함수 호출
강력한 분산 계산 프레임워크 Ray의 도움으로 클러스터의 여러 코어 또는 컴퓨터에서 Python 함수나 작업을 동시에 실행할 수 있습니다. @ray.remote 데코레이터를 이용하여 Ray는 함수들을 원격으로 지정할 수 있도록 합니다. 그 후, 이러한 원격 작업이나 연산은 클러스터의 Ray 워커에서 비동기적으로 실행될 수 있습니다.
import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()시작하기
IronPDF 란 무엇인가요?
.NET 프로그램 내에서 유명한 IronPDF for .NET 패키지를 사용하여, PDF 문서를 생성, 수정 그리고 렌더링할 수 있습니다. PDF를 다루는 방법은 매우 다양합니다. HTML 콘텐츠, 사진 또는 원시 데이터를 사용하여 새 PDF 문서를 만드는 것부터 기존 문서에서 텍스트와 이미지를 추출하고, HTML 페이지를 PDF로 변환하고, 기존 문서에 텍스트, 이미지 및 도형을 추가하는 것까지 가능합니다.
IronPDF의 간단함과 사용 용이성은 그 주요 이점 중 두 가지입니다. 개발자는 사용자 친화적인 API와 방대한 문서 덕분에 .NET 앱 내에서 손쉽게 PDF를 생성할 수 있습니다. IronPDF의 속도와 효율성은 개발자가 고품질 PDF 문서를 신속하게 제작하는데 도움을 주는 또 다른 특징입니다.
IronPDF 의 몇 가지 장점:
- 원본 데이터, 이미지 및 HTML을 사용하여 PDF 생성.
- PDF 파일에서 이미지와 텍스트를 추출합니다.
- PDF 파일에 머리글, 바닥글 및 워터마크를 포함합니다.
- PDF 파일은 비밀번호와 암호화로 보호됩니다.
- 문서를 전자적으로 작성하고 서명할 수 있는 기능.
IronPDF 이용한 분산형 PDF 생성
분산 Python 프레임워크 (예: Dask, Ray) 덕분에 클러스터 내의 여러 코어나 컴퓨터에 작업을 분배할 수 있습니다. 이를 통해 클러스터 전체에서 PDF 생성과 같은 복잡한 작업을 병렬로 실행하고 클러스터 내의 여러 코어를 활용할 수 있으므로 대량의 PDF를 생성하는 데 필요한 시간을 획기적으로 단축할 수 있습니다.
pip를 사용하여 IronPDF와 ray 라이브러리를 설치하면서 시작하세요:
pip install ironpdf celery
분산 PDF 생성에 IronPDF와 Python을 사용하는 두 가지 방법을 설명하는 Python 코드의 개념적 예제입니다:
중앙 작업자를 사용하는 작업 큐
중앙 작업자(worker.py):
from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])클라이언트 스크립트(client.py):
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()Celery는 우리가 사용하는 작업 대기열 시스템입니다. 작업들이 중앙 작업자 (worker.py)로 전송되며 이때 HTML 콘텐츠를 포함한 데이터가 함께 전송됩니다. 이 함수는 IronPDF를 사용하여 PDF를 생성하고 저장합니다.
샘플 데이터를 포함한 작업이 클라이언트 스크립트 (client.py)에 의해 대기열로 전송됩니다. 이 스크립트는 다른 컴퓨터에서 다른 작업을 전송하도록 수정할 수 있습니다.
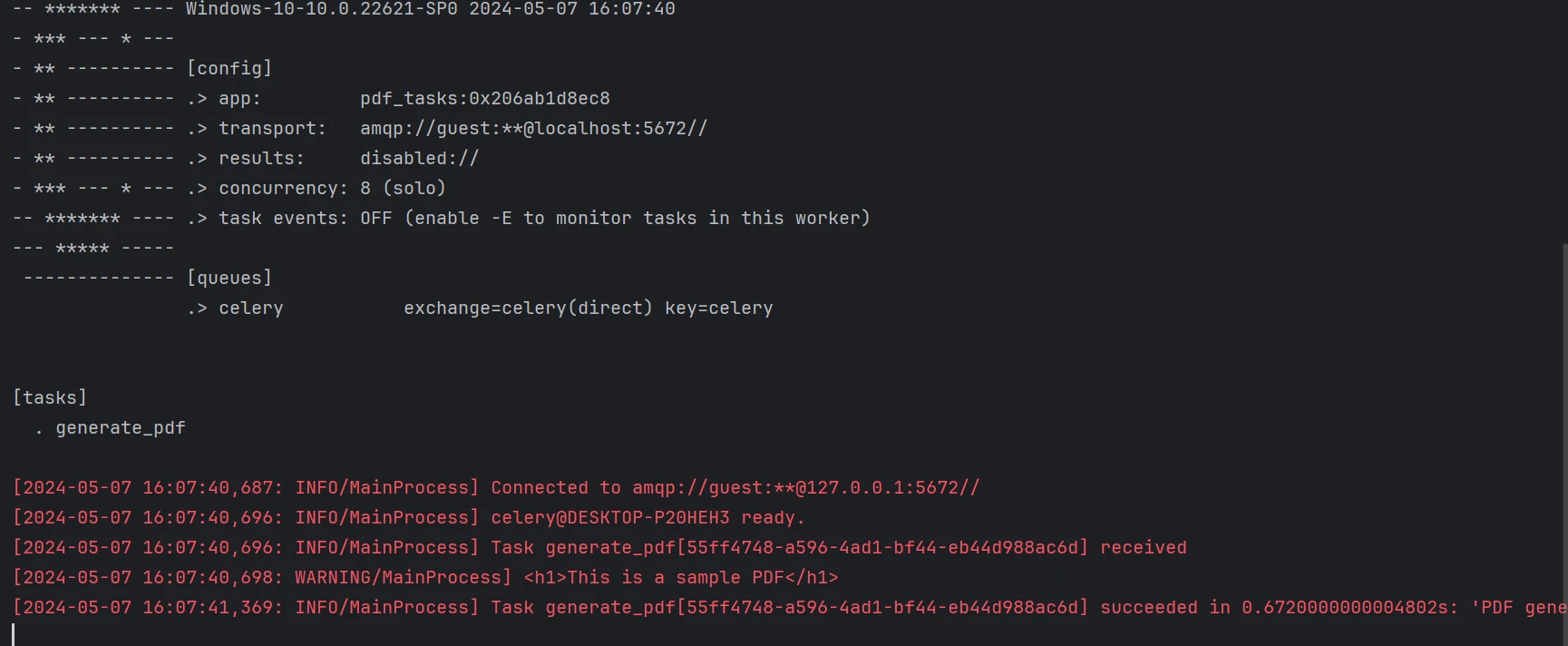
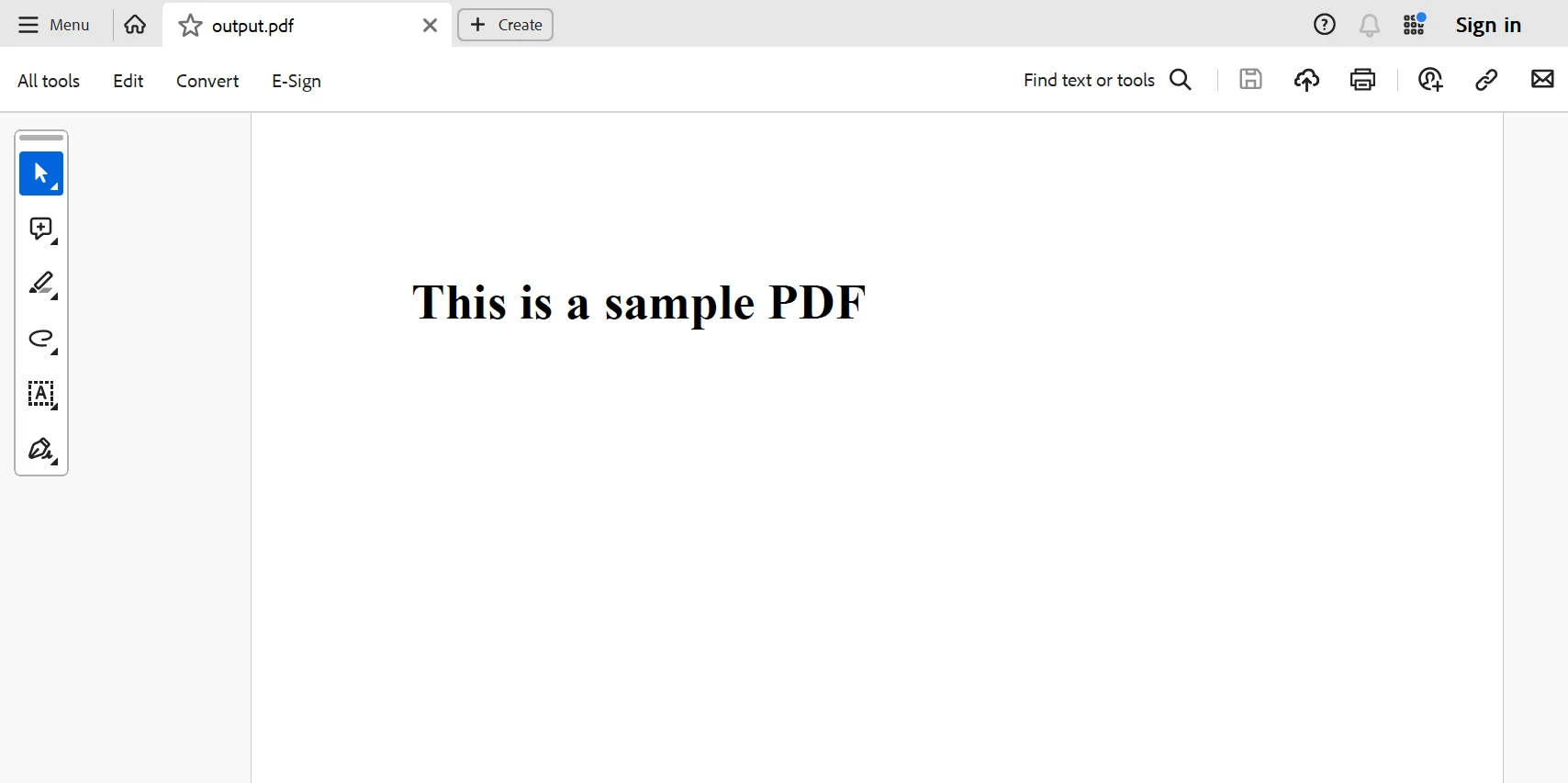
아래는 위 코드에서 생성된 PDF 파일입니다.
결론
대규모 PDF 생성 활동을 처리하는 IronPDF 사용자는 분산 Python 및 Ray 또는 Dask 같은 라이브러리를 활용하여 엄청난 잠재력을 발휘할 수 있습니다. 단일 머신에서 코드를 실행하는 것과 비교했을 때, 동일한 코드 작업 부하를 여러 코어에 분산시키고 여러 머신에서 실행하면 속도를 크게 향상시킬 수 있습니다.
IronPDF은 단일 시스템에서 PDF를 생성하기 위한 강력한 도구에서 분산 Python 프로그래밍 언어를 활용하여 대용량 데이터를 효과적으로 관리할 수 있는 신뢰할 수 있는 솔루션으로 강화될 수 있습니다. 다가오는 대규모 PDF 생성 프로젝트에서 IronPDF을 최대한 활용하려면, 제공되는 Python 라이브러리를 조사하고 이러한 방법을 시도해 보세요!
IronPDF은 패키지로 구매할 경우 합리적인 가격에 제공되며 평생 라이선스가 포함됩니다. 패키지는 뛰어난 가치를 지니며, 많은 시스템에서 단 $999에 구매할 수 있습니다. 라이선스 보유자에게 연중무휴 24시간 온라인 엔지니어링 지원을 제공합니다. 요금에 대한 자세한 내용은 웹사이트를 참조하십시오. Iron Software 에서 생산하는 제품에 대한 자세한 내용은 이 페이지를 참조하십시오.
















