
Verteiltes Rechnen mit Python
Verteiltes Python
Es besteht ein größerer Bedarf als je zuvor an skalierbaren und effektiven Computersetlösungen im sich rasch wandelnden Technologiebereich. Verteiltes Rechnen wird immer notwendiger für Aufgaben, die große Mengen an verteilten Datenverarbeitungen, gleichzeitige Benutzeranfragen und rechnerisch anspruchsvolle Aufgaben umfassen. Um Entwicklern zu ermöglichen, Verteiltes Python vollständig zu nutzen, werden wir in diesem Beitrag seine Anwendungen, Prinzipien und Werkzeuge untersuchen.
Das dynamische Produzieren und Ändern von PDF-Dokumenten ist eine häufige Anforderung im Bereich der Webentwicklung. Die Fähigkeit, programmatisch PDFs zu erstellen, ist nützlich, um Rechnungen, Berichte und Zertifikate spontan zu erstellen.
Die umfassende Ökologie und Vielseitigkeit von Python ermöglicht es, mit einer Vielzahl von PDF-Bibliotheken umzugehen. IronPDF ist eine beeindruckende Lösung, die Entwicklern hilft, ihre Infrastruktur optimal zu nutzen, indem sie den Prozess der PDF-Erstellung optimiert und auch Aufgabenparallelität und verteiltes Rechnen ermöglicht.
Verständnis von Verteiltem Python
Im Wesentlichen ist verteiltes Python der Prozess, Rechenarbeit in kleinere Teile aufzuteilen und diese unter mehreren Knoten oder Verarbeitungseinheiten zu verteilen. Diese Knoten könnten einzelne Maschinen, die mit einem Netzwerk verbunden sind, Einzel-CPU-Kerne innerhalb eines Systems, entfernte Objekte, entfernte Funktionen, entfernte oder Funktionsaufrufausführungen oder sogar einzelne Threads innerhalb eines einzelnen Prozesses sein. Das Ziel ist es, durch Parallelisierung der Arbeitslast die Leistung, Skalierbarkeit und Fehlertoleranz zu erhöhen.
Python ist aufgrund seiner Benutzerfreundlichkeit, Anpassungsfähigkeit und eines robusten Ökosystems von Bibliotheken eine ausgezeichnete Wahl für verteilte Rechenbelastungen. Python bietet eine Fülle von Werkzeugen für verteiltes Rechnen in allen Größenordnungen und Anwendungsfällen, von leistungsstarken Frameworks wie Celery, Dask und Apache Spark bis hin zu integrierten Modulen wie multiprocessing und threading.
Bevor wir uns in die Einzelheiten vertiefen, lassen Sie uns die grundlegenden Ideen und Prinzipien untersuchen, auf denen Verteiltes Python basiert:
Parallelität vs. Gleichzeitigkeit
Parallelität bedeutet, mehrere Aufgaben gleichzeitig auszuführen, während es bei der Gleichzeitigkeit darum geht, viele Aufgaben zu bewältigen, die gleichzeitig voranschreiten können, aber nicht notwendigerweise gleichzeitig ablaufen. Sowohl Parallelität als auch Gleichzeitigkeit werden von Verteiltem Python abgedeckt, abhängig von den zu bearbeitenden Aufgaben und dem Design des Systems.
Aufgabenverteilung
Ein wesentlicher Bestandteil des parallelen und verteilten Rechnens ist die Verteilung von Arbeit auf mehrere Knoten oder Verarbeitungseinheiten. Effektive Arbeitsverteilung ist entscheidend für die Optimierung der Gesamtleistung, Effizienz und Ressourcennutzung, sei es die Parallelisierung der Funktionsausführung in einem Rechenprogramm über mehrere Kerne oder die Aufteilung einer Datenverarbeitungspipeline in kleinere Stufen.
Kommunikation und Koordination
Effektive Kommunikation und Koordination zwischen Knoten sind in verteilten Systemen unerlässlich, um die Orchestrierung entferner Funktionsausführungen, komplexer Workflows, Datenaustausch und Berechnungssynchronisation zu erleichtern.
Verteilte Python-Programme profitieren von Technologien wie Nachrichtenwarteschlangen, verteilte Datenstrukturen und entfernten Prozeduraufrufen (RPC), die eine reibungslose Koordination und Kommunikation zwischen entfernten und tatsächlichen Funktionsausführungen ermöglichen.
Zuverlässigkeit und Fehlervermeidung
Die Fähigkeit eines Systems, wachsende Arbeitslasten zu bewältigen, indem Knoten oder Verarbeitungseinheiten auf verschiedenen Maschinen hinzugefügt werden, wird als Skalierbarkeit bezeichnet. Demgegenüber bezieht sich die Fehlertoleranz auf das Design von Systemen, die Fehlfunktionen wie Maschinenausfälle, Netzwerkausfälle und Knotenabstürze widerstehen und dennoch zuverlässig funktionieren können.
Um die Stabilität und Widerstandsfähigkeit verteilter Anwendungen über mehrere Maschinen hinweg zu gewährleisten, enthalten verteilte Python-Frameworks häufig Fehlertoleranz- und automatische Skalierungsfunktionen.
Anwendungen von Distributed Python
Datenverarbeitung und -analyse: Große Datensätze können parallel mithilfe verteilter Python-Frameworks wie Apache Spark und Dask verarbeitet werden, wodurch es möglich wird, dass verteilte Python-Anwendungen Aktivitäten wie Stapelverarbeitung, Echtzeit-Streamverarbeitung und maschinelles Lernen in großem Umfang durchführen.
Webentwicklung mit Microservices: Skalierbare Webanwendungen und Microservices-Architekturen können mit Python-Webframeworks wie Flask und Django in Verbindung mit verteilten Aufgabenwarteschlangen wie Celery erstellt werden. Webanwendungen können leicht Funktionen wie verteiltes Caching, asynchrone Anfragenbearbeitung und Hintergrundaufgabenverarbeitung integrieren.
Wissenschaftliche Berechnungen und Simulationen: Hochleistungsrechnen (HPC) und parallele Simulationen über Maschinencluster werden durch Pythons robustes Ökosystem wissenschaftlicher Bibliotheken und verteilter Rechenframeworks ermöglicht. Anwendungen umfassen Finanzrisikoanalysen, Klimamodellierung, maschinelles Lernen-Anwendungen und Simulationen von Physik und computergestützter Biologie.
Edge Computing und das Internet der Dinge (IoT): Da IoT-Geräte und Edge-Computing-Designs zunehmen, wird Distributed Python zunehmend wichtig, um Sensordaten zu verarbeiten, Edge-Computing-Prozesse zu koordinieren, verteilte Anwendungen gemeinsam zu erstellen und verteilte maschinelles Lernen-Modelle für moderne Anwendungen am Edge umzusetzen.
Erstellung und Nutzung von Verteiltem Python
Verteiltes maschinelles Lernen mit Dask-ML
Eine leistungsstarke Bibliothek namens Dask-ML erweitert das Parallelrechner-Framework Dask für Aufgaben im Bereich maschinelles Lernen. Das Aufteilen der Aufgabe über mehrere Kerne oder Prozessoren in einem Maschinencluster ermöglicht es Python-Entwicklern, maschinelles Lernmodelle in einer effektiven verteilten Weise auf großen Datensätzen zu trainieren und anzuwenden.
import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")Parallele Funktionsaufrufe mit Ray
Mit Hilfe des robusten Frameworks für verteiltes Rechnen Ray können Sie Python-Funktionen oder -Aufgaben gleichzeitig auf den vielen Kernen oder Computern eines Clusters ausführen. Durch die Verwendung des @ray.remote-Dekorators ermöglicht Ray Ihnen, Funktionen als remote anzugeben. Danach können diese entfernten Aufgaben oder Operationen asynchron auf den Ray-Arbeitern des Clusters ausgeführt werden.
import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()Einstieg
Was ist IronPDF?
Mit Hilfe des bekannten IronPDF for .NET Pakets können wir PDF-Dokumente innerhalb von .NET -Programmen erstellen, ändern und darstellen. Auf PDF-Dateien kann auf verschiedene Weisen gearbeitet werden: durch das Erstellen neuer PDF-Dokumente aus HTML-Inhalten, Fotografien oder Rohdaten, das Extrahieren von Text und Bildern aus bestehenden, das Konvertieren von HTML-Seiten in PDFs und das Hinzufügen von Text, Bildern und Formen zu bestehenden.
Die Einfachheit und Benutzerfreundlichkeit von IronPDF sind zwei seiner Hauptvorteile. Entwickler können dank seiner benutzerfreundlichen API und umfangreiche Dokumentation problemlos PDFs innerhalb ihrer .NET-Apps erstellen. Die Geschwindigkeit und Effizienz von IronPDF sind zwei weitere Merkmale, die es Entwicklern erleichtern, schnell qualitativ hochwertige PDF-Dokumente zu erstellen.
Einige Vorteile von IronPDF:
- Erstellung von PDFs aus Rohdaten, Bildern und HTML.
- Extrahieren von Bildern und Text aus PDF-Dateien.
- Kopf-, Fußzeilen sowie Wasserzeichen in PDF-Dateien einfügen.
- PDF-Dateien sind passwort- und verschlüsselungsgeschützt.
- Die Möglichkeit, Dokumente elektronisch auszufüllen und zu unterschreiben.
Verteilte PDF-Erstellung mit IronPDF
Die Verteilung von Aufgaben auf zahlreiche Kerne oder Computer innerhalb eines Clusters wird durch verteilte Python-Frameworks wie Dask und Ray ermöglicht. Dies ermöglicht es, komplexe Aufgaben wie die Erstellung von PDFs parallel über einen Cluster auszuführen und mehrere Kerne innerhalb dieser Cluster zu nutzen, was die Zeit, die benötigt wird, um eine große Menge an PDFs zu erstellen, erheblich verkürzt.
Beginnen Sie mit der Installation von IronPDF und der ray Bibliothek mit pip:
pip install ironpdf
pip install celerypip install ironpdf
pip install celeryHier ist ein konzeptioneller Python-Code, der zwei Methoden mit IronPDF und Python zur verteilten PDF-Generierung demonstriert:
Aufgabenwarteschlange mit einem zentralen Arbeiter
Zentraler Arbeiter (worker.py):
from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])Client-Skript (client.py):
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()Celery ist das von uns verwendete Aufgabenwarteschlangensystem. Die Aufträge werden zusammen mit Daten, die HTML-Inhalte enthalten, an den zentralen Worker (worker.py) gesendet. Die Funktion erstellt ein PDF mit IronPDF und speichert es.
Ein Task mit Beispieldaten wird vom Client-Skript (client.py) an die Warteschlange gesendet. Dieses Skript kann geändert werden, um andere Aufgaben von verschiedenen Computern aus zu senden.
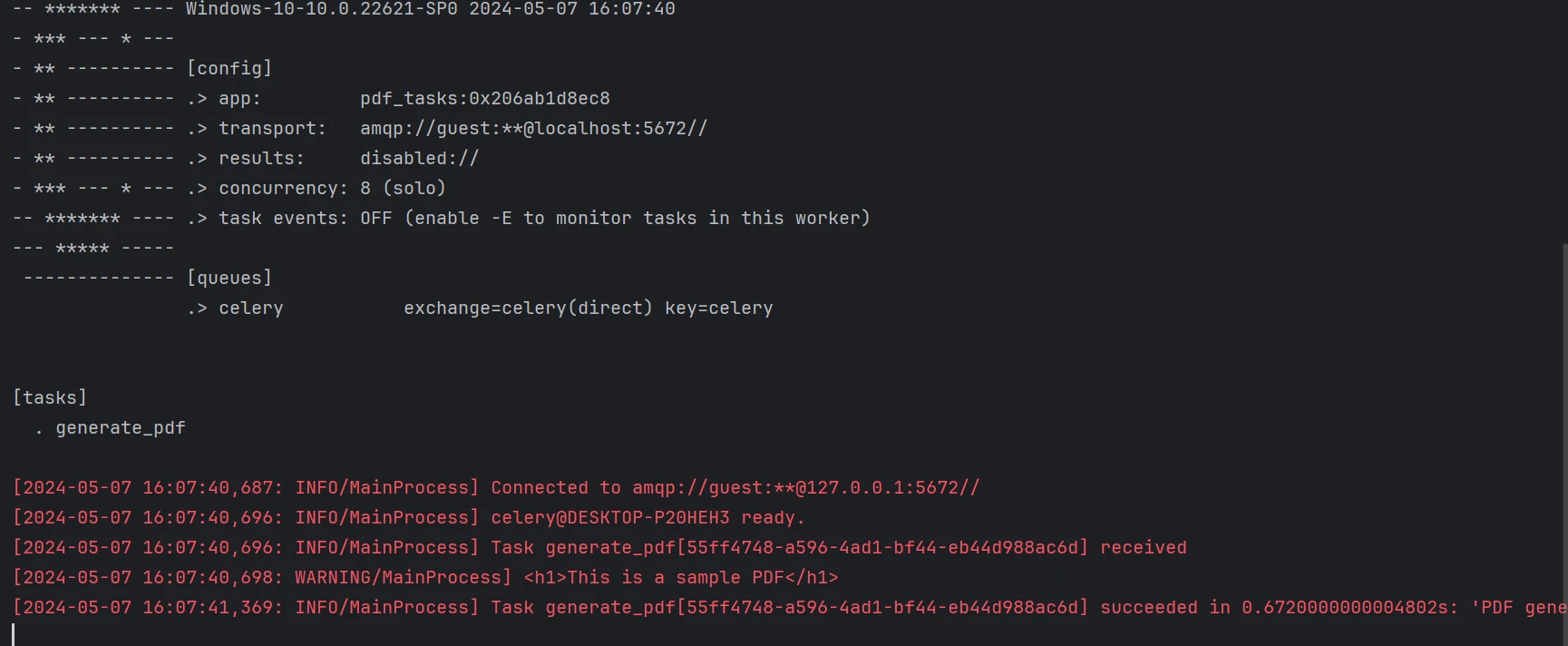
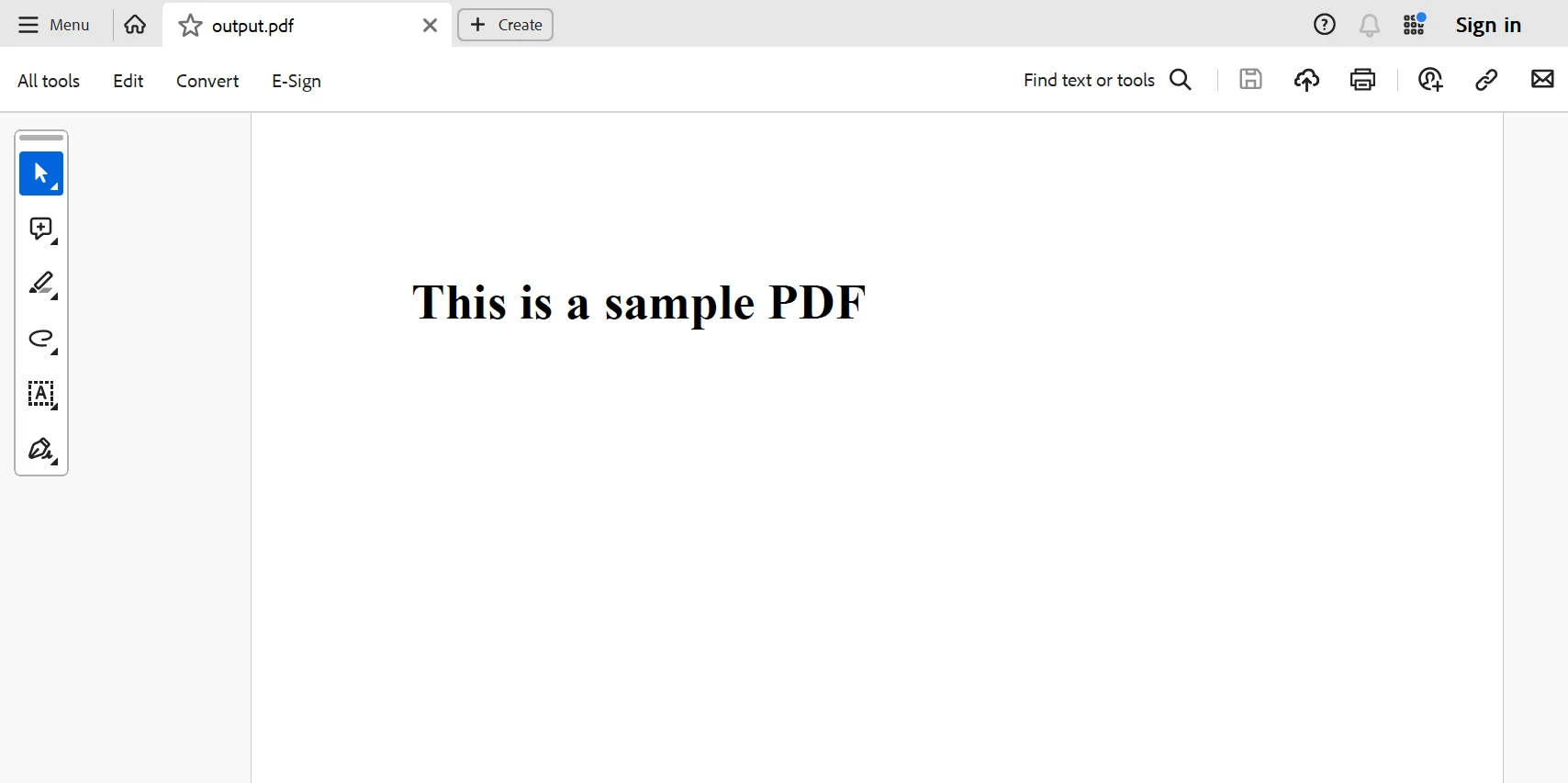
Unten ist das aus dem obigen Code erstellte PDF.
Abschluss
Anwender von IronPDF, die mit der Erstellung von PDFs in großem Umfang befasst sind, könnten ein enormes Potenzial ausschöpfen, indem sie verteiltes Python und Bibliotheken wie Ray oder Dask nutzen. Im Vergleich zum Ausführen von Code auf einer einzelnen Maschine können Sie erhebliche Geschwindigkeitsverbesserungen erzielen, indem Sie die gleiche Codelast über mehrere Kerne verteilen und auf mehreren Maschinen verwenden.
IronPDF kann von einem leistungsstarken Werkzeug zur Erstellung von PDFs auf einem einzelnen System zu einer zuverlässigen Lösung für die effektive Verwaltung großer Datensätze durch die Nutzung der verteilten Programmiersprache Python erweitert werden. Um IronPDF in Ihrem bevorstehenden groß angelegten PDF-Erstellungsprojekt optimal zu nutzen, sollten Sie die angebotenen Python-Bibliotheken untersuchen und diese Methoden ausprobieren!
IronPDF ist im Paket preisgünstig und beinhaltet eine lebenslange Lizenz. Das Paket bietet ein hervorragendes Preis-Leistungs-Verhältnis und kann für viele Systeme bereits ab $999 erworben werden. Es bietet Rund-um-die-Uhr-Onlinesupport für Lizenzinhaber. Für weitere Informationen zu den Kosten besuchen Sie bitte die Website. Um mehr über die von Iron Software produzierten Produkte zu erfahren, gehen Sie auf diese Seite.
















