
Python Requests-Bibliothek (Wie es für Entwickler funktioniert)
Python wird aufgrund seiner Einfachheit und Lesbarkeit hoch geschätzt und ist daher bei Entwicklern für Web-Scraping und die Interaktion mit APIs sehr beliebt. Eine der wichtigsten Bibliotheken, die solche Interaktionen ermöglicht, ist die Python-Bibliothek Requests. Requests ist eine HTTP-Anfragebibliothek für Python, mit der Sie HTTP-Anfragen unkompliziert senden können. In diesem Artikel werden wir die Funktionen der Python-Bibliothek Requests näher betrachten, ihre Verwendung anhand praktischer Beispiele untersuchen und IronPDF vorstellen. Wir zeigen, wie diese Bibliothek mit Requests kombiniert werden kann, um PDFs aus Webdaten zu erstellen und zu bearbeiten.
Einführung in die Requests Bibliothek
Die Python-Bibliothek Requests wurde entwickelt, um HTTP-Anfragen einfacher und benutzerfreundlicher zu gestalten. Sie abstrahiert die Komplexität der Anfragen hinter einer einfachen API, sodass Sie sich auf die Interaktion mit Diensten und Daten im Web konzentrieren können. Egal ob Sie Webseiten abrufen, mit REST-APIs interagieren, die SSL-Zertifikatsprüfung deaktivieren oder Daten an einen Server senden müssen, die Requests Bibliothek bietet Ihnen alles, was Sie brauchen.
Hauptmerkmale
- Einfachheit: Leicht zu verwendende und verständliche Syntax.
- HTTP-Methoden: Unterstützt alle HTTP-Methoden - GET, POST, PUT, DELETE usw.
- Sitzungsobjekte: Speichern Cookies über mehrere Anfragen hinweg.
- Authentifizierung: Vereinfacht das Hinzufügen von Authentifizierungsheadern.
- Proxys: Unterstützung für HTTP-Proxys.
- Timeouts: Verwaltet Anfrage-Timeouts effektiv.
- SSL-Verifizierung: Überprüft standardmäßig SSL-Zertifikate.
Installation von Requests
Um Requests nutzen zu können, müssen Sie es installieren. Dies kann mit Pip erfolgen:
pip install requestspip install requestsGrundlegende Verwendung
Hier ist ein einfaches Beispiel, wie man mit Requests eine Webseite abruft:
import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)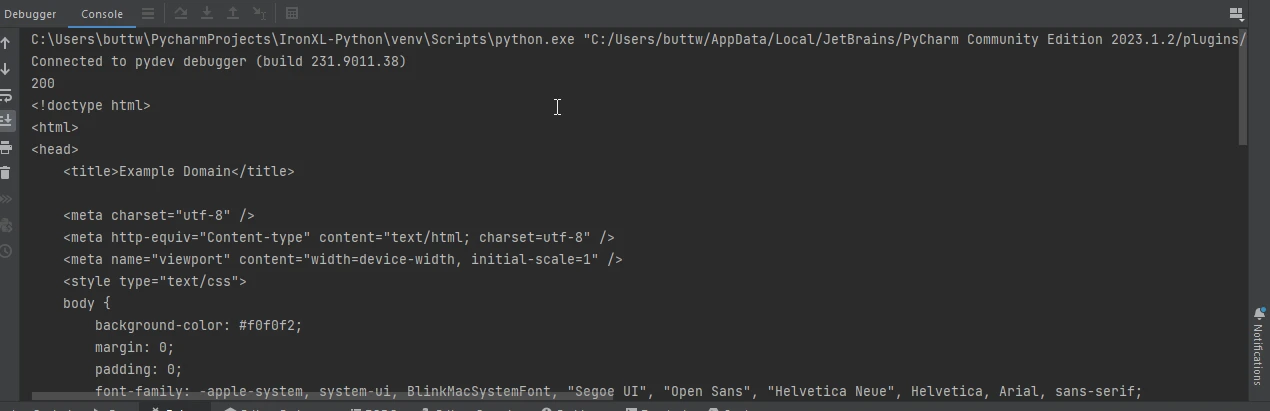
Senden von Parametern in URLs
Oft müssen Sie Parameter an die URL übergeben. Das Python-Modul Requests vereinfacht dies mit dem Schlüsselwort params:
import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)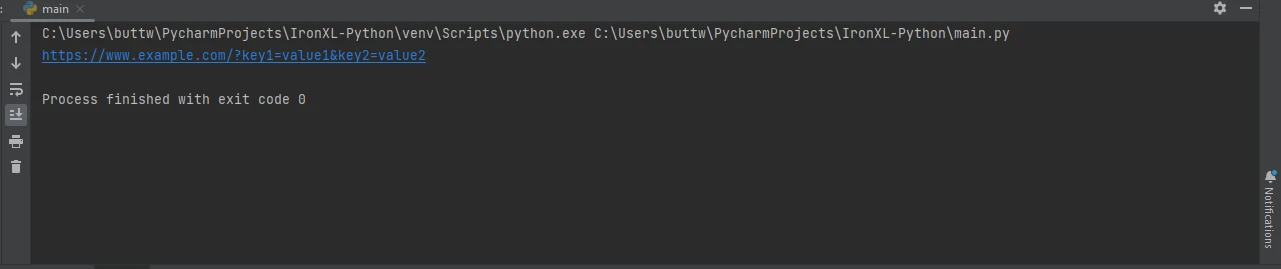
Umgang mit JSON-Daten
Die Interaktion mit APIs umfasst normalerweise JSON-Daten. Requests vereinfacht dies durch integrierte JSON-Unterstützung:
import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)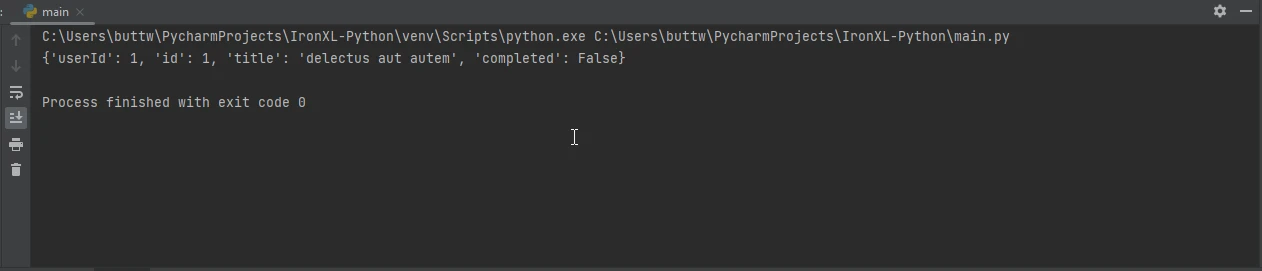
Arbeiten mit Headern
Header sind entscheidend für HTTP-Anfragen. Sie können benutzerdefinierte Header zu Ihren Anfragen hinzufügen, wie folgt:
import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)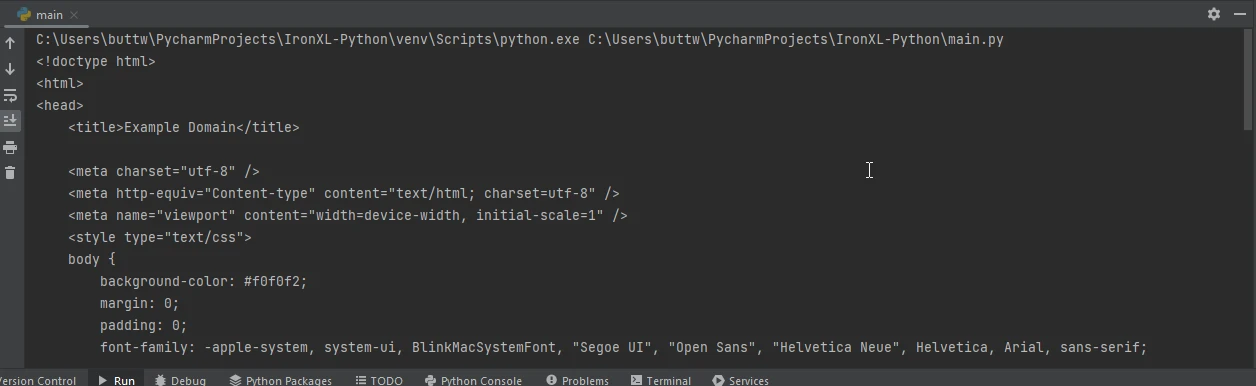
Datei-Uploads
Requests unterstützt auch Datei-Uploads. So laden Sie eine Datei hoch:
import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)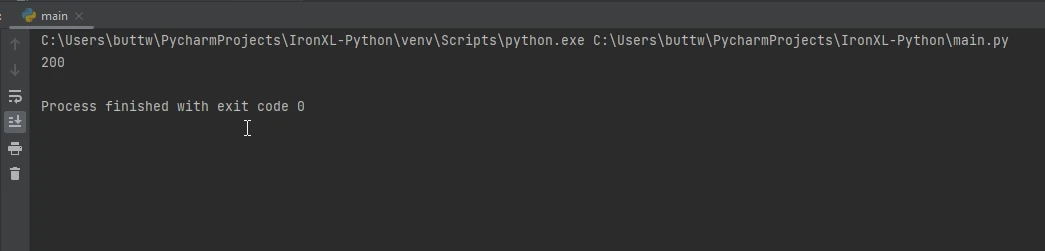
Einführung von IronPDF for Python
IronPDF ist eine vielseitige Bibliothek zur PDF-Erstellung, die verwendet werden kann, um PDFs innerhalb Ihrer Python-Anwendungen zu erstellen, zu bearbeiten und zu manipulieren. Es ist besonders nützlich, wenn Sie PDFs aus HTML-Inhalten erzeugen müssen, was es zu einem großartigen Werkzeug für die Erstellung von Berichten, Rechnungen oder jede andere Art von Dokument macht, das in einem portablen Format verteilt werden muss.
Installation von IronPDF
Installieren Sie IronPDF mit pip:
pip install ironpdf
Verwendung von IronPDF mit Requests
Die Kombination von Requests und IronPDF ermöglicht es Ihnen, Daten aus dem Web abzurufen und direkt in PDF-Dokumente umzuwandeln. Dies kann besonders nützlich sein, um Berichte aus Webdaten zu erstellen oder Webseiten als PDFs zu speichern.
Hier ist ein Beispiel, wie man mit Requests eine Webseite abruft und sie anschließend mit IronPDF als PDF speichert:
import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
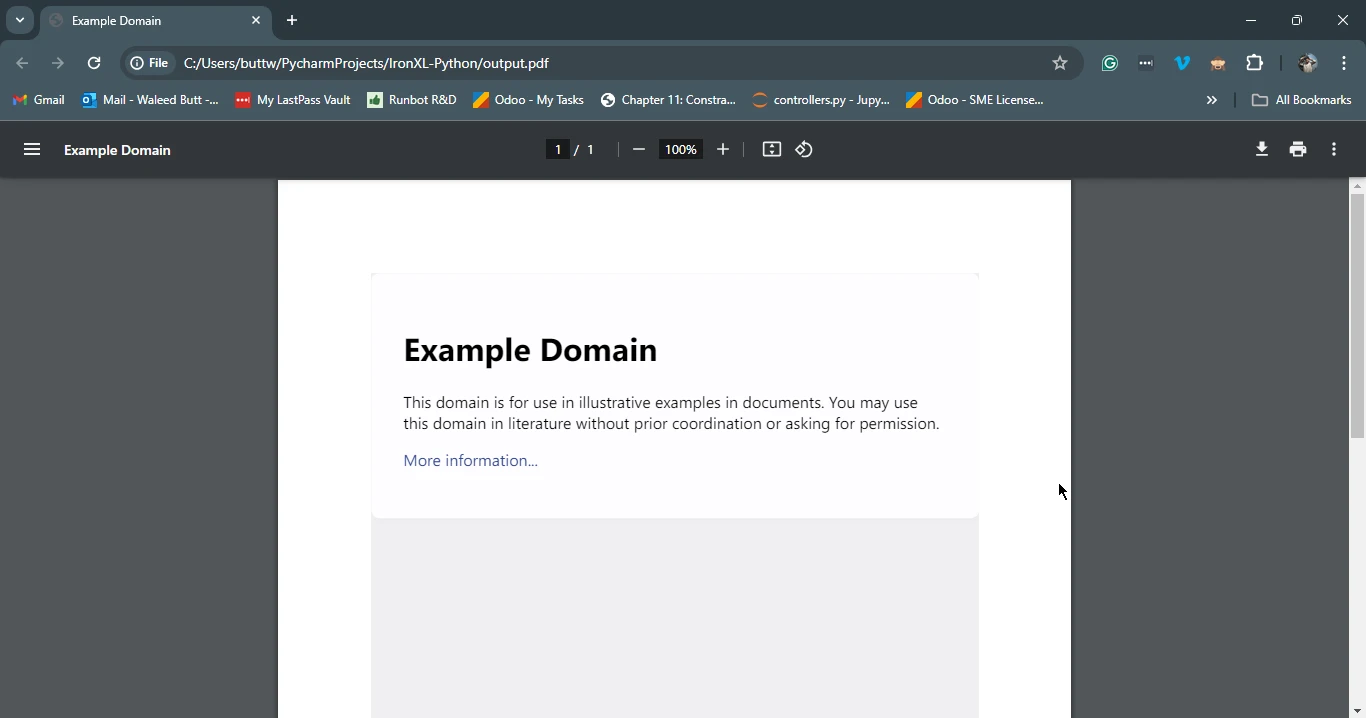
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')Dieses Skript ruft zunächst den HTML-Inhalt der angegebenen URL mit Requests ab. Anschließend verwendet es IronPDF, um den HTML-Inhalt dieses Antwortobjekts in ein PDF umzuwandeln und das resultierende PDF in einer Datei zu speichern.
Abschluss
Die Bibliothek Requests ist ein unverzichtbares Werkzeug für jeden Python-Entwickler, der mit Web-APIs interagieren muss. Ihre Einfachheit und Benutzerfreundlichkeit machen sie zur ersten Wahl für HTTP-Anfragen. In Kombination mit IronPDF ergeben sich noch mehr Möglichkeiten, indem Sie Daten aus dem Web abrufen und in professionelle PDF-Dokumente umwandeln können. Egal ob Sie Berichte, Rechnungen erstellen oder Webinhalte archivieren, die Kombination aus Requests und IronPDF bietet eine leistungsstarke Lösung für Ihre PDF-Generierungsanforderungen.
Weitere Informationen zur IronPDF-Lizenzierung finden Sie auf der IronPDF-Lizenzseite. Sie können auch unser ausführliches Tutorial zur HTML- in PDF-Konvertierung für weitere Einblicke erkunden.
















