
xml.etree Python (Wie es für Entwickler funktioniert)
XML (eXtensible Markup Language) ist ein beliebtes und flexibles Format zur Darstellung strukturierter Daten in der Datenverarbeitung und Dokumentengenerierung. Die Standardbibliothek enthält xml.etree, eine Python-Bibliothek, die Entwicklern eine leistungsstarke Reihe von Werkzeugen zum Parsen oder Erstellen von XML-Daten, zum Manipulieren von Kindelementen und zum programmgesteuerten Generieren von XML-Dokumenten bietet.
In Kombination mit IronPDF, einer .NET Bibliothek zum Erstellen und Bearbeiten von PDF-Dokumenten, können Entwickler die kombinierten Fähigkeiten von xml.etree und IronPDF nutzen, um die Verarbeitung von XML-Elementobjektdaten und die dynamische PDF-Dokumentgenerierung zu beschleunigen. In diesem ausführlichen Leitfaden tauchen wir in die Welt von xml.etree Python ein, erkunden seine wichtigsten Merkmale und Funktionen und zeigen Ihnen, wie Sie es mit IronPDF integrieren können, um neue Möglichkeiten in der Datenverarbeitung zu erschließen.
Was ist xml.etree?
xml.etree ist Teil der Standardbibliothek von Python. Es hat das Suffix .etree, auch ElementTree genannt, und bietet eine unkomplizierte und effektive ElementTree XML API zur Verarbeitung und Änderung von XML-Dokumenten. Es ermöglicht Programmierern, mit XML-Daten in einer hierarchischen Baumstruktur zu arbeiten, was die Navigation, Änderung und programmgesteuerte Generierung von XML-Dateien vereinfacht.
Obwohl es leichtgewichtig und einfach zu bedienen ist, bietet xml.etree eine starke Funktionalität für die Verarbeitung von XML-Root-Element-Daten. Es bietet eine Möglichkeit, XML-Daten-Dokumente aus Dateien, Zeichenfolgen oder Dingen, die Dateien ähneln, zu parsen. Die resultierende geparste XML-Datei wird als Baumstruktur von Element-Objekten angezeigt. Danach können Entwickler durch diesen Baum navigieren, auf Elemente und Attribute zugreifen und verschiedene Aktionen wie Bearbeiten, Entfernen oder Hinzufügen von Elementen ausführen.

Merkmale von xml.etree
Parsen von XML-Dokumenten
Methoden zum Parsen von XML-Dokumenten aus Zeichenketten, Dateien oder dateiähnlichen Objekten sind in xml.etree verfügbar. XML-Material kann mit Hilfe der Funktion parse() verarbeitet werden, die auch ein ElementTree-Objekt erzeugt, das das geparste XML-Dokument mit einem gültigen Element-Objekt repräsentiert.
Navigation von XML-Bäumen
Entwickler können xml.etree verwenden, um die Elemente eines XML-Baums mithilfe von Funktionen wie find(), findall() und iter() zu durchlaufen, sobald das Dokument verarbeitet wurde. Der Zugriff auf bestimmte Elemente basierend auf Tags, Attributen oder XPath-Ausdrücken wird durch diese Ansätze erleichtert.
Änderung von XML-Dokumenten
Innerhalb eines XML-Dokuments gibt es Möglichkeiten, Komponenten und Attribute mithilfe von xml.etree hinzuzufügen, zu bearbeiten und zu entfernen. Das programmgesteuerte Ändern des inhärent hierarchischen Datenformats, der Struktur und des Inhalts des XML-Baums ermöglicht Datenmodifikationen, Aktualisierungen und Transformationen.
Serialisierung von XML-Dokumenten
xml.etree ermöglicht die Serialisierung von XML-Bäumen in Zeichenketten oder dateiähnliche Objekte mithilfe von Funktionen wie ElementTree.write() nach der Modifizierung eines XML-Dokuments. Dies ermöglicht es Entwicklern, XML-Bäume zu erstellen oder zu bearbeiten und daraus XML-Ausgaben zu erzeugen.
XPath-Unterstützung
Unterstützung für XPath, eine Abfragesprache zum Auswählen von Knoten aus einem XML-Dokument, wird durch xml.etree bereitgestellt. Entwickler können komplexe Datenabruf- und Manipulationsaktivitäten durchführen, indem sie XPath-Ausdrücke verwenden, um Elemente innerhalb eines XML-Baums abzufragen und zu filtern.
Iteratives Parsen
Anstatt das gesamte Dokument auf einmal in den Speicher zu laden, können Entwickler XML-Dokumente dank der Unterstützung für iteratives Parsen in xml.etree sequenziell verarbeiten. Dies ist sehr hilfreich für eine effektive Verwaltung großer XML-Dateien.
Namespace-Unterstützung
Entwickler können mit XML-Dokumenten arbeiten, die Namensräume zur Element- und Attributidentifizierung verwenden, indem sie die Unterstützung für XML-Namensräume von xml.etree nutzen. Es bietet Möglichkeiten, Standard-XML-Namespace-Präfixe aufzulösen und Namespaces innerhalb eines XML-Dokuments zu spezifizieren.
Fehlerbehandlung
Fehlerbehandlungsfunktionen für fehlerhafte XML-Dokumente und Parsing-Fehler sind in xml.etree enthalten. Es bietet Techniken zur Fehlerverwaltung und Erfassung, was Zuverlässigkeit und Robustheit bei der Arbeit mit XML-Daten garantiert.
Kompatibilität und Portabilität
Da xml.etree eine Komponente der Python-Standardbibliothek ist, kann sie sofort in Python-Programmen verwendet werden, ohne dass weitere Installationen erforderlich sind. Es ist portabel und kompatibel mit vielen Python-Einstellungen, da es sowohl mit Python 2 als auch Python 3 funktioniert.
Erstellen und Konfigurieren xml.etree
Ein XML-Dokument erstellen
Durch das Erstellen von Objekten, die die Elemente des importierten XML-Baums darstellen, und deren Anhängen an ein Wurzelelement können Sie ein XML-Dokument erstellen. Dies ist ein Beispiel, wie man XML-Daten erstellt:
import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Parent element
book1 = ET.SubElement(root, "book")
# Set attribute for book1
book1.set("id", "1")
# Child elements for book1
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Parent element
book2 = ET.SubElement(root, "book")
# Set attribute for book2
book2.set("id", "2")
# Child elements for book2
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create ElementTree object
tree = ET.ElementTree(root)import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Parent element
book1 = ET.SubElement(root, "book")
# Set attribute for book1
book1.set("id", "1")
# Child elements for book1
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Parent element
book2 = ET.SubElement(root, "book")
# Set attribute for book2
book2.set("id", "2")
# Child elements for book2
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create ElementTree object
tree = ET.ElementTree(root)XML-Dokument in Datei schreiben
Die Funktion write() des Objekts ElementTree kann zum Schreiben der XML-Datei verwendet werden:
# Write XML document to file
tree.write("catalog.xml")# Write XML document to file
tree.write("catalog.xml")Das XML-Dokument wird in einer Datei mit dem Namen "catalog.xml" erstellt.
Ein XML-Dokument parsen
Die ElementTree parst XML-Daten mithilfe der Funktion parse():
# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()Das XML-Dokument "catalog.xml" wird auf diese Weise geparst, wobei das Wurzelelement des XML-Baums hervorgeht.
Elemente und Attribute zugreifen
Mithilfe einer Vielzahl von Techniken und Funktionen, die von Element-Objekten angeboten werden, können Sie auf die Elemente und Attribute des XML-Dokuments zugreifen. Um beispielsweise den Titel des ersten Buches anzuzeigen:
# Reading single XML element
first_book_title = root[0].find("title").text
print("Title of first book:", first_book_title)# Reading single XML element
first_book_title = root[0].find("title").text
print("Title of first book:", first_book_title)XML-Dokument ändern
Das XML-Dokument kann durch Hinzufügen, Ändern oder Löschen von Komponenten und Attributen verändert werden. Um beispielsweise den Autor des zweiten Buches zu ändern:
# Modify XML document
root[1].find("author").text = "Alice Smith"# Modify XML document
root[1].find("author").text = "Alice Smith"XML-Dokument serialisieren
Die Funktion ElementTree des Moduls tostring() kann verwendet werden, um das XML-Dokument in eine Zeichenkette zu serialisieren:
# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)Einstieg mit IronPDF
Was ist IronPDF?
IronPDF ist eine leistungsstarke .NET-Bibliothek zur programmgesteuerten Erstellung, Bearbeitung und Änderung von PDF-Dokumenten in C#, VB.NET und anderen .NET-Sprachen. Da es Entwicklern eine breite Funktionspalette zum dynamischen Erstellen von hochwertigen PDFs bietet, ist es eine beliebte Wahl für viele Programme.
Wichtige Funktionen von IronPDF
PDF-Generierung:
Mit IronPDF können Programmierer neue PDF-Dokumente erstellen oder bestehendeHTML-Tags, Text, Bilder und andere Dateiformate in PDFs umwandeln. Diese Funktion ist sehr nützlich für die dynamische Erstellung von Berichten, Rechnungen, Quittungen und anderen Dokumenten.
HTML-zu-PDF-Konvertierung:
IronPDF macht es Entwicklern einfach, HTML-Dokumente, einschließlich Stile aus JavaScript und CSS, in PDF-Dateien umzuwandeln. Dies ermöglicht die Erstellung von PDFs aus Webseiten, dynamisch generierten Inhalten und HTML-Vorlagen.
Änderung und Bearbeitung von PDF-Dokumenten:
IronPDF bietet eine umfassende Funktionsvielfalt zur Änderung und Bearbeitung bereits bestehender PDF-Dokumente. Entwickler können mehrere PDF-Dateien zusammenführen, sie in andere Dokumente aufteilen, Seiten entfernen und Lesezeichen, Anmerkungen und Wasserzeichen hinzufügen, unter anderem, um PDFs an ihre Anforderungen anzupassen.
IronPDF und xml.etree Kombiniert
Der nächste Abschnitt zeigt, wie PDF-Dokumente mit IronPDF basierend auf geparsten XML-Daten generiert werden können. Das zeigt, dass Sie durch die Nutzung der Stärken von sowohl XML als auch IronPDF strukturierten Daten effizient in professionelle PDF-Dokumente transformieren können. Hier ist eine detaillierte Anleitung:
Installation
Stellen Sie sicher, dass IronPDF installiert ist, bevor Sie beginnen. Es kann mit pip installiert werden:
pip install IronPdfpip install IronPdfPDF-Dokument mit IronPDF unter Verwendung von geparstem XML generieren
IronPDF kann verwendet werden, um basierend auf den Daten, die Sie aus dem XML extrahiert haben, nach der Verarbeitung ein PDF-Dokument zu erstellen. Lassen Sie uns ein PDF-Dokument mit einer Tabelle erstellen, die die Buchnamen und Autoren enthält:
from ironpdf import *
# Sample parsed XML books data
books = [
{'title': 'Python Programming', 'author': 'John Smith'},
{'title': 'Data Science Essentials', 'author': 'Jane Doe'}
]
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Iterate over books to add each book's data to the HTML table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
# Close the table and body tags
html_content += """
</table>
</body>
</html>
"""
# Generate and save the PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")from ironpdf import *
# Sample parsed XML books data
books = [
{'title': 'Python Programming', 'author': 'John Smith'},
{'title': 'Data Science Essentials', 'author': 'Jane Doe'}
]
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Iterate over books to add each book's data to the HTML table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
# Close the table and body tags
html_content += """
</table>
</body>
</html>
"""
# Generate and save the PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
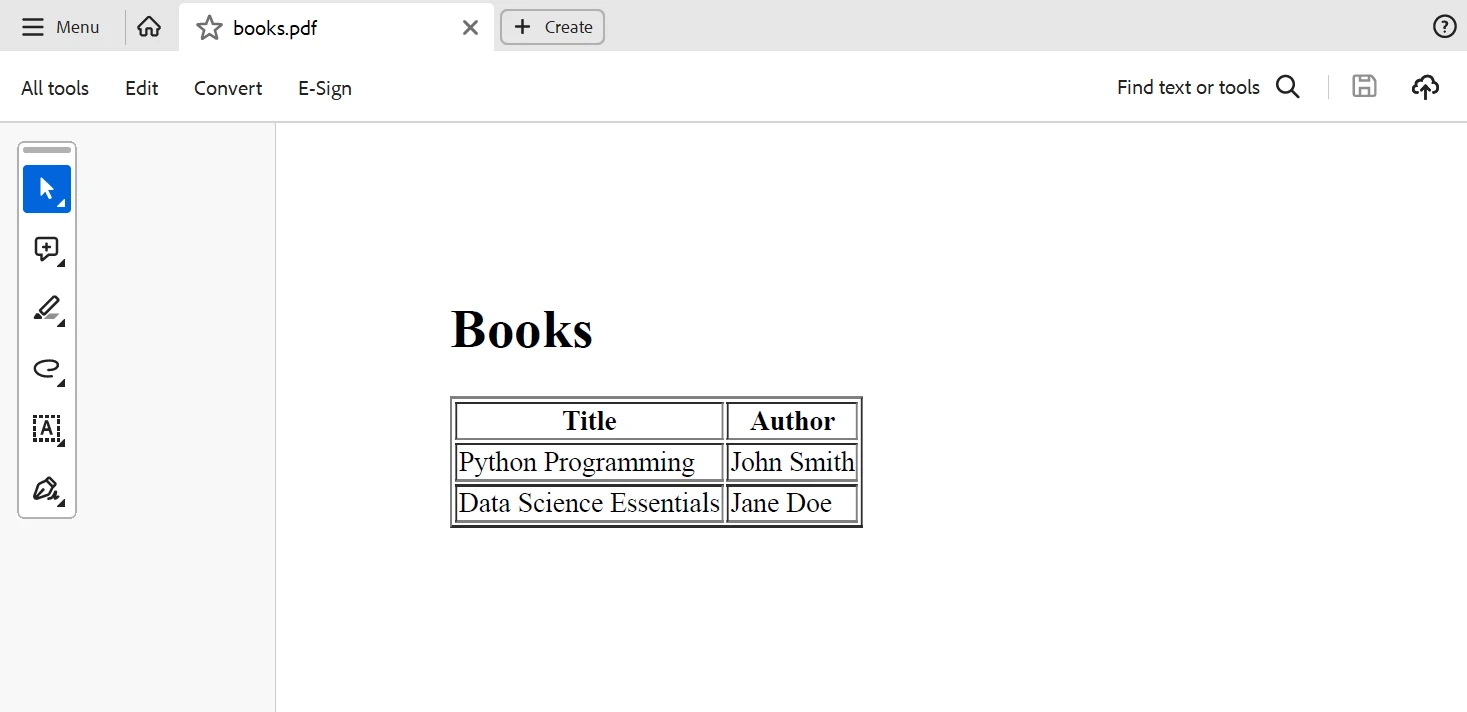
pdf.SaveAs("books.pdf")Dieser Python-Code generiert eine HTML-Tabelle mit den Buchtiteln und Autoren, die IronPDF dann in ein PDF-Dokument umwandelt. Unten ist die Ausgabe von dem obigen Code dargestellt.
Ausgabe
Abschluss
Zusammenfassend lässt sich sagen, dass Entwickler, die XML-Daten parsen und auf Basis der geparsten Daten dynamische PDF-Dokumente erstellen möchten, in der Kombination von IronPDF und xml.etree Python eine leistungsstarke Lösung finden werden. Mithilfe der zuverlässigen und effektiven xml.etree Python-API können Entwickler auf einfache Weise strukturierte Daten aus XML-Dokumenten extrahieren. IronPDF ergänzt dies jedoch durch die Möglichkeit, ästhetisch ansprechende und bearbeitbare PDF-Dokumente aus den verarbeiteten XML-Daten zu erstellen.
Gemeinsam ermöglichen Python und IronPDF Entwicklern, Datenverarbeitungsaufgaben zu automatisieren, wertvolle Erkenntnisse aus XML-Datenquellen zu gewinnen und diese Professional und visuell ansprechend in PDF-Dokumenten darzustellen. Ob es um die Erstellung von Berichten, Rechnungen oder Dokumentationen geht, die Synergie zwischen xml.etree Python und IronPDF eröffnet neue Möglichkeiten in der Datenverarbeitung und Dokumentenerstellung.
IronPDF umfasst eine lebenslange Lizenz, die im Bundle recht günstig ist. Das Bundle bietet ein hervorragendes Preis-Leistungs-Verhältnis und kostet nur $999 (einmaliger Kauf für mehrere Systeme). Lizenzinhaber haben 24/7 Zugang zu technischem Online-Support. Für weitere Informationen zu den Gebühren gehen Sie bitte auf diese Website. Besuchen Sie diese Seite, um mehr über die Produkte von Iron Software zu erfahren.
















