
xml.etree Python(開発者向けのしくみ)
XML(eXtensible Markup Language)は、データ処理とドキュメント生成で構造化データを表現するための人気があり柔軟なフォーマットです。 標準ライブラリには、開発者が XML データの解析や作成、子要素の操作、プログラムによる XML ドキュメントの生成を行うための強力なツールセットを提供する Python ライブラリである xml.etree が含まれています。
PDF ドキュメントの作成と編集を行う.NETライブラリであるIronPDFと組み合わせることで、開発者は xml.etree とIronPDFの複合機能を活用して、XML 要素オブジェクトデータの処理と動的な PDF ドキュメントの生成を高速化できます。 この詳細なガイドでは、Python の世界を掘り下げ、その主な機能と特性を探求し、 IronPDFと統合してデータ処理の新たな可能性を解き放つ方法を紹介します。
xml.etreeとは何ですか?
xml.etreeは Python の標準ライブラリの一部です。 これは、.etree という接尾辞を持ち、ElementTree とも呼ばれ、XML ドキュメントの処理と変更のためのシンプルで効果的な ElementTree XML API を提供します。 プログラマーがXMLデータを階層的なツリー構造で操作し、XMLファイルのナビゲーション、修正、プログラムでの生成を簡素化します。
軽量で使いやすいにもかかわらず、xml.etree は XML ルート要素データを処理するための強力な機能を提供します。 ファイル、文字列、またはファイルに似たものからXMLデータドキュメントを解析する方法を提供します。 結果として得られる解析済み XML ファイルは、Element オブジェクトのツリーとして表示されます。 その後、開発者はこのツリーをナビゲートし、要素や属性にアクセスし、編集、削除、追加などのさまざまな操作を実行できます。

xml.etree の特徴
XMLドキュメントの解析
文字列、ファイル、またはファイルライクオブジェクトから XML ドキュメントを解析する方法は、xml.etree で利用できます。 XML 素材は parse() 関数を使用して処理できます。この関数は、解析された XML ドキュメントを有効な Element オブジェクトで表す ElementTree オブジェクトも生成します。
XMLツリーのナビゲーション
開発者は、ドキュメントが処理された後、xml.etreeを使用してXMLツリーの要素を走査できます。 タグ、属性、XPath式に基づいて特定の要素にアクセスすることが簡単に行えます。
XMLドキュメントの修正
XML ドキュメント内では、xml.etree を使用してコンポーネントと属性を追加、編集、削除する方法があります。 XMLツリーの本質的に階層的なデータ形式、構造、およびコンテンツをプログラムで変更することにより、データの変更、更新、変換を可能にします。
XMLドキュメントのシリアル化
xml.etree は、XML ドキュメントを変更した後、ElementTree.write() のような関数を使用して、XML ツリーを文字列またはファイルのようなオブジェクトにシリアル化することを可能にします。 これにより、開発者はXMLツリーを作成または変更し、そこからXML出力を生成することが可能になります。
XPathのサポート
XML ドキュメントからノードを選択するためのクエリ言語である XPath のサポートは、xml.etree によって提供されます。 開発者はXPath式を使用してXMLツリー内のアイテムをクエリし、フィルタリングすることで、複雑なデータ取得および操作活動を行うことができます。
反復解析
xml.etree の反復解析のサポートにより、開発者はドキュメント全体を一度にメモリに読み込む代わりに、XML ドキュメントを順次処理できます。 これにより、大きなXMLファイルを効率的に管理するのに役立ちます。
名前空間のサポート
開発者は、xml.etree の XML 名前空間のサポートを使用することで、要素と属性の識別に名前空間を使用する XML ドキュメントを扱うことができます。 XMLドキュメント内でデフォルトのXML名前空間プレフィックスを解決し、名前空間を指定する方法を提供します。
エラーハンドリング
不正な XML ドキュメントおよび解析エラーに対するエラー処理機能は、xml.etree に含まれています。 エラー管理とキャプチャリングのテクニックを提供し、XMLデータを扱う際の信頼性と堅牢性を保証します。
互換性と携帯性
xml.etree は Python 標準ライブラリのコンポーネントであるため、追加のインストールを必要とせずに、Python プログラムですぐに使用できます。 Python 2とPython 3の両方と互換性があるため、多く for Python設定で利用可能です。
xml.etree の作成と設定
XMLドキュメントの作成
インポートXMLツリーの要素を表すオブジェクトを作成し、ルート要素にアタッチすることで、XMLドキュメントを生成することができます。 これはXMLデータを作成する方法の例です:
import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Parent element
book1 = ET.SubElement(root, "book")
# Set attribute for book1
book1.set("id", "1")
# Child elements for book1
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Parent element
book2 = ET.SubElement(root, "book")
# Set attribute for book2
book2.set("id", "2")
# Child elements for book2
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create ElementTree object
tree = ET.ElementTree(root)import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Parent element
book1 = ET.SubElement(root, "book")
# Set attribute for book1
book1.set("id", "1")
# Child elements for book1
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Parent element
book2 = ET.SubElement(root, "book")
# Set attribute for book2
book2.set("id", "2")
# Child elements for book2
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create ElementTree object
tree = ET.ElementTree(root)XMLドキュメントのファイルへの書き込み
write() オブジェクトの関数を使用して、XML ファイルを書き込むことができます。
# Write XML document to file
tree.write("catalog.xml")# Write XML document to file
tree.write("catalog.xml")その結果、"catalog.xml"というファイルにXMLドキュメントが作成されます。
XMLドキュメントの解析
ElementTree 関数 parse() を使用して XML データを解析します。
# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()このようにして、"catalog.xml"というXMLドキュメントが解析され、XMLツリーのルート要素が得られます。
要素と属性へのアクセス
Element オブジェクトが提供するさまざまなテクニックと機能を使用することで、XML ドキュメントの要素と属性にアクセスできます。 例えば、最初の本のタイトルを表示するためには:
# Reading single XML element
first_book_title = root[0].find("title").text
print("Title of first book:", first_book_title)# Reading single XML element
first_book_title = root[0].find("title").text
print("Title of first book:", first_book_title)XMLドキュメントの修正
コンポーネントや属性の追加、変更、削除を行うことで、XMLドキュメントを変更できます。 例えば、2番目の本の著者を変更するには:
# Modify XML document
root[1].find("author").text = "Alice Smith"# Modify XML document
root[1].find("author").text = "Alice Smith"XMLドキュメントのシリアル化
ElementTree モジュールの tostring() 関数を使用すると、XML ドキュメントを文字列にシリアル化できます。
# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)IronPDFの使い方
IronPDF とは何ですか?
IronPDFは、C#、VB.NET、および他 for .NET言語でプログラムでPDFドキュメントを作成、編集、および変更する強力な.NETライブラリです。 高品質なPDFを動的に作成するための多様な機能セットを開発者に提供するため、多くのプログラムにおいて人気の選択肢です。
IronPDFの主な機能
PDF生成:
IronPDFを使用して、プログラマーは新しいPDFドキュメントを作成したり、既存のHTMLタグ、テキスト、画像、およびその他のファイル形式をPDFに変換できます。 この機能は、動的にレポート、請求書、領収書、その他のドキュメントを作成するために非常に役立ちます。
HTMLからPDFへの変換:
IronPDFを使用すると、開発者はJavaScriptやCSSのスタイルを含むHTMLドキュメントをPDFファイルに簡単に変換できます。 これにより、Webページから動的に生成されたコンテンツやHTMLテンプレートからPDFを作成できます。
PDFドキュメントの修正と編集:
IronPDFは既存のPDFドキュメントを修正および変更するための包括的な機能セットを提供します。 開発者は、要件に応じてPDFをカスタマイズするために、複数のPDFファイルを結合したり、別のドキュメントに分割したり、ページを削除したり、ブックマーク、注釈、透かしを追加したりすることができます。
IronPDFとxml.etreeを組み合わせたもの
この次のセクションでは、IronPDFを使用して解析されたXMLデータに基づいてPDFドキュメントを生成する方法を示します。 これにより、XMLとIronPDFの両方の強みを活用することで、構造化データを効率的にプロフェッショナルなPDFドキュメントに変換できることを示します。 ここに詳細な手順があります:
インストール
開始する前に、IronPDFがインストールされていることを確認してください。 pipを使用してそれをインストールできます:
pip install IronPdfpip install IronPdf解析されたXMLを使用してIronPDFでPDFドキュメントを生成する
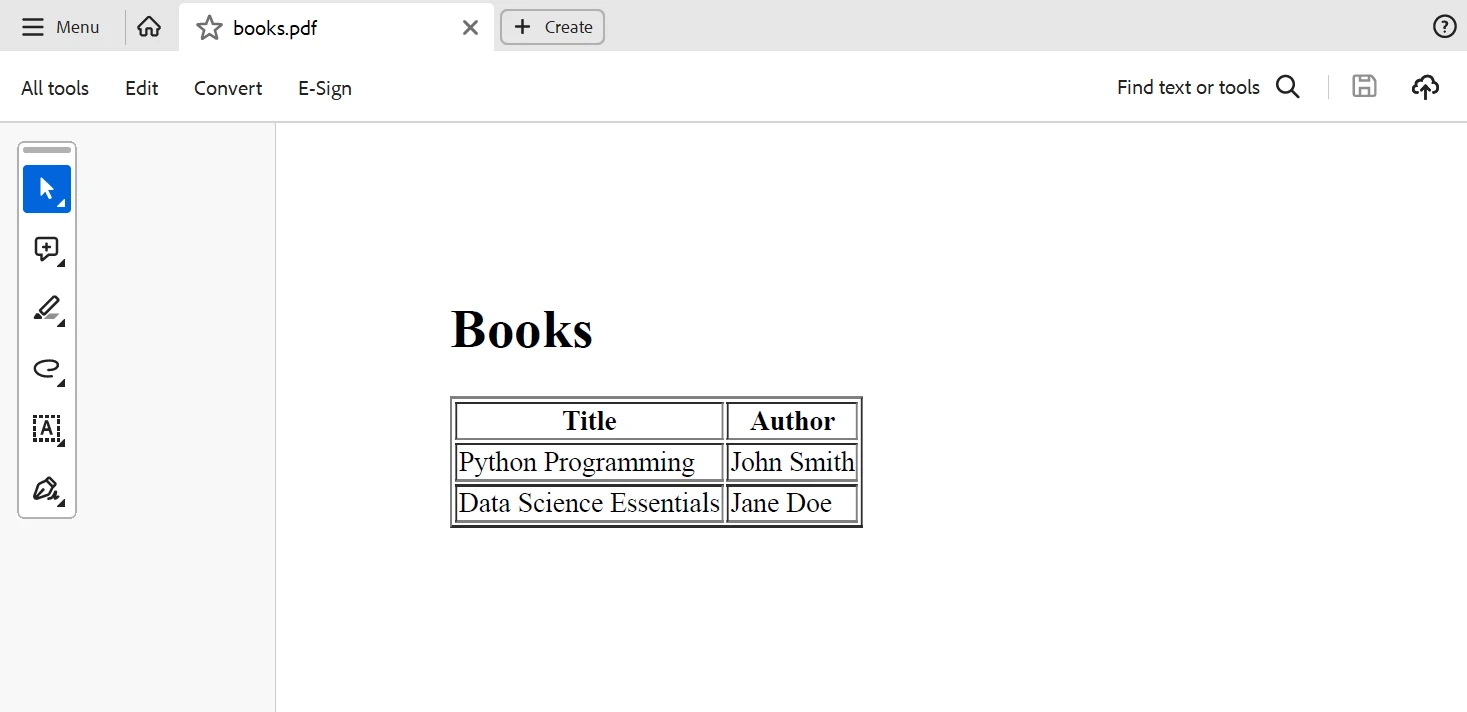
IronPDFを使用して、処理されたXMLから抽出したデータに応じてPDFドキュメントを作成することができます。 本の名前と著者を含む表を含むPDFドキュメントを作成しましょう:
from ironpdf import *
# Sample parsed XML books data
books = [
{'title': 'Python Programming', 'author': 'John Smith'},
{'title': 'Data Science Essentials', 'author': 'Jane Doe'}
]
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Iterate over books to add each book's data to the HTML table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
# Close the table and body tags
html_content += """
</table>
</body>
</html>
"""
# Generate and save the PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")from ironpdf import *
# Sample parsed XML books data
books = [
{'title': 'Python Programming', 'author': 'John Smith'},
{'title': 'Data Science Essentials', 'author': 'Jane Doe'}
]
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Iterate over books to add each book's data to the HTML table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
# Close the table and body tags
html_content += """
</table>
</body>
</html>
"""
# Generate and save the PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")こ for Pythonコードは本の名前と著者を含むHTMLテーブルを生成し、IronPDFはそれをPDFドキュメントに変換します。 以下に、上記のコードから生成された出力を示します。
出力
結論
結論として、XML データを解析し、解析されたデータに基づいて動的な PDF ドキュメントを生成したい開発者は、 IronPDFと Python の組み合わせに強力なソリューションを見出すでしょう。 信頼性が高く効果的な xml.etree Python API を利用することで、開発者は XML ドキュメントから構造化データを簡単に抽出できます。 しかし、IronPDFはこれを強化し、処理されたXMLデータから視覚的に美しい編集可能なPDFドキュメントを生成する機能を提供します。
PythonとIronPDFを組み合わせることで、開発者はデータ処理タスクを自動化し、XMLデータソースから貴重な洞察を抽出し、PDFドキュメントを通じてProfessionalかつ視覚的に魅力的な方法で提示することができます。 レポートの作成、請求書の作成、ドキュメントの作成など、Python とIronPDF の相乗効果により、データ処理とドキュメント生成の新たな可能性が開かれます。
IronPDF にはライフタイムライセンスが含まれており、バンドルで購入されるとかなり手頃な価格です。 このバンドルは非常にお得で、価格はわずか$999(複数のシステムで1回限りの購入)です。 ライセンスを持っている人は、24時間体制のオンライン技術サポートを利用できます。 料金についての詳細はウェブサイトをご覧ください。 ページでIron Softwareの製品についてさらに学べます。
















