
Python Requestsライブラリ(開発者向けのしくみ)
Python はそのシンプルさと読みやすさで広く評価されており、Web スクレイピングや API とのやり取りを行う開発者の間で人気があります。このようなやり取りを可能にする主要なライブラリの 1 つは、Python の Requests ライブラリです。 Requests は、HTTP リクエストを簡単に送信できる Python 用の HTTP リクエスト ライブラリです。 この記事では、Python ライブラリ Requests の機能について詳しく解説し、実用的な例を用いてその使い方を探り、 IronPDFを紹介し、Web データから PDF を作成および操作するために Requests とどのように組み合わせることができるかを示します。
Requestsライブラリの紹介
Python ライブラリ Requests は、HTTP リクエストをよりシンプルに、より人間が扱いやすいものにするために作成されました。 それは単純なAPIの背後にリクエストを行う複雑さを抽象化し、Web上のサービスとデータとのやり取りに集中できるようにします。 ウェブページの取得、REST API とのやり取り、SSL 証明書検証の無効化、サーバーへのデータ送信など、必要な操作はすべて Requests ライブラリで対応できます。
主な機能
1.シンプルさ:使いやすく、理解しやすい構文。
- HTTP メソッド: GET、POST、PUT、DELETE など、すべての HTTP メソッドをサポートします。 3.セッション オブジェクト:リクエスト間で Cookie を維持します。 4.認証:認証ヘッダーの追加を簡素化します。 5.プロキシ: HTTP プロキシのサポート。 6.タイムアウト:リクエストのタイムアウトを効果的に管理します。
- SSL 検証:デフォルトで SSL 証明書を検証します。
Requests をインストールしています
Requests を使い始めるには、インストールする必要があります。 これはpipを使って行うことができます。
pip install requestspip install requests基本的な使い方
ウェブページを取得するために Requests を使用する簡単な例を以下に示します。
import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)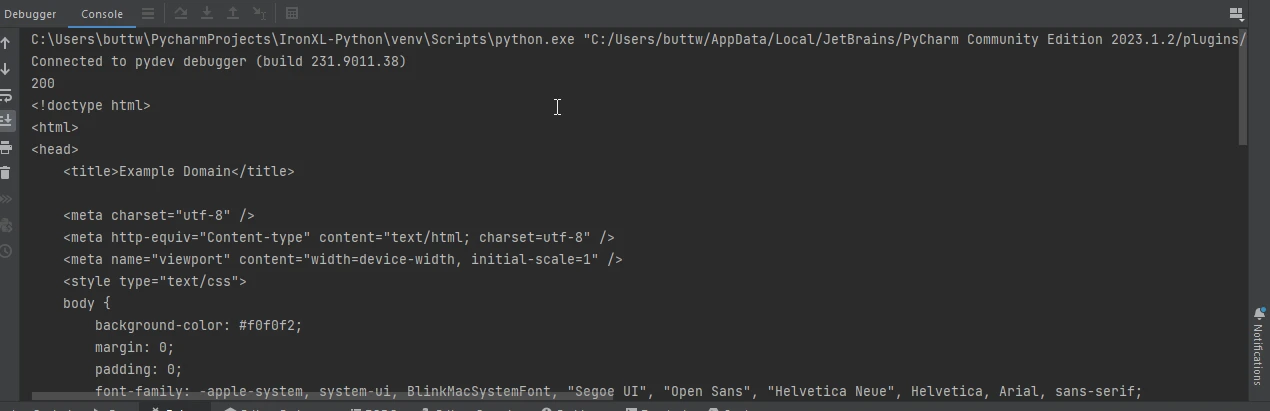
URLでのパラメータの送信
多くの場合、URLにパラメータを渡す必要があります。 Python の Requests モジュールは、params キーワードを使用してこれを簡単にします。
import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)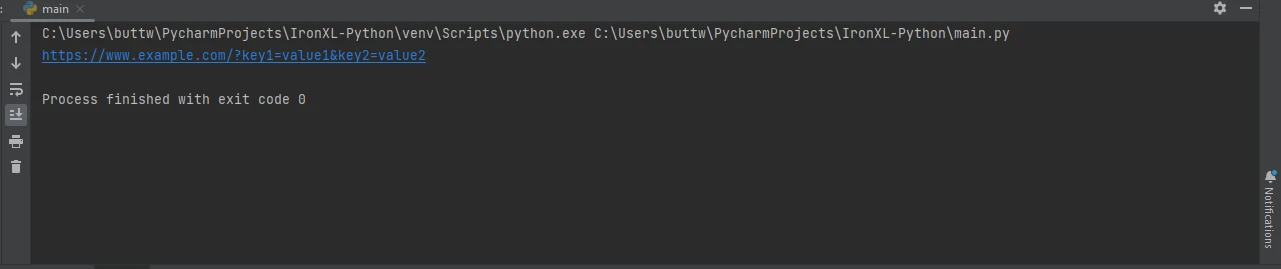
JSONデータの処理
APIとのやり取りには通常JSONデータが含まれます。 Requests は、組み込みの JSON サポートでこれを簡素化します。
import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)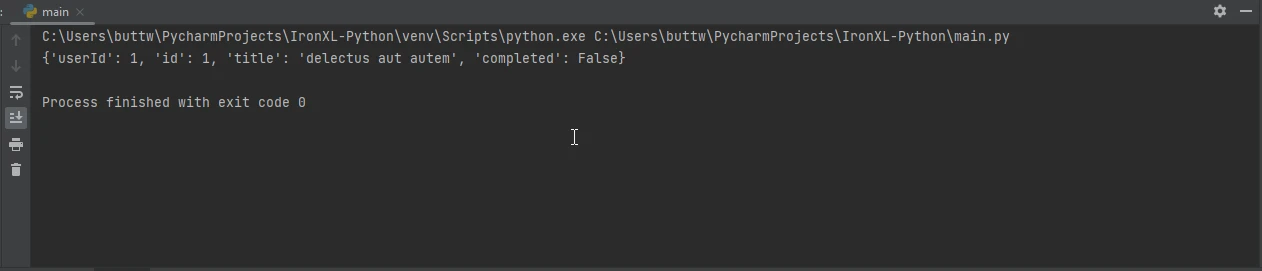
ヘッダーの取り扱い
ヘッダーはHTTPリクエストにとって重要です。 このようにカスタムヘッダーをリクエストに追加できます:
import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)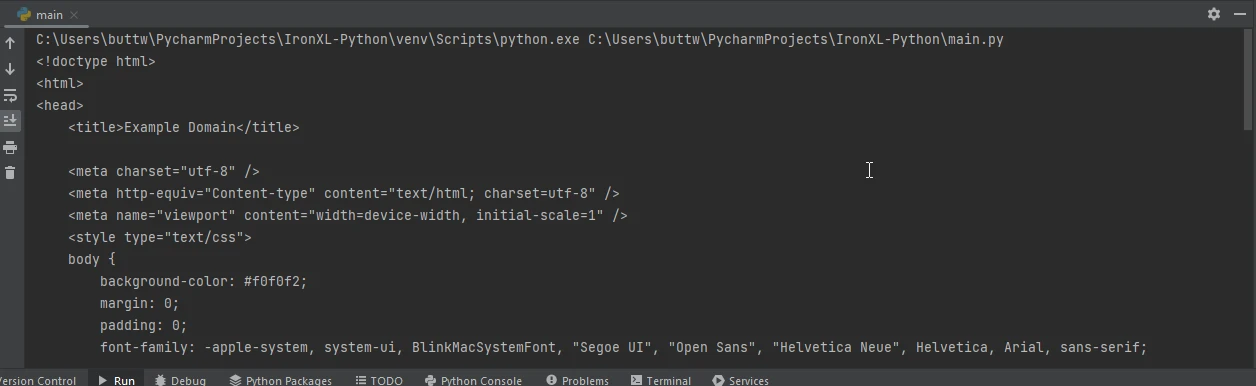
ファイルのアップロード
Requests はファイルアップロードもサポートしています。 ここではファイルをアップロードする方法です:
import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)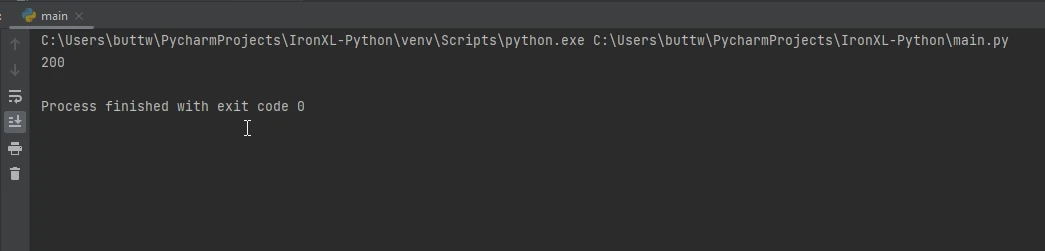
Python用IronPDFの紹介
IronPDFは多用途なPDF生成ライブラリで、Pythonアプリケーション内でPDFを作成、編集、操作することができます。 特にHTMLコンテンツからPDFを生成する必要がある場合に役立ち、レポート、請求書、その他の配布が必要なドキュメントを作成するのに最適なツールです。
IronPDFのインストール
IronPDFをインストールするには、pipを使用します:
pip install ironpdf
IronPDFをRequestsとともに使用しています
Requests とIronPDFを組み合わせることで、Web からデータを取得し、それを直接 PDF ドキュメントに変換できます。 これはWebデータからのレポートの作成や、WebページをPDFとして保存する際に特に有効です。
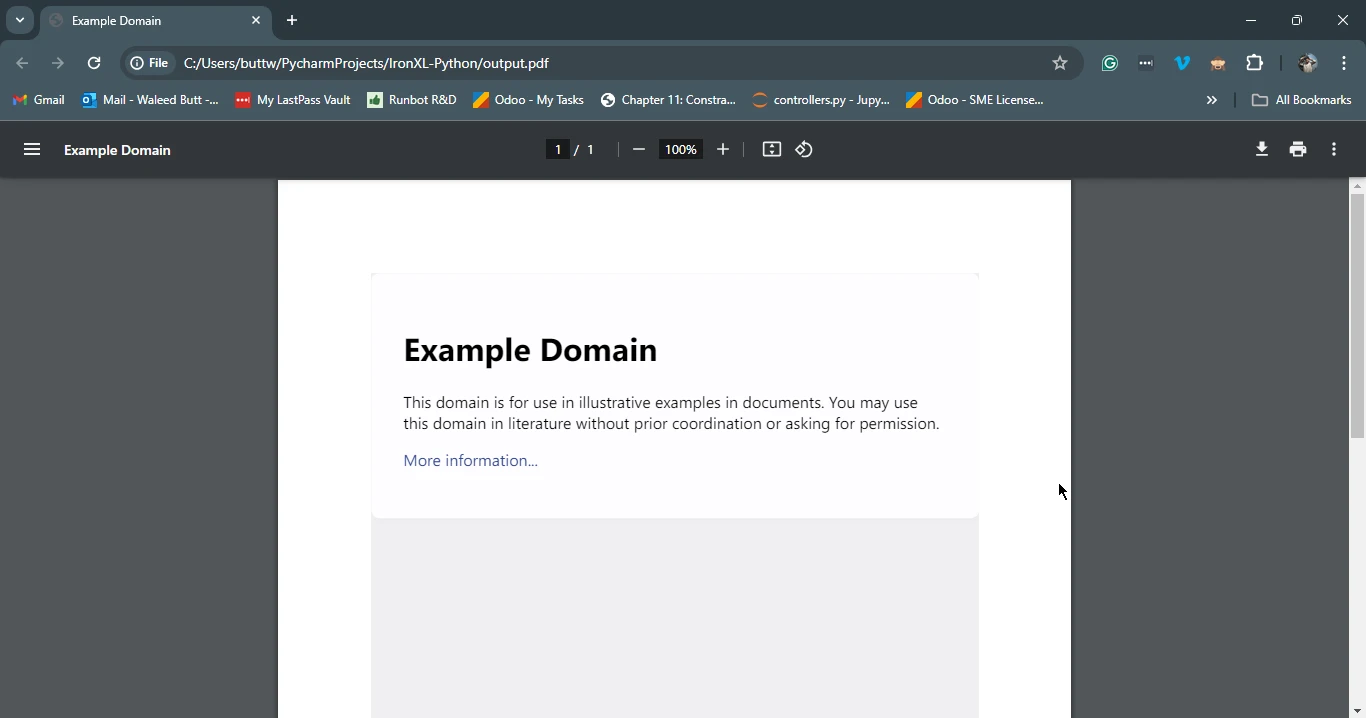
以下は、Requests を使用してウェブページを取得し、 IronPDFを使用してそれを PDF として保存する方法の例です。
import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')このスクリプトは、まず Requests を使用して指定された URL の HTML コンテンツを取得します。 その後、IronPDFを使用してこのレスポンスオブジェクトのHTMLコンテンツをPDFに変換し、結果のPDFをファイルとして保存します。
結論
Requestsライブラリは、Web APIとのやり取りが必要なPython開発者にとって不可欠なツールです。そのシンプルさと使いやすさから、HTTPリクエストを行う際の定番ツールとなっています。 IronPDFと組み合わせることで、さらに多くの可能性が広がり、Webからデータを取得し、プロフェッショナルな品質のPDFドキュメントに変換することが可能です。 レポート、請求書の作成、Web コンテンツのアーカイブなど、どのような用途であっても、Requests とIronPDFの組み合わせは、PDF 生成のニーズに対する強力なソリューションを提供します。
IronPDFのライセンスに関する詳細情報については、IronPDFのライセンスページを参照してください。 HTMLからPDFへの変換に関する詳細なチュートリアルもありますので、ぜひご覧ください。
















