
Bibliothèque Requests Python (Comment ça marche pour les développeurs)
Python est largement reconnu pour sa simplicité et sa lisibilité, ce qui en fait un choix populaire parmi les développeurs pour le web scraping et l'interaction avec les API. L'une des bibliothèques clés permettant ces interactions est la bibliothèque Python Requests. Requests est une bibliothèque de requêtes HTTP pour Python qui vous permet d'envoyer des requêtes HTTP de manière simple. Dans cet article, nous allons examiner en détail les fonctionnalités de la bibliothèque Python Requests, explorer son utilisation avec des exemples pratiques et présenter IronPDF, en montrant comment il peut être combiné avec Requests pour créer et manipuler des PDF à partir de données Web.
Introduction à la bibliothèque Requests
La bibliothèque Python Requests a été créée pour rendre les requêtes HTTP plus simples et plus conviviales. Elle abstrait les complexités de la réalisation de requêtes derrière une API simple afin que vous puissiez vous concentrer sur l'interaction avec les services et les données sur le web. Que vous ayez besoin de récupérer des pages Web, d'interagir avec des API REST, de désactiver la vérification des certificats SSL ou d'envoyer des données à un serveur, la bibliothèque Requests est là pour vous.
Principales caractéristiques
-
Simplicité : Syntaxe facile à utiliser et à comprendre.
-
Méthodes HTTP : Prend en charge toutes les méthodes HTTP - GET, POST, PUT, DELETE, etc.
-
Objets de session : Conservent les cookies entre les requêtes.
-
Authentification : Simplifie l'ajout d'en-têtes d'authentification.
-
Proxies : Prise en charge des proxys HTTP.
-
Délais d'attente : Gère efficacement les délais d'attente des requêtes.
- Vérification SSL : Vérifie les certificats SSL par défaut.
Installation de Requests
Pour commencer à utiliser Requests, vous devez l'installer. Cela peut être fait avec pip :
pip install requests
pip install requests
Utilisation de base
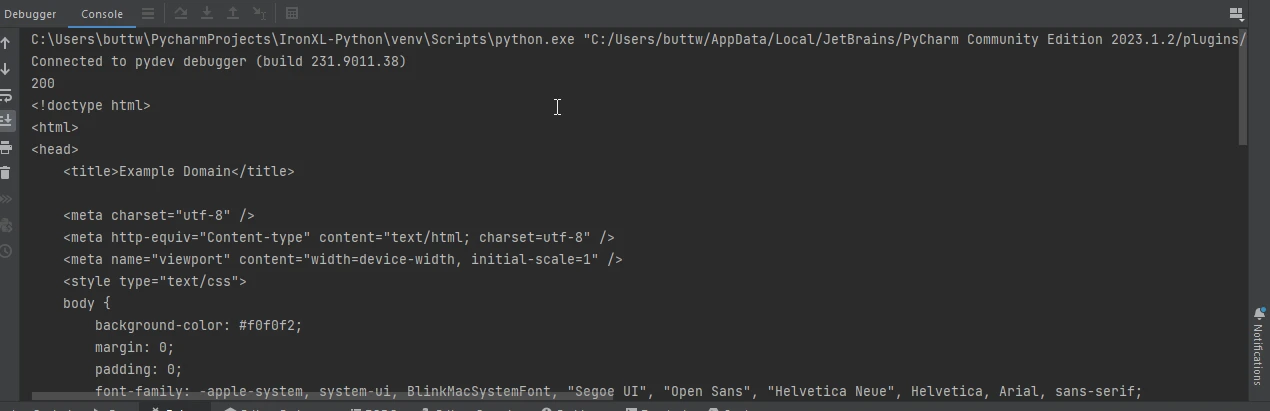
Voici un exemple simple d'utilisation de Requests pour récupérer une page web :
import requests
# Send a GET request to the specified URL
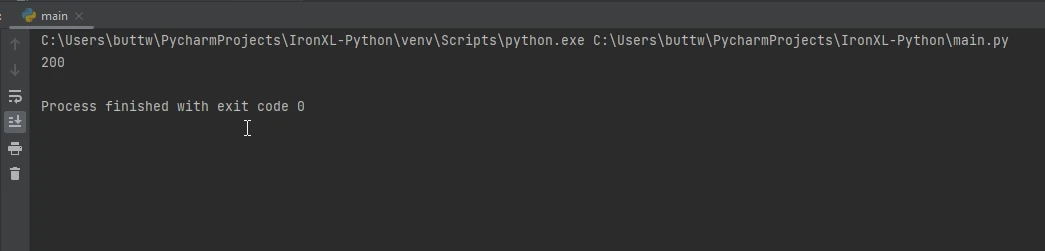
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)
import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)
Envoi de paramètres dans les URLs
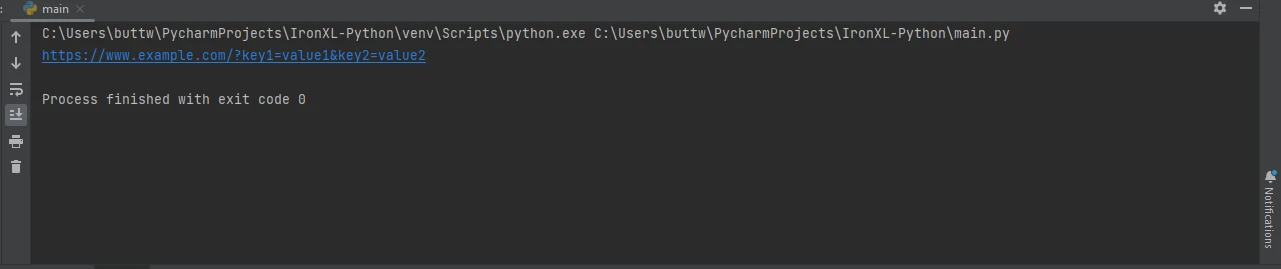
Souvent, vous devez transmettre des paramètres à l'URL. Le module Python Requests facilite cela grâce au mot-clé params :
import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)
import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)
Gestion des données JSON
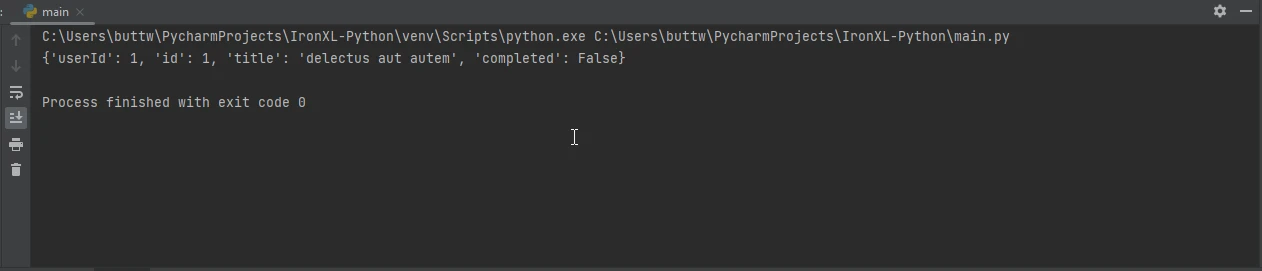
Interagir avec des APIs implique généralement des données JSON. Requests simplifie cela grâce à la prise en charge intégrée de JSON :
import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)
import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)
Travail avec les en-têtes
Les en-têtes sont cruciaux pour les requêtes HTTP. Vous pouvez ajouter des en-têtes personnalisés à vos requêtes comme ceci :
import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)
import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)
Téléchargement de fichiers
Requests prend également en charge le téléchargement de fichiers. Voici comment vous pouvez télécharger un fichier :
import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)
import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)
Présentation de IronPDF for Python
IronPDF est une bibliothèque versatile de génération de PDF qui peut être utilisée pour créer, éditer, et manipuler des PDFs dans vos applications Python. Elle est particulièrement utile lorsque vous avez besoin de générer des PDFs à partir de contenu HTML, en faisant un excellent outil pour créer des rapports, factures, ou tout autre type de document qui doit être distribué dans un format portable.
Installation d'IronPDF
Pour installer IronPDF, utilisez pip :
:ProductInstall
:ProductInstall
Utilisation IronPDF avec Requests
La combinaison de Requests et IronPDF vous permet de récupérer des données sur le Web et de les convertir directement en documents PDF. Cela peut être particulièrement utile pour créer des rapports à partir de données web ou pour sauvegarder des pages web en tant que PDFs.
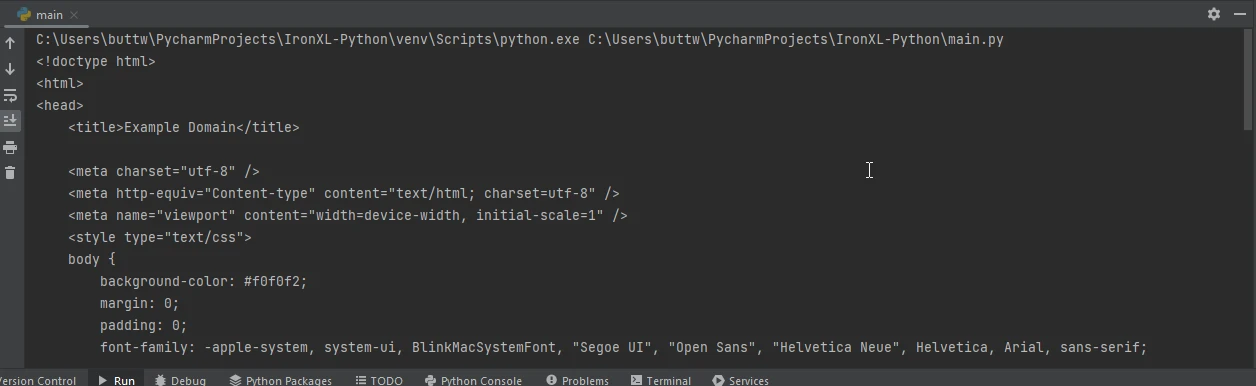
Voici un exemple d'utilisation de Requests pour récupérer une page web puis utiliser IronPDF pour l'enregistrer au format PDF :
import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
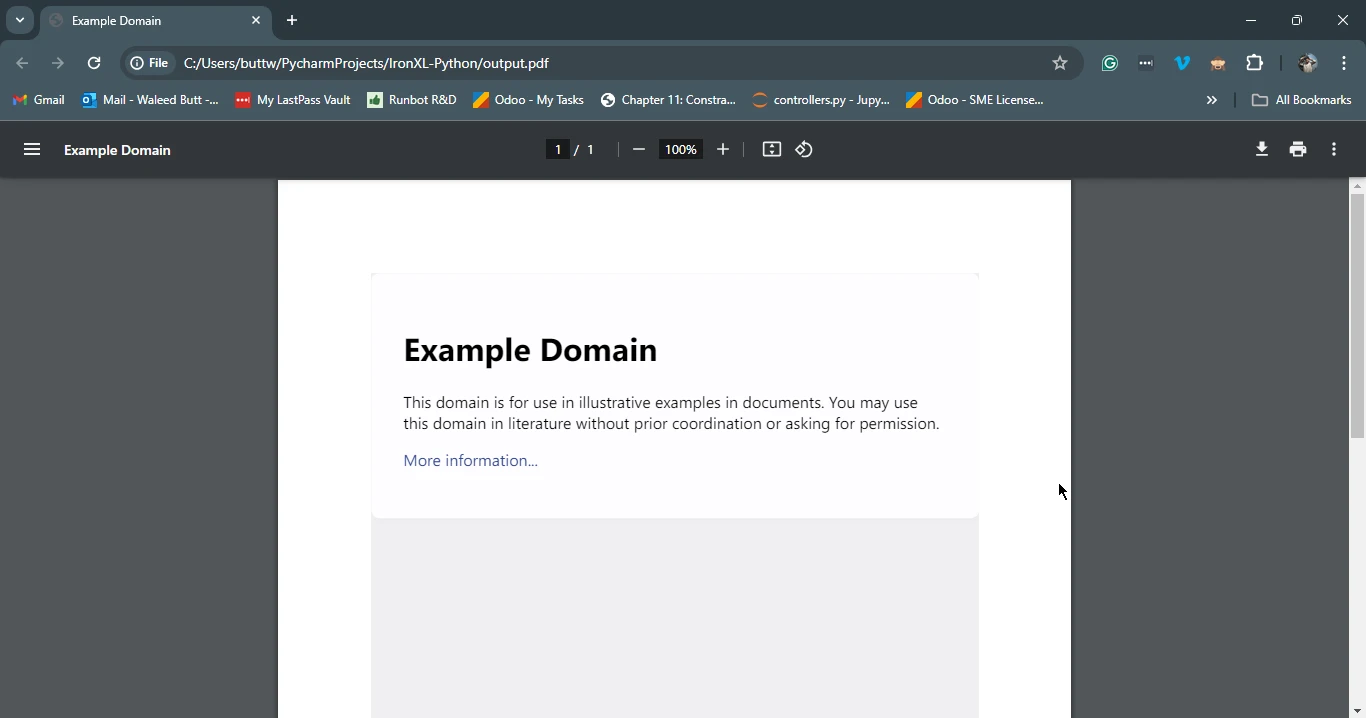
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')
import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')
Ce script récupère d'abord le contenu HTML de l'URL spécifiée en utilisant Requests. Il utilise ensuite IronPDF pour convertir le contenu HTML de cet objet réponse en un PDF et sauvegarde le PDF résultant dans un fichier.
Conclusion
La bibliothèque Requests est un outil indispensable pour tout développeur Python ayant besoin d'interagir avec des API web. Sa simplicité et sa facilité d'utilisation en font un choix privilégié pour effectuer des requêtes HTTP. Quand elle est combinée avec IronPDF, elle ouvre encore plus de possibilités, vous permettant de récupérer des données du web et de les convertir en documents PDF de qualité professionnelle. Que vous créiez des rapports, des factures ou que vous archiviez du contenu Web, la combinaison de Requests et IronPDF offre une solution puissante pour vos besoins de génération de PDF.
Pour plus d'informations sur la licence IronPDF, consultez la page de licence IronPDF. Vous pouvez également explorer notre tutoriel détaillé sur la conversion HTML vers PDF pour plus d'informations.
















