
Biblioteca Requests do Python (Como funciona para desenvolvedores)
Python é amplamente celebrado por sua simplicidade e legibilidade, tornando-se uma escolha popular entre desenvolvedores para web scraping e interação com APIs. Uma das principais bibliotecas que possibilitam tais interações é a biblioteca Python Requests. Requests é uma biblioteca de requisições HTTP for Python que permite enviar requisições HTTP de forma simples. Neste artigo, exploraremos os recursos da biblioteca Python Requests, examinaremos seu uso com exemplos práticos e apresentaremos IronPDF, mostrando como ele pode ser combinado com Requests para criar e manipular PDFs a partir de dados da web.
Introdução à Biblioteca Requests
A biblioteca Python Requests foi criada para tornar as requisições HTTP mais simples e amigáveis. Ela abstrai as complexidades de fazer requisições por trás de uma API simples, para que você possa se concentrar na interação com serviços e dados na web. Seja para buscar páginas da web, interagir com APIs REST, desabilitar a verificação de certificado SSL ou enviar dados para um servidor, a biblioteca Requests fornece cobertura completa.
Principais características
- Simplicidade: Sintaxe fácil de usar e entender.
- Métodos HTTP: Suporta todos os métodos HTTP - GET, POST, PUT, DELETE, etc.
- Objetos de sessão: Mantêm os cookies entre as requisições.
- Autenticação: Simplifica a adição de cabeçalhos de autenticação.
- Proxies: Suporte para proxies HTTP.
- Tempos limite: Gerencia os tempos limite de requisição de forma eficaz.
- Verificação SSL: Verifica certificados SSL por padrão.
Instalando Requests
Para começar a usar Requests, é necessário instalá-lo. Isso pode ser feito usando o pip:
pip install requestspip install requestsUso básico
Aqui está um exemplo simples de como usar Requests para buscar uma página da web:
import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)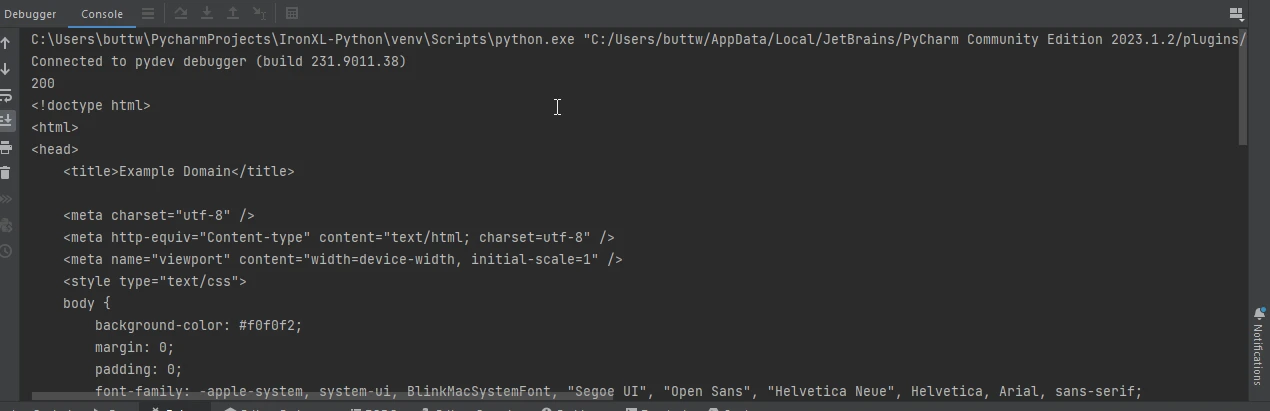
Envio de parâmetros em URLs
Frequentemente, é necessário passar parâmetros para a URL. O módulo Python Requests facilita isso com a palavra-chave params:
import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)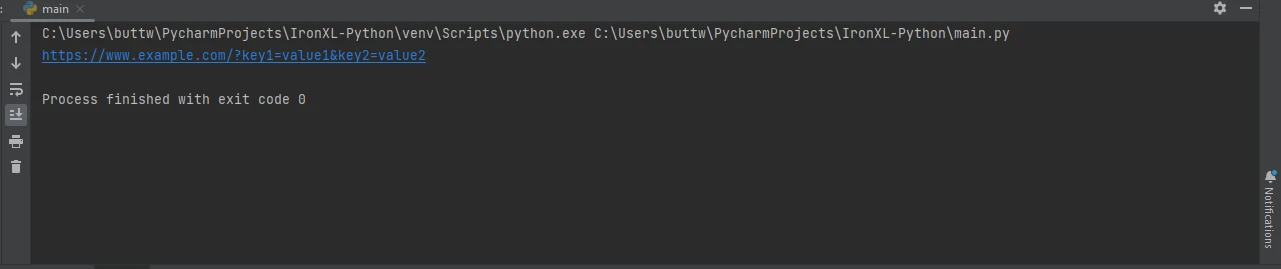
Manipulação de dados JSON
A interação com APIs geralmente envolve dados JSON. Requests simplifica isso com suporte embutido para JSON:
import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)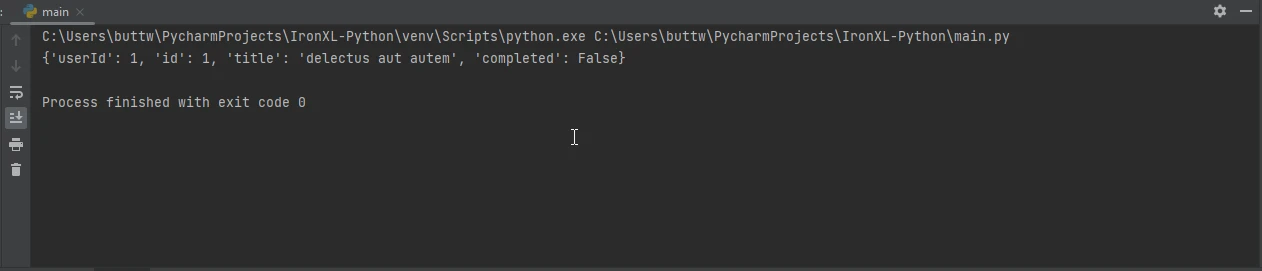
Trabalhando com cabeçalhos
Os cabeçalhos são cruciais para as requisições HTTP. Você pode adicionar cabeçalhos personalizados às suas solicitações desta forma:
import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)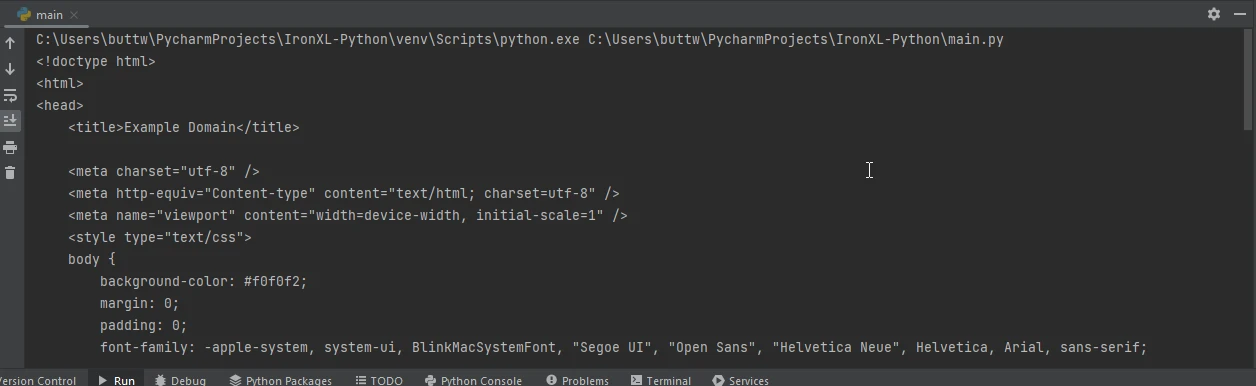
Envio de arquivos
Requests também suporta upload de arquivos. Veja como você pode enviar um arquivo:
import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)
Apresentando o IronPDF for Python
IronPDF é uma biblioteca versátil para geração de PDFs que pode ser usada para criar, editar e manipular PDFs em suas aplicações Python. É particularmente útil quando você precisa gerar PDFs a partir de conteúdo HTML, tornando-se uma ótima ferramenta para criar relatórios, faturas ou qualquer outro tipo de documento que precise ser distribuído em um formato portátil.
Instalando o IronPDF
Para instalar o IronPDF, use o pip:
pip install ironpdf
Usando IronPDF com Requests
Combinar Requests e IronPDF permite buscar dados da web e convertê-los diretamente em documentos PDF. Isso pode ser particularmente útil para criar relatórios a partir de dados da web ou salvar páginas da web como PDFs.
Aqui está um exemplo de como usar Requests para buscar uma página da web e depois usar IronPDF para salvá-la como um PDF:
import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')Este script primeiro busca o conteúdo HTML da URL especificada usando Requests. Em seguida, utiliza o IronPDF para converter o conteúdo HTML desse objeto de resposta em um PDF e salva o PDF resultante em um arquivo.
Conclusão
A biblioteca Requests é uma ferramenta essencial para qualquer desenvolvedor Python que precise interagir com APIs da web. Sua simplicidade e facilidade de uso a tornam uma escolha padrão para realizar requisições HTTP. Quando combinado com o IronPDF, abre ainda mais possibilidades, permitindo que você busque dados da web e os converta em documentos PDF de qualidade profissional. Seja criando relatórios, faturas ou arquivando conteúdo da web, a combinação de Requests e IronPDF fornece uma solução poderosa para suas necessidades de geração de PDFs.
Para obter mais informações sobre o licenciamento do IronPDF , consulte a página de licenças do IronPDF . Você também pode explorar nosso tutorial detalhado sobre conversão de HTML para PDF para obter mais informações.
















