
Computação Distribuída com Python
Python distribuído
Em um campo tecnológico em rápida transformação, a necessidade de soluções computacionais escaláveis e eficazes é maior do que nunca. A computação distribuída está se tornando cada vez mais necessária para trabalhos que envolvem grandes volumes de processamento de dados distribuídos, solicitações simultâneas de usuários e tarefas computacionalmente exigentes. Para permitir que os desenvolvedores utilizem plenamente o Python distribuído, examinaremos suas aplicações, princípios e ferramentas neste artigo.
A geração e modificação dinâmica de documentos PDF é um requisito comum na área de desenvolvimento web. A capacidade de criar PDFs programaticamente é muito útil para criar faturas, relatórios e certificados rapidamente.
A vasta ecologia e versatilidade do Python permitem lidar com uma infinidade de bibliotecas de PDF. IronPDF é uma solução formidável que ajuda os desenvolvedores a utilizar totalmente sua infraestrutura ao simplificar o processo de criação de PDFs e permitir o paralelismo de tarefas e a computação distribuída também.
Entendendo o Python Distribuído
Fundamentalmente, o Python distribuído é o processo de dividir o trabalho computacional em partes menores e distribuí-las entre vários nós, ou unidades de processamento. Esses nós podem ser máquinas individuais conectadas a uma rede, núcleos de CPU individuais dentro de um sistema, objetos remotos, funções remotas, execução remota de chamadas de função ou até mesmo threads individuais dentro de um único processo. O objetivo é aumentar o desempenho, a escalabilidade e a tolerância a falhas através da paralelização da carga de trabalho.
Python é uma ótima opção para cargas de trabalho de computação distribuída devido à sua facilidade de uso, adaptabilidade e um robusto ecossistema de bibliotecas. Python oferece uma abundância de ferramentas para computação distribuída em todas as escalas e casos de uso, variando de estruturas robustas como Celery, Dask e Apache Spark a módulos embutidos como multiprocessing e threading.
Antes de entrarmos nos detalhes, vamos examinar as ideias e os preceitos básicos sobre os quais o Python Distribuído se baseia:
Paralelismo vs. Concorrência
Paralelismo implica a execução de múltiplas tarefas ao mesmo tempo, enquanto concorrência se refere ao gerenciamento de várias tarefas que podem estar sendo executadas simultaneamente, mas não necessariamente em simultâneo. Tanto o paralelismo quanto a concorrência são contemplados pelo Python distribuído, dependendo das tarefas em questão e do projeto do sistema.
Distribuição de tarefas
Um componente fundamental da computação paralela e distribuída é a distribuição do trabalho entre vários nós ou unidades de processamento. A distribuição eficaz do trabalho é crucial para otimizar o desempenho geral, a eficiência e o uso de recursos, seja na execução de funções em um programa computacional sendo paralelizada em vários núcleos ou em um pipeline de processamento de dados sendo dividido em estágios menores.
Comunicação e Coordenação
Em sistemas distribuídos, a comunicação e a coordenação eficazes entre os nós são essenciais para facilitar a orquestração da execução remota de funções, fluxos de trabalho complexos, troca de dados e sincronização de computação.
Programas Python distribuídos se beneficiam de tecnologias como filas de mensagens, estruturas de dados distribuídas e chamadas de procedimento remoto (RPC), que permitem uma coordenação e comunicação eficientes entre a execução remota e a execução física da função.
Confiabilidade e Prevenção de Erros
A capacidade de um sistema de acomodar cargas de trabalho crescentes, adicionando nós ou unidades de processamento em máquinas diferentes, é chamada de escalabilidade. Em contrapartida, a tolerância a falhas refere-se ao projeto de sistemas que podem suportar falhas como falhas de máquinas, partições de rede e travamentos de nós, e ainda assim funcionar de forma confiável.
Para garantir a estabilidade e a resiliência de aplicações distribuídas em várias máquinas, os frameworks Python distribuídos frequentemente incluem recursos de tolerância a falhas e escalonamento automático.
Aplicações do Python Distribuído
Processamento de Dados e Análise: Grandes conjuntos de dados podem ser processados em paralelo usando estruturas Python distribuídas como Apache Spark e Dask, o que torna possível que aplicações distribuídas em Python realizem atividades como processamento em lote, processamento de fluxo em tempo real e aprendizado de máquina em escala.
Desenvolvimento Web com Microserviços: Aplicações web escaláveis e arquiteturas de microserviços podem ser criadas com estruturas web Python como Flask e Django em conjunto com filas de tarefas distribuídas como Celery. Aplicações web podem incorporar facilmente funcionalidades como cache distribuído, tratamento assíncrono de requisições e processamento de tarefas em segundo plano.
Computação Científica e Simulação: A computação de alto desempenho (HPC) e a simulação paralela em clusters de máquinas são possibilitadas pelo robusto ecossistema de bibliotecas científicas e estruturas de computação distribuída do Python. As aplicações incluem análise de risco financeiro, modelagem climática, aplicações de aprendizado de máquina e simulações de física e biologia computacional.
Computação de borda e a Internet das Coisas (IoT): Com a proliferação de dispositivos IoT e projetos de computação de borda, o Python distribuído torna-se cada vez mais importante para lidar com dados de sensores, coordenar processos de computação de borda, construir aplicações distribuídas em conjunto e colocar em prática modelos de aprendizado de máquina distribuídos para aplicações modernas na borda.
Criação e utilização de Python distribuído
Aprendizado de máquina distribuído com Dask-ML
Uma biblioteca poderosa chamada Dask-ML expande a estrutura de computação paralela Dask para tarefas envolvendo aprendizado de máquina. Dividir a tarefa entre vários núcleos ou processadores em um cluster de máquinas possibilita que desenvolvedores Python treinem e apliquem modelos de aprendizado de máquina em conjuntos de dados enormes de maneira distribuída e eficaz.
import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")Chamadas de função paralelas com Ray
Com a ajuda da robusta estrutura de computação distribuída Ray, você pode executar funções ou tarefas Python simultaneamente nos vários núcleos ou computadores de um cluster. Ao utilizar o decorador @ray.remote, o Ray permite que você especifique funções como remotas. Depois disso, essas tarefas ou operações remotas podem ser executadas de forma assíncrona nos nós de trabalho do Ray no cluster.
import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()Começando
O que é o IronPDF?
Podemos criar, modificar e renderizar documentos PDF em programas .NET com a ajuda do conhecido pacote IronPDF for .NET. Trabalhar com PDFs pode ser feito de diversas maneiras: desde a criação de novos documentos PDF a partir de conteúdo HTML, fotografias ou dados brutos, até a extração de texto e imagens de documentos existentes, a conversão de páginas HTML para PDFs e a adição de texto, imagens e formas a documentos preexistentes.
A simplicidade e facilidade de uso do IronPDF são dois de seus principais benefícios. Graças à API intuitiva e à extensa documentação, os desenvolvedores podem começar a gerar PDFs em seus aplicativos .NET com facilidade. A velocidade e eficiência do IronPDF são mais duas características que facilitam para os desenvolvedores a produção rápida de documentos PDF de alta qualidade.
Algumas vantagens do IronPDF:
- Criação de PDFs a partir de dados brutos, imagens e HTML.
- Extração de imagens e texto de arquivos PDF.
- Incluir cabeçalhos, rodapés e marcas d'água em arquivos PDF.
- Os arquivos PDF são protegidos por senha e criptografia.
- A capacidade de preencher e assinar documentos eletronicamente.
Geração distribuída de PDFs com IronPDF
Distribuir tarefas por vários núcleos ou computadores dentro de um cluster é possível com estruturas Python distribuídas, como Dask e Ray. Isso possibilita a execução de tarefas complexas, como a geração de PDFs, em paralelo em um cluster, aproveitando vários núcleos dentro dele, o que reduz drasticamente o tempo necessário para criar um grande lote de PDFs.
Comece instalando IronPDF e a biblioteca ray usando pip:
pip install ironpdf celery
Aqui está um código Python conceitual que demonstra dois métodos usando IronPDF e Python para geração distribuída de PDF:
Fila de tarefas com um trabalhador central
Trabalhador Central (worker.py):
from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])Script do cliente (client.py):
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()Celery é o sistema de fila de tarefas que empregamos. As tarefas são enviadas para o trabalhador central (worker.py) juntamente com dados que contêm conteúdo HTML. A função cria um PDF usando IronPDF e o salva.
Uma tarefa contendo dados de exemplo é enviada para a fila pelo script do cliente (client.py). Este script pode ser alterado para enviar outras tarefas de computadores diferentes.
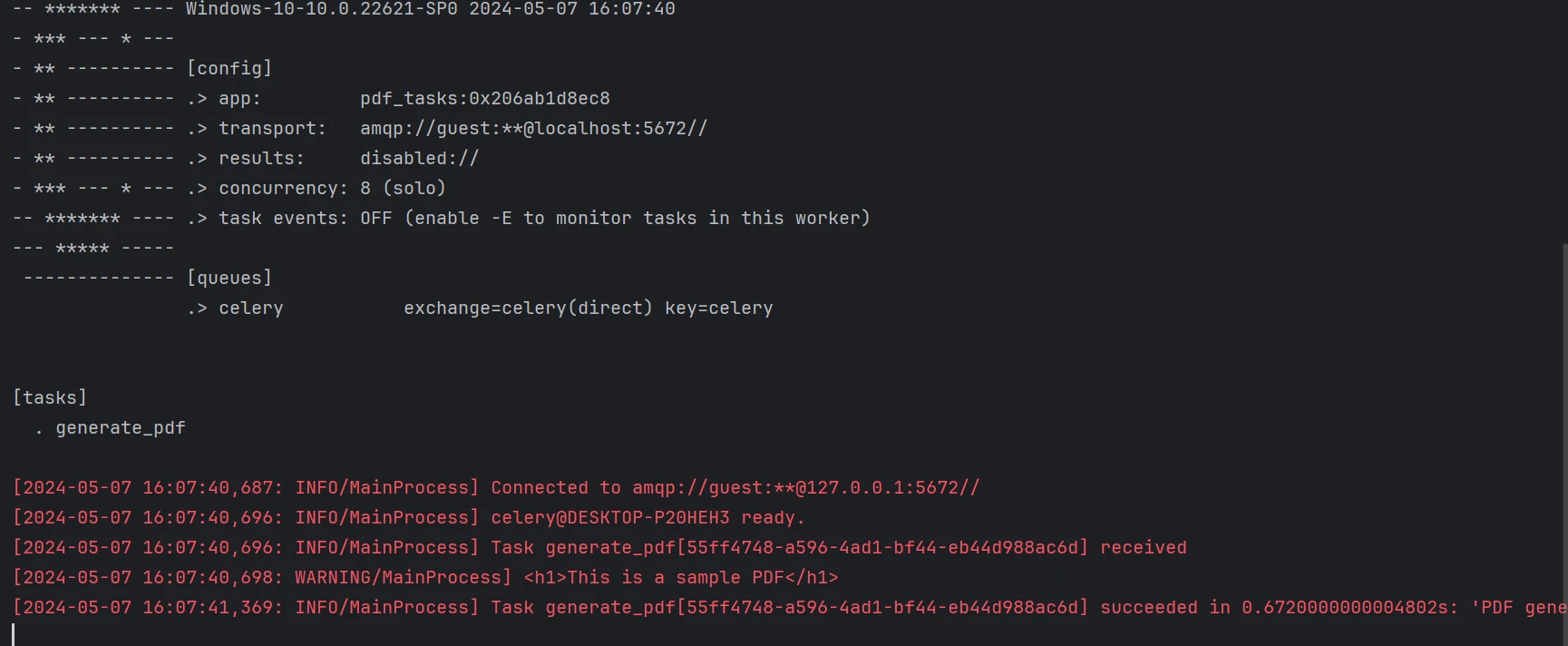
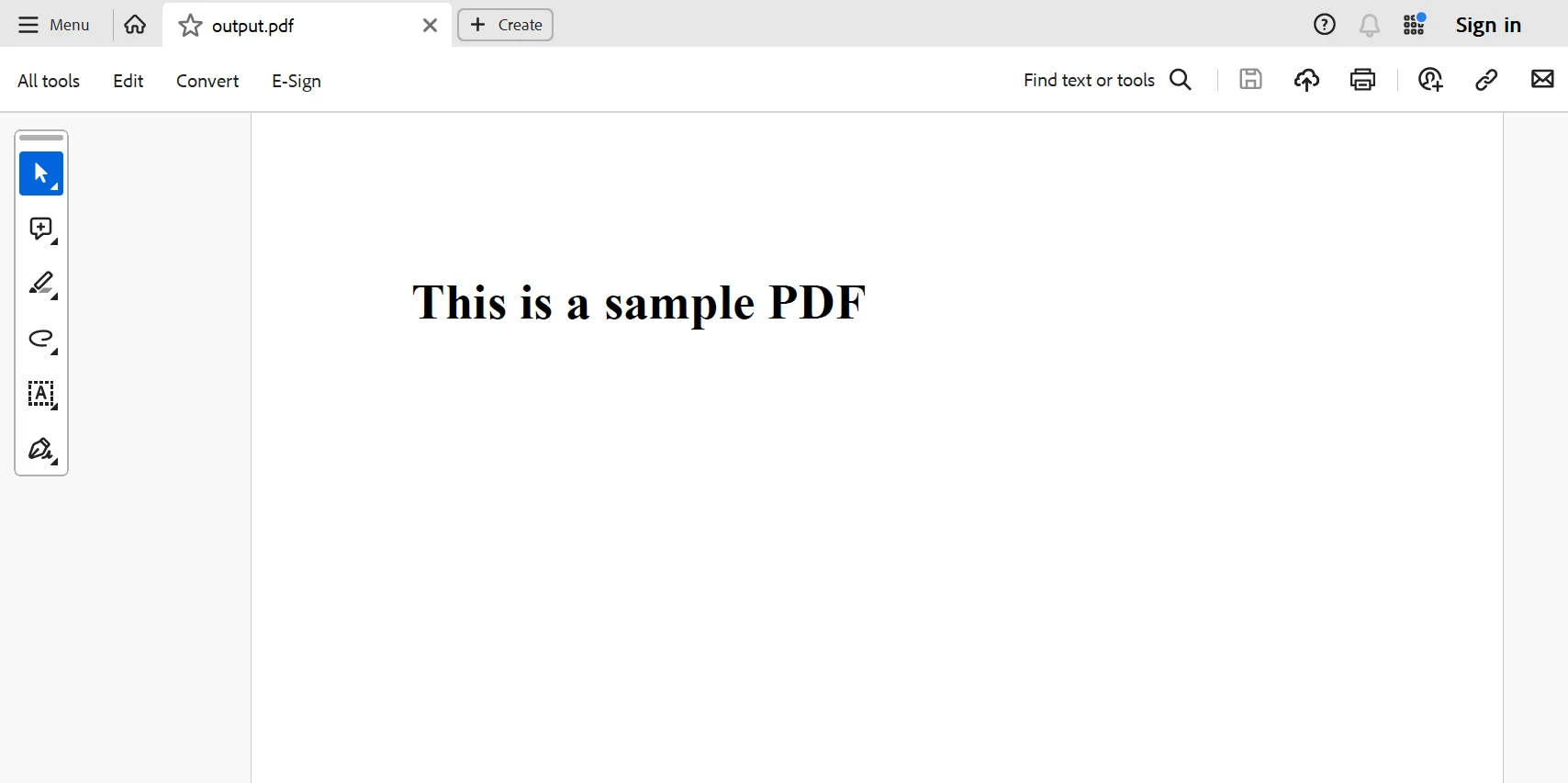
Abaixo está o PDF gerado a partir do código acima.
Conclusão
Os usuários de IronPDF que lidam com atividades de criação de PDF em larga escala podem liberar um enorme potencial utilizando Python distribuído e bibliotecas como Ray ou Dask. Em comparação com a execução de código em uma única máquina, é possível obter melhorias significativas de velocidade distribuindo a mesma carga de trabalho de código por vários núcleos e utilizando-a em várias máquinas.
IronPDF pode ser aprimorado de uma ferramenta poderosa para criar PDFs em um único sistema para uma solução confiável para gerenciar efetivamente grandes conjuntos de dados, utilizando a linguagem de programação Python distribuída. Para utilizar totalmente IronPDF no seu próximo projeto de criação de PDF em larga escala, investigue as bibliotecas Python oferecidas e experimente esses métodos!
IronPDF tem um preço razoável quando comprado como pacote e vem com uma licença vitalícia. O pacote é um excelente valor e, para muitos sistemas, pode ser adquirido por apenas $999. Oferece suporte técnico online 24 horas por dia, 7 dias por semana, aos titulares de licença. Para obter informações adicionais sobre a cobrança, visite o site. Para saber mais sobre os produtos que a Iron Software fabrica, acesse esta página.
















