
xml.etree Python (Geliştiriciler İçin Nasıl Çalışir)
XML (eXtensible Markup Language), veri işleme ve belge oluşturma sırasında yapılandırılmış verilerin sunumu için popüler ve esnek bir formattır. Standart kütüphane, XML verilerini ayrıştırmak veya oluşturmak için geliştiricilere güçlü bir araç seti sağlayan bir Python kütüphanesi olan xml.etree'yi içerir, çocuk elemanları yönetir ve programlı olarak XML belgeleri oluşturur.
IronPDF ile, PDF belgelerini oluşturmak ve düzenlemek için bir .NET kütüphanesi olan IronPDF ile birleştirildiğinde, geliştiriciler, XML eleman nesne verilerini işleme ve dinamik PDF belge oluşturma işlemlerini hızlandırmak için xml.etree ve IronPDF'nin birleştirilmiş yeteneklerinden yararlanabilirler. Bu derinlemesine kılavuzda, xml.etree Python dünyasına dalacağız, temel özelliklerini ve işlevlerini keşfedeceğiz ve veri işleme alanında yeni imkanlar açmak için nasıl IronPDF ile entegre edileceğini göstereceğiz.
xml.etree nedir?
xml.etree, Python'un standart kütüphanesinin bir parçasıdır. .etree takma adı, aynı zamanda ElementTree olarak da adlandırılır, XML belgelerini işlemek ve değiştirmek için basit ve etkili bir ElementTree XML API'si sunar. Programcıların, XML dosyalarının programlı oluşumunu, gezinmesini, değiştirilmesini ve hiyerarşik bir ağaç yapısında XML verilerini yönetmelerini sağlayarak XML belgeleriyle etkileşim kurmalarını sağlar.
Hafif ve kullanımı basit olmasına rağmen, xml.etree XML kök elemanı verilerini işlemek için güçlü işlevsellik sunar. Dosyalardan, metin dizelerinden veya dosya benzeri şeylerden XML veri belgelerini ayrıştırma yolu sunar. Ortaya çıkan ayrıştırılmış XML dosyası, Element nesneleri ağacı olarak gösterilir. Bu noktadan sonra, geliştiriciler bu ağaçta dolaşabilir, öğelere ve özelliklere erişebilir ve düzenleme, silme veya ekleme gibi farklı işlemler gerçekleştirebilir.

xml.etree özellikleri
XML Belgelerinin Ayrıştırılması
xml.etree içinde dizelerden, dosyalardan veya dosya benzeri nesnelerden XML belgeleri ayrıştırma metodları mevcuttur. XML içeriği, ayrıştırılmış XML belgesini geçerli bir Element nesnesi ile temsil eden bir ElementTree nesnesi üreten parse() fonksiyonu kullanılarak işlenebilir.
XML Ağaçlarında Gezinme
Belge işlendikten sonra, geliştiriciler, xml.etree kullanarak, find(), findall() ve iter() gibi fonksiyonlarla bir XML ağacının elemanlarında gezinebilirler. Bu yaklaşımlar, etiketler, öznitelikler veya XPath ifadelerine dayalı olarak belirli öğelere erişmeyi basit hale getirir.
XML Belgelerinin Değiştirilmesi
Bir XML belgesi içinde, xml.etree kullanarak bileşenler ve özellikler ekleyip düzenlemek ve kaldırmak için yollar vardır. Veri modifikasyonu, güncellemeleri ve dönüşümleri sağlamak için XML ağacının doğal hiyerarşik veri formatını, yapısını ve içeriğini programatik olarak değiştirme imkanı sağlar.
XML Belgelerinin Serileştirilmesi
XML belgesini değiştirdikten sonra, xml.etree, ElementTree.write() gibi fonksiyonları kullanarak XML ağaçlarının dizeye veya dosya benzeri nesnelere serileştirilmesine izin verir. Bu, geliştiricilerin XML ağaçlarını yaratmalarını, değiştirmelerini ve onlardan XML çıktısı üretmelerini sağlar.
XPath Desteği
XML belgesinden düğümleri seçmek için bir sorgu dili olan XPath desteği, xml.etree tarafından sağlanır. Geliştiriciler, bir XML ağacında öğeleri sorgulamak ve filtrelemek için XPath ifadelerini kullanarak sofistike veri alma ve manipülasyon etkinliklerini gerçekleştirebilir.
Yinelenen Ayrıştırma
Tüm belgeyi bir seferde belleğe yüklemek yerine, geliştiriciler, xml.etree'nin ardışık ayrıştırma desteği sayesinde XML belgelerini ardışık olarak işleyebilirler. Bu, büyük XML dosyalarının etkili bir şekilde yönetimi için çok yararlıdır.
Ad Alanlarını Destekleme
Geliştiriciler, xml.etree'nin XML ad alanları desteğini kullanarak öge ve özellik tanımlaması için ad alanları kullanan XML belgeleri ile çalışabilirler. XML belgesinin içinde varsayılan XML ad alanı öneklerini çözmek ve ad alanları belirtmek için yollar sunar.
Hata Yönetimi
Yanlış XML belgeleri ve ayrıştırma hataları için hata yönetim yetenekleri xml.etree içinde dahildir. XML verileri ile çalışırken, güvenilirliği ve sağlamlığı garanti eden hata yönetimi ve yakalamaya yönelik teknikler sunar.
Uyumluluk ve Taşınabilirlik
xml.etree, Python standart kütüphanesinin bir bileşeni olduğu için, herhangi bir ek kurulum gerektirmeden Python programlarında hemen kullanılabilir. Hem Python 2 hem de Python 3 ile çalıştığı için birçok Python ayarıyla taşınabilir ve uyumludur.
xml.etree oluşturun ve yapılandırın
Bir XML Belgeleri Oluştur
İthal XML ağacının öğelerini temsil eden nesneler oluşturup, bu nesneleri kök bir elemana bağlayarak bir XML belgesi oluşturabilirsiniz. XML verilerini nasıl oluşturacağınızı gösteren bir örnek:
import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Parent element
book1 = ET.SubElement(root, "book")
# Set attribute for book1
book1.set("id", "1")
# Child elements for book1
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Parent element
book2 = ET.SubElement(root, "book")
# Set attribute for book2
book2.set("id", "2")
# Child elements for book2
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create ElementTree object
tree = ET.ElementTree(root)import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Parent element
book1 = ET.SubElement(root, "book")
# Set attribute for book1
book1.set("id", "1")
# Child elements for book1
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Parent element
book2 = ET.SubElement(root, "book")
# Set attribute for book2
book2.set("id", "2")
# Child elements for book2
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create ElementTree object
tree = ET.ElementTree(root)XML Belgesini Dosyaya Yaz
XML dosyasını yazmak için ElementTree nesnesinin write() fonksiyonu kullanılabilir:
# Write XML document to file
tree.write("catalog.xml")# Write XML document to file
tree.write("catalog.xml")Sonuç olarak, XML belgesi "catalog.xml" adlı bir dosyada oluşturulacaktır.
Bir XML Belgesini Ayrıştır
parse() fonksiyonu kullanarak, ElementTree XML verilerini ayrıştırabilirsiniz:
# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()Bu şekilde, "catalog.xml" adlı XML belgesi ayrıştırılarak XML ağacının kök öğesi elde edilecektir.
Elemanlara ve Özniteliklere Eriş
Element nesneleri tarafından sunulan çeşitli teknikler ve özellikler kullanılarak, XML belgesinin elemanlarına ve özelliklerine erişebilirsiniz. Örneğin, ilk kitabın başlığını görüntülemek için:
# Reading single XML element
first_book_title = root[0].find("title").text
print("Title of first book:", first_book_title)# Reading single XML element
first_book_title = root[0].find("title").text
print("Title of first book:", first_book_title)XML Belgesini Değiştir
XML belgesi, bileşenleri ve öznitelikleri ekleyerek, değiştirerek veya silerek değiştirilebilir. Örneğin, ikinci kitabın yazarını değiştirmek için:
# Modify XML document
root[1].find("author").text = "Alice Smith"# Modify XML document
root[1].find("author").text = "Alice Smith"XML Belgesini Serileştir
ElementTree modülünün tostring() fonksiyonu, XML belgesini bir diziye serileştirmek için kullanılabilir:
# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)IronPDF ile Başlamak
IronPDF Nedir?
IronPDF, C#, VB.NET ve diğer .NET dillerinde programlı olarak PDF belgeleri oluşturmak, düzenlemek ve değiştirmek için güçlü bir .NET kütüphanesidir. Geliştiricilere yüksek kaliteli PDF'leri dinamik olarak oluşturma için geniş bir fırsat seti sunduğundan, birçok program için popüler bir seçimdir.
IronPDF'in Temel Özellikleri
PDF Oluşturma:
IronPDF kullanarak, programcılar yeni PDF belgeleri oluşturabilir veya mevcut HTML etiketlerini, metni, görselleri ve diğer dosya biçimlerini PDF'lere dönüştürebilir. Bu özellik, raporlar, faturalar, makbuzlar ve diğer belgeleri dinamik olarak oluşturmak için çok kullanışlıdır.
HTML'den PDF'ye Dönüştürme:
IronPDF, geliştiricilerin JavaScript ve CSS'den gelen stilleri de dahil olmak üzere HTML belgelerini PDF dosyalarına dönüştürmesini kolaylaştırır. Bu, web sayfalarından, dinamik olarak üretilen içeriklerden ve HTML şablonlarından PDF oluşturmayı mümkün kılar.
PDF Belgelerinin Değiştirilmesi ve Düzenlenmesi:
IronPDF, mevcut PDF belgelerini düzenleme ve değiştirme için kapsamlı bir işlev seti sunar. Geliştiriciler, birkaç PDF dosyasını birleştirebilir, başka belgelere ayırabilir, sayfaları kaldırabilir ve PDF'leri gereksinimlere göre özelleştirmek için yer imleri, açıklamalar ve filigranlar ekleyebilir.
IronPDF ve xml.etree Birleşimi
Bu bir sonraki bölüm, ayrıştırılmış XML verilerine dayalı IronPDF ile nasıl PDF belgeleri oluşturulacağını gösterecektir. Bu da, hem XML hem de IronPDF'in gücünden faydalanarak, yapılandırılmış verileri profesyonel PDF belgelerine etkin bir şekilde dönüştürebileceğinizi gösterir. İşte ayrıntılı nasıl yapılır:
Kurulum
Başlamadan önce IronPDF'in kurulu olduğundan emin olun. Pip kullanılarak kurulabilir:
pip install ironpdf
IronPDF ile Ayrıştırılan XML Kullanarak PDF Belgesi Oluşturun
IronPDF, işlenmiş XML'den çıkardığınız verilere dayalı olarak bir PDF belgesi oluşturmak için kullanılabilir. Kitap isimleri ve yazarlarının yer aldığı bir tablo ile PDF belgesi oluşturalım:
from ironpdf import *
# Sample parsed XML books data
books = [
{'title': 'Python Programming', 'author': 'John Smith'},
{'title': 'Data Science Essentials', 'author': 'Jane Doe'}
]
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Iterate over books to add each book's data to the HTML table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
# Close the table and body tags
html_content += """
</table>
</body>
</html>
"""
# Generate and save the PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")from ironpdf import *
# Sample parsed XML books data
books = [
{'title': 'Python Programming', 'author': 'John Smith'},
{'title': 'Data Science Essentials', 'author': 'Jane Doe'}
]
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Iterate over books to add each book's data to the HTML table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
# Close the table and body tags
html_content += """
</table>
</body>
</html>
"""
# Generate and save the PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
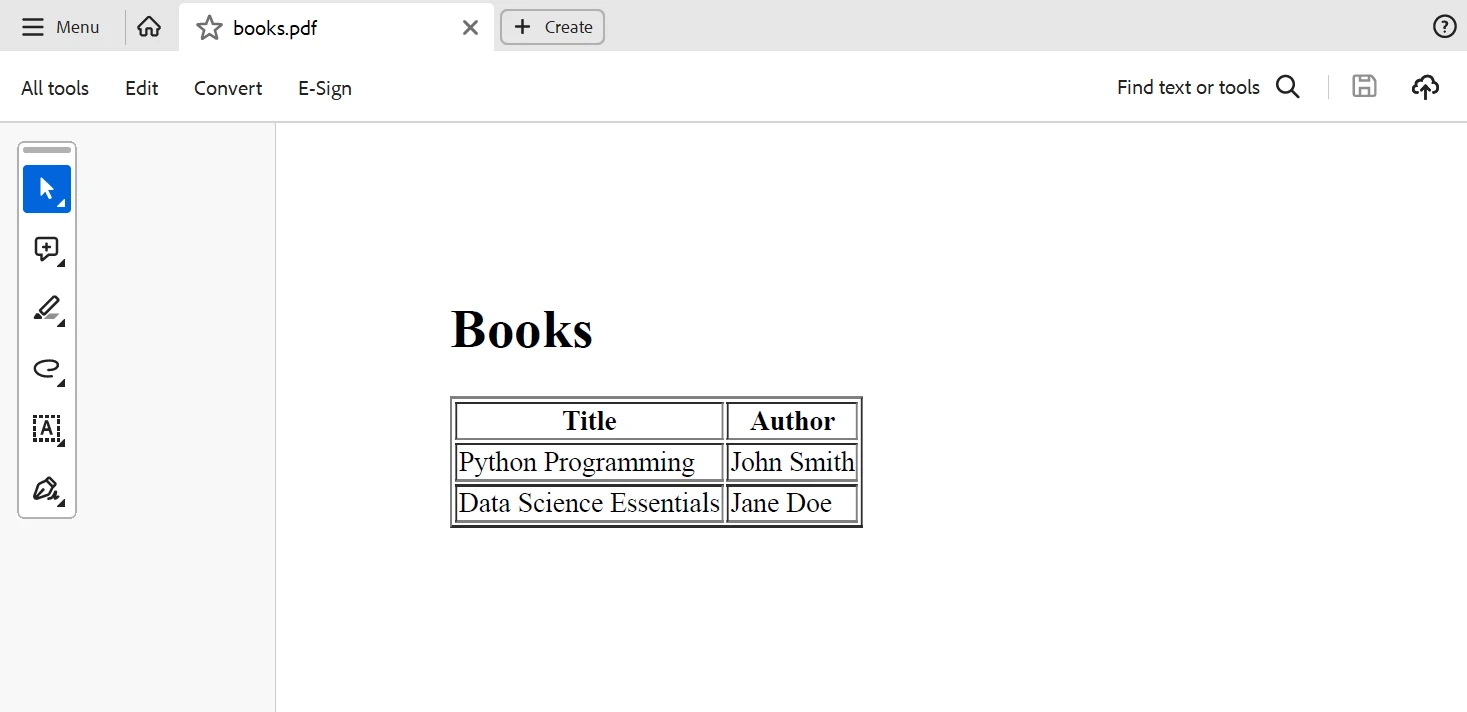
pdf.SaveAs("books.pdf")Bu Python kodu, kitap adlarını ve yazarlarını içeren bir HTML tablo oluşturur ve IronPDF daha sonra bunu bir PDF belgesine dönüştürür. Yukarıdaki koddan üretilen çıktı aşağıda verilmiştir.
Çıktı
Sonuç
Sonuç olarak, ayrıştırılmış verilere dayalı dinamik PDF belgeleri üretmek ve XML verilerini ayrıştırmak isteyen geliştiriciler, IronPDF ve xml.etree Python'un birleşimiyle güçlü bir çözüm bulacaklar. Güvenilir ve etkili xml.etree Python API'sinin yardımıyla, geliştiriciler, XML belgelerinden yapılandırılmış verileri kolayca çıkartabilirler. Bununla beraber IronPDF, işlenmiş XML verilerinden estetik açıdan hoş ve düzenlenebilir PDF belgeleri oluşturma yeteneği sunarak bunu geliştirir.
Birlikte, xml.etree Python ve IronPDF, geliştiricilere veri işleme görevlerini otomatikleştirme, XML veri kaynaklarından değerli bilgileri çıkartma ve bunları PDF belgeleri aracılığıyla profesyonel ve görsel olarak çekici bir şekilde sunma gücü verir. İster raporlar oluşturmak, fatura hazırlamak, ister belge üretmek olsun, xml.etree Python ve IronPDF arasındaki sinerji, veri işleme ve belge oluşturma alanında yeni olasılıkların kilidini açar.
IronPDF, bir paket halinde satın alındığında oldukça makul bir fiyata ömür boyu bir lisans içerir. Birden fazla sistem için tek seferde satın alma maliyeti $999 olan bu paket, mükemmel bir değer sunar. Lisanslı olanlar, çevrimiçi teknik desteğe 7/24 erişebilir. Ücretle ilgili daha fazla detay merak ediyorsanız lütfen bu web sitesi adresini ziyaret edin. Iron Software'in ürünleri hakkında daha fazla bilgi edinmek için bu sayfayı ziyaret edin.
















