
Grakn Python (どのように機能するか:開発者のためのガイド)
今日のコーディングの世界では、データベースが新しいアプリケーションの要求に応えるために進化しています。 従来のリレーショナルデータベースはまだ使用されていますが、現在ではオブジェクトリレーショナルマッピング (ORM) のような進歩があり、開発者はもはやSQLに頼るだけでなく、より高レベルのプログラミング抽象によってデータベースと対話できます。 このアプローチはデータ管理を効率化し、コードの整理をよりクリーンにします。 さらに、NoSQLデータベースは特にビッグデータアプリケーションやリアルタイム分析で非構造化データを扱うための有用なツールとして登場しました。
クラウドネイティブデータベースもまた、スケーラブルで信頼性が高く、管理されたサービスを提供し、基盤インフラストラクチャの維持の負担を軽減しています。 さらに、NewSQLやグラフデータベースはSQLとNoSQLの利点を組み合わせ、リレーショナルデータベースの信頼性とNoSQLの柔軟性を提供します。 このブレンドにより、多くの現代的なアプリケーションに適しています。 これらのさまざまなデータベースタイプを革新的なプログラミングパラダイムと統合することで、現在のデータ中心の要求に応じたスケーラブルで適応性のあるソリューションを作り出すことができます。 Grakn、現在はTypeDBとして知られるものは、ナレッジグラフの管理とクエリをサポートすることでこのトレンドを例示しています。この記事では、プログラムでPDFを生成し操作するための重要なツールであるIronPDFとの統合について探ります。
Graknとは何ですか?
Grakn(現在はTypeDB)、Grakn Labsによって作成されたものは、データの複雑なネットワークを管理および分析するために設計されたナレッジグラフデータベースです。 既存データセット内の洗練された関係をモデリングし、保存されたデータに対する強力な推論能力を提供することに優れています。 Graknのクエリ言語であるGraqlは、正確なデータ操作とクエリを可能にし、複雑なデータSetから価値ある洞察を引き出すインテリジェントなシステムの開発を支援します。 Graknのコア機能を活用することで、組織は堅牢でインテリジェントな知識表現を持つデータ構造を管理できます。
Graql、Graknのクエリ言語は、Graknのナレッジグラフモデルと効果的に相互作用するように設計されており、詳細でニュアンスのあるデータ変換を可能にします。 その水平スケーラビリティと大規模データセットの処理能力により、TypeDBはファイナンス、ヘルスケア、薬物発見、サイバーセキュリティなど、複雑なグラフ構造の理解と管理が重要なドメインに適しています。
PythonでのGraknのインストールと設定
Graknのインストール
Grakn(TypeDB)を使用したいPython開発者にとって、typedb-driverライブラリのインストールは必須です。 この公式クライアントは、TypeDBとの相互作用を容易にします。 このライブラリをインストールするために、次のpipコマンドを使用してください。
pip install typedb-driverpip install typedb-driverTypeDBサーバーのセットアップ
コードを書く前に、TypeDBサーバーが稼働していることを確認してください。 お使いのオペレーティングシステムに応じたTypeDBのウェブサイトでのインストールおよびセットアップ手順を参照してください。 インストールが完了したら、次のコマンドを使用してTypeDBサーバーを開始できます。
./typedb server./typedb serverPythonでのGraknの使用
TypeDBとやり取りするPythonコード
このセクションでは、TypeDBサーバーとの接続を確立し、データベーススキーマを設定し、データ挿入や取得などの基本操作を行うことを説明します。
データベーススキーマの作成
以下のコードブロックでは、ageの2つの属性を持つデータベース構造を定義します。 スキーマモードでセッションを開き、構造的な変更を可能にします。 ここではスキーマの定義とコミット方法を示します。
from typedb.driver import TypeDB, SessionType, TransactionType
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Create a database (if not already created)
database_name = "example_db"
if not client.databases().contains(database_name):
client.databases().create(database_name)
with client.session(database_name, SessionType.SCHEMA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
transaction.query().define("""
define
person sub entity, owns name, owns age;
name sub attribute, value string;
age sub attribute, value long;
""")
transaction.commit()from typedb.driver import TypeDB, SessionType, TransactionType
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Create a database (if not already created)
database_name = "example_db"
if not client.databases().contains(database_name):
client.databases().create(database_name)
with client.session(database_name, SessionType.SCHEMA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
transaction.query().define("""
define
person sub entity, owns name, owns age;
name sub attribute, value string;
age sub attribute, value long;
""")
transaction.commit()データの挿入
スキーマを確立した後、スクリプトはデータベースにデータを挿入します。 データ操作に適したDATAモードでセッションを開き、名前が"Alice"、年齢が30の新しいpersonエンティティを追加するための挿入クエリを実行します。
# Insert data into the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
# Create a person entity
transaction.query().insert("""
insert $p isa person, has name "Alice", has age 30;
""")
transaction.commit()# Insert data into the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
# Create a person entity
transaction.query().insert("""
insert $p isa person, has name "Alice", has age 30;
""")
transaction.commit()データクエリ
最後に、"Alice"という名前のエンティティを問い合わせてデータベースから情報を取得します。DATAモードで新しいセッションを開き、TransactionType.READを使用して読み取りトランザクションを開始します。 結果は処理され、名前と年齢を抽出して表示します。
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Query entities where the person has the name 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
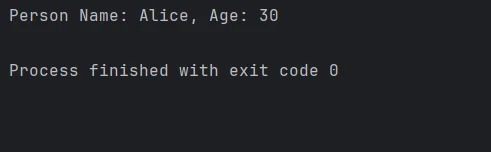
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
print(f"Person Name: {person_name}, Age: {person_age}")# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Query entities where the person has the name 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
print(f"Person Name: {person_name}, Age: {person_age}")出力
クライアント接続の終了
TypeDBサーバーとのさらなるインタラクションを防ぎ、リソースを適切に解放するには、client.close()を使用してクライアント接続を閉じてください。
# Close the client connection
client.close()# Close the client connection
client.close()IronPDFの紹介
IronPDF for Pythonは、PDFファイルをプログラムで作成し操作するための強力なライブラリです。 HTMLからのPDF作成、PDFファイルのマージ、既存のPDF文書への注釈をつけるための包括的な機能を提供します。 IronPDFはまた、HTMLやウェブコンテンツを高品質なPDFに変換することができ、レポート、請求書、その他の固定レイアウト文書を生成するのに理想的な選択肢です。
このライブラリは、コンテンツの抽出、文書の暗号化、およびページレイアウトのカスタマイズといった高度な機能を提供します。 IronPDFをPythonのアプリケーションに統合することで、開発者はドキュメント生成のワークフローを自動化し、PDFハンドリングの全体的な機能を強化することができます。
IronPDFライブラリのインストール
PythonでIronPDFの機能を有効にするには、pipを使用してライブラリをインストールしてください。
pip install ironpdfpip install ironpdfGrakn TypeDBとIronPDFの統合
Python環境でTypeDBとIronPDFを組み合わせることで、開発者はGrakn(TypeDB)データベース内の複雑に構造化されたデータに基づいて効率的にPDFドキュメントを生成し管理することができます。 以下は統合の例です。
from typedb.driver import TypeDB, SessionType, TransactionType
from ironpdf import *
import warnings
# Suppress potential warnings
warnings.filterwarnings('ignore')
# Replace with your own license key
License.LicenseKey = "YOUR LICENSE KEY GOES HERE"
# Initialize data list
data = []
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Fetch details of persons named 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
data.append({"name": person_name, "age": person_age})
# Close the client connection
client.close()
# Create a PDF from HTML content
html_to_pdf = ChromePdfRenderer()
content = "<h1>Person Report</h1>"
for item in data:
content += f"<p>Name: {item['name']}, Age: {item['age']}</p>"
# Render the HTML content as a PDF
pdf_document = html_to_pdf.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf_document.SaveAs("output.pdf")from typedb.driver import TypeDB, SessionType, TransactionType
from ironpdf import *
import warnings
# Suppress potential warnings
warnings.filterwarnings('ignore')
# Replace with your own license key
License.LicenseKey = "YOUR LICENSE KEY GOES HERE"
# Initialize data list
data = []
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Fetch details of persons named 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
data.append({"name": person_name, "age": person_age})
# Close the client connection
client.close()
# Create a PDF from HTML content
html_to_pdf = ChromePdfRenderer()
content = "<h1>Person Report</h1>"
for item in data:
content += f"<p>Name: {item['name']}, Age: {item['age']}</p>"
# Render the HTML content as a PDF
pdf_document = html_to_pdf.RenderHtmlAsPdf(content)
# Save the PDF to a file
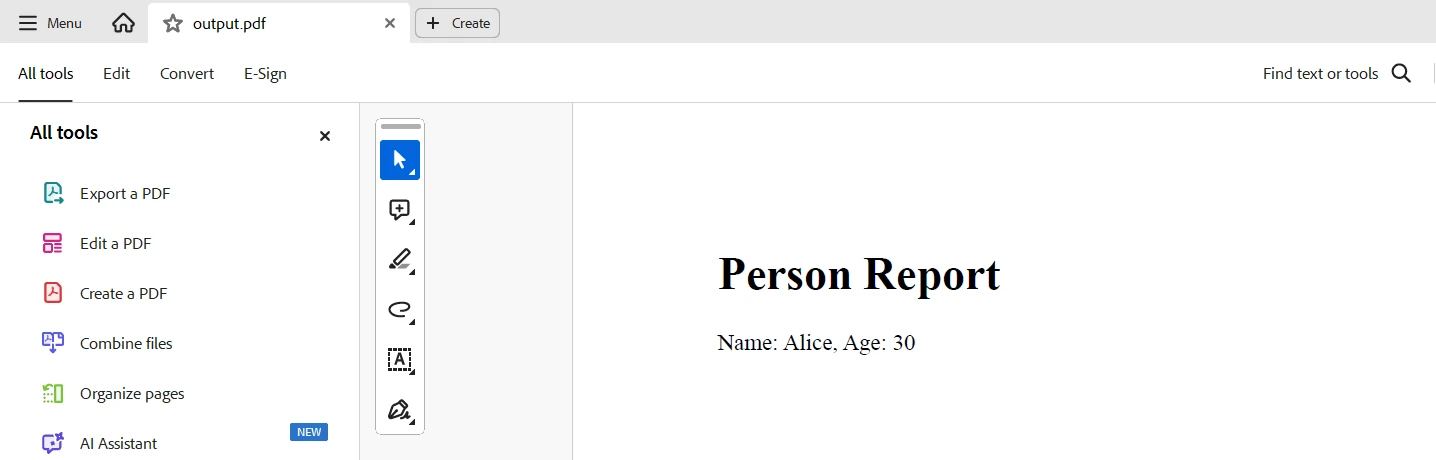
pdf_document.SaveAs("output.pdf")このコードは、TypeDBとIronPDFをPythonで使用して、TypeDBデータベースからデータを抽出し、PDFレポートを生成する方法を示しています。 ローカルのTypeDBサーバーに接続し、"Alice"という名前のエンティティを検索し、その名前と年齢を取得します。 その結果はHTMLコンテンツの構築に使用され、IronPDFのChromePdfRendererを使用してPDF文書に変換され、"output.pdf"として保存されます。
出力
ライセンス
生成されたPDFから透かしを削除するには、ライセンスキーが必要です。 このリンクで無料試用版に登録できます。 登録にクレジットカードは必要ありません; 無料試用版にはメールアドレスのみが必要です。
結論
Grakn(現在はTypeDB)とIronPDFの統合は、PDF文書からの大量データの管理と分析に対する堅牢なソリューションを提供します。 IronPDFのデータ抽出と操作の能力と、Graknの複雑な関係のモデリングと推論の専門性を組み合わせることで、非構造化の文書データを構造化されクエリ可能な情報に変換できます。
この統合はPDFから貴重な洞察を抽出し、クエリおよび分析能力を改善し、より高い精度で強化します。 Graknの高レベルのデータ管理をIronPDFのPDF処理機能と組み合わせることで、より効率的な情報処理方法を開発し、複雑なデータセットへの意思決定の向上と詳細な洞察を得ることができます。 Iron Softwareは、Windows、Android、macOS、Linuxなど複数のオペレーティングシステムおよびプラットフォームでのアプリケーション開発を容易にするさまざまなライブラリも提供しています。
















