
PyYAML(開発者向けのしくみ)
PyYAMLは、YAMLパーサー兼エミッタとして機能するPythonライブラリです。 YAML(YAML Ain't Markup Language)は、Pythonアプリケーションとよく統合される、人間に読みやすいデータシリアル化フォーマットで、優れたエラーサポート、強力な拡張APIなどを備えています。 YAMLは、設定ファイルや異なるデータ構造を持つ言語間のデータ交換に使われることが多く、人間の可読性を念頭に置いています。 この記事の後半では、IronPDF、Iron SoftwareからのPDF生成Pythonパッケージについて見ていきます。
PyYAMLの主要な機能
1.人間が読める形式: YAML は読み書きが容易になるように設計されており、複雑な構成ファイルやデータのシリアル化に最適です。
- YAML 1.1 の完全サポート: PyYAML は、Unicode サポートやカスタム データ型を含む、YAML 1.1 仕様を完全にサポートします。
- Python との統合: PyYAML は、任意の Python オブジェクトを表現できる Python 固有のタグを提供するため、さまざまなアプリケーションで汎用的に使用できます。 4.エラー処理: PyYAML はわかりやすいエラー メッセージを提供するため、デバッグ時に非常に役立ちます。
インストール
YAMLパッケージをインストールするには、pipを使用できます:
pip install pyyamlpip install pyyaml基本的な使い方
PyYAMLを使用して任意 for Pythonオブジェクトに対し、YAMLドキュメントをロードおよびダンプする簡単な例です。
import yaml
# Sample YAML data
yaml_data = """
name: John Doe
age: 30
children:
- name: Jane Doe
age: 10
- name: Jim Doe
age: 8
"""
# Load YAML data into a Python dictionary
data = yaml.safe_load(yaml_data)
print(data)
# Dump Python data back to formatted YAML
yaml_output = yaml.dump(data, default_flow_style=False)
print(yaml_output)import yaml
# Sample YAML data
yaml_data = """
name: John Doe
age: 30
children:
- name: Jane Doe
age: 10
- name: Jim Doe
age: 8
"""
# Load YAML data into a Python dictionary
data = yaml.safe_load(yaml_data)
print(data)
# Dump Python data back to formatted YAML
yaml_output = yaml.dump(data, default_flow_style=False)
print(yaml_output)出力

高度な機能
1.カスタム データ型: PyYAML を使用すると、標準 YAML 形式の複雑なデータ型を処理するためのカスタム コンストラクターとリプレゼンタを定義できます。
import yaml
# Define a custom Python object
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# Function to convert a Person object to a YAML representation
def person_representer(dumper, data):
return dumper.represent_mapping('!Person', {'name': data.name, 'age': data.age})
# Function to create a Person object from YAML representation
def person_constructor(loader, node):
values = loader.construct_mapping(node)
return Person(**values)
# Register custom representer and constructor for Person
yaml.add_representer(Person, person_representer)
yaml.add_constructor('!Person', person_constructor)
# Object Serialization
person = Person(name='John Doe', age=30)
yaml_data = yaml.dump(person)
print(yaml_data)
# Deserialize YAML to a Person object
loaded_person = yaml.load(yaml_data, Loader=yaml.FullLoader)
print(loaded_person.name, loaded_person.age)import yaml
# Define a custom Python object
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# Function to convert a Person object to a YAML representation
def person_representer(dumper, data):
return dumper.represent_mapping('!Person', {'name': data.name, 'age': data.age})
# Function to create a Person object from YAML representation
def person_constructor(loader, node):
values = loader.construct_mapping(node)
return Person(**values)
# Register custom representer and constructor for Person
yaml.add_representer(Person, person_representer)
yaml.add_constructor('!Person', person_constructor)
# Object Serialization
person = Person(name='John Doe', age=30)
yaml_data = yaml.dump(person)
print(yaml_data)
# Deserialize YAML to a Person object
loaded_person = yaml.load(yaml_data, Loader=yaml.FullLoader)
print(loaded_person.name, loaded_person.age)出力

2.大きなファイルの処理: PyYAML は、ストリームベースの読み込みとダンプを使用して、複数の YAML ドキュメントまたは大きな YAML ファイルを効率的に処理できます。
import yaml
# Load a large YAML file
with open('large_file.yaml', 'r') as file:
data = yaml.safe_load(file)
# Dump data to a large YAML file
with open('output_file.yaml', 'w') as file:
yaml.dump(data, file)import yaml
# Load a large YAML file
with open('large_file.yaml', 'r') as file:
data = yaml.safe_load(file)
# Dump data to a large YAML file
with open('output_file.yaml', 'w') as file:
yaml.dump(data, file)出力
![]()
IronPDFの紹介
IronPDFは、HTML、CSS、画像、JavaScriptを使用してPDFを作成、編集、署名するために設計された強力なPythonライブラリです。 低メモリフットプリントながら商用グレードのパフォーマンスを備えています。 主な機能は以下のとおりです:
- HTML から PDF への変換: HTML ファイル、HTML 文字列、および URL を PDF に変換します。 たとえば、Chrome PDFレンダラーを使用してウェブページをPDFとしてレンダリングします。
-クロスプラットフォーム サポート: .NET Core、 .NET Standard、 .NET Frameworkなど、さまざまな.NETプラットフォームと互換性があります。 Windows、Linux、macOSをサポートしています。
-編集と署名:プロパティを設定し、パスワードと権限でセキュリティを追加し、PDF にデジタル署名を適用します。
-ページ テンプレートと設定:ヘッダー、フッター、ページ番号、調整可能な余白を使用して PDF をカスタマイズします。 IronPDFはレスポンシブレイアウトとカスタム用紙サイズをサポートします。
-標準準拠: IronPDF は、 PDF/A や PDF/UA などの PDF 標準に準拠しています。 UTF-8文字エンコーディングをサポートし、画像、CSS、フォントなどのアセットを処理します。
IronPDFとPyYAMLでPDFドキュメントを生成する
import yaml
import json
from ironpdf import *
# Apply your license key
License.LicenseKey = "your license"
# Sample YAML data
yaml_data = """
name: IronPDF User1
age: 25
children:
- name: IronPDF User2
age: 23
- name: IronPDF User3
age: 24
"""
# Load YAML data into Python structures
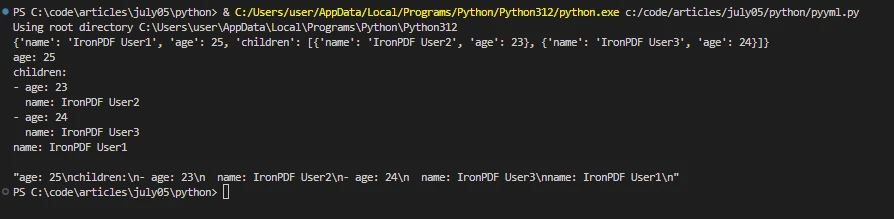
data = yaml.safe_load(yaml_data)
print(data)
# Dump Python data back to YAML
yaml_output = yaml.dump(data, default_flow_style=False)
print(yaml_output)
# Write YAML to File
with open('output_file.yaml', 'w') as file:
yaml.dump(yaml_output, file)
# Write YAML data as JSON
with open('output_file.json', 'w') as json_file:
json.dump(data, json_file)
# Read JSON and format with indentation for readability
output = json.dumps(json.load(open('output_file.json')), indent=2)
print(output)
# Create PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from HTML containing YAML data
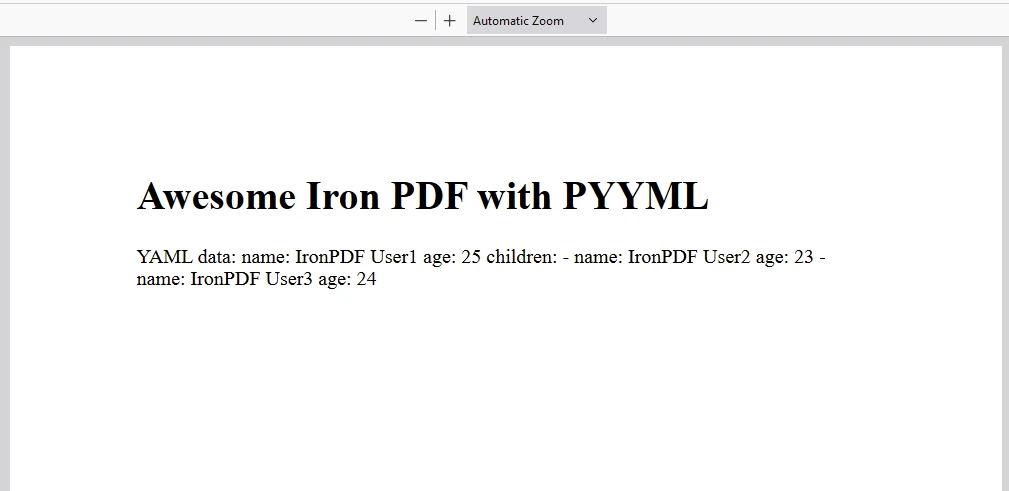
content = "<h1>Awesome Iron PDF with PyYAML</h1>"
content += "<p>YAML data: " + yaml_output + "</p>"
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF document to a file
pdf.SaveAs("awesome.pdf")import yaml
import json
from ironpdf import *
# Apply your license key
License.LicenseKey = "your license"
# Sample YAML data
yaml_data = """
name: IronPDF User1
age: 25
children:
- name: IronPDF User2
age: 23
- name: IronPDF User3
age: 24
"""
# Load YAML data into Python structures
data = yaml.safe_load(yaml_data)
print(data)
# Dump Python data back to YAML
yaml_output = yaml.dump(data, default_flow_style=False)
print(yaml_output)
# Write YAML to File
with open('output_file.yaml', 'w') as file:
yaml.dump(yaml_output, file)
# Write YAML data as JSON
with open('output_file.json', 'w') as json_file:
json.dump(data, json_file)
# Read JSON and format with indentation for readability
output = json.dumps(json.load(open('output_file.json')), indent=2)
print(output)
# Create PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from HTML containing YAML data
content = "<h1>Awesome Iron PDF with PyYAML</h1>"
content += "<p>YAML data: " + yaml_output + "</p>"
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF document to a file
pdf.SaveAs("awesome.pdf")コードの説明
インポート:
- 必要なライブラリをインポートします: YAML操作に
ironpdfを使用します。
- 必要なライブラリをインポートします: YAML操作に
ライセンスキーの設定:
- ライブラリへの合法的かつ機能的なアクセスのため、IronPDFのライセンスキーを設定します。
サンプルYAMLデータ:
- YAML操作を示すためのサンプルYAMLデータを定義します。
YAML操作:
yaml.safe_load()を使用して、YAMLデータを操作のためにPythonオブジェクトに変換します。
YAMLへのダンプ:
yaml.dump()を使用して、Pythonオブジェクトを出力用にYAML形式に戻します。
ファイルへの書き込み:
- YAMLデータをYAMLファイルに、JSONデータをJSONファイルにエクスポートし、保存または送信します。
JSONの読み込みとフォーマット:
- ファイルからJSONデータを読み込み、
json.dumps()を使用して可読性が高い形式に整えます。
- ファイルからJSONデータを読み込み、
IronPDFでのPDF生成:
- IronPDFを使用してHTML文字列をPDFドキュメントにレンダリングし、埋め込まれたYAMLデータを含めます。
PDFの保存:
- 生成されたPDFをファイルシステムに保存し、プログラミングによるPDF作成を示します。
出力
IronPDFライセンス
IronPDFはPythonのライセンスキーで動作します。 IronPDF for Pythonは、広範な機能を購入前にチェックできる無料トライアルライセンスキーを提供します。
スクリプトの冒頭にIronPDFパッケージを使用する前にライセンスキーを配置します。
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"結論
PyYAMLは、PythonでYAMLを操作する強力で柔軟なライブラリです。 その人間に読みやすいフォーマット、完全なYAML 1.1サポート、およびPythonとの統合により、設定ファイルやデータシリアル化などに最適な選択肢となります。 単純な構成から複雑なデータ構造まで、PyYAMLはYAMLデータを効果的に扱うのに必要なツールを提供しています。
IronPDFは、HTMLコンテンツをPDFドキュメントに変換するPythonパッケージです。 現代のウェブ標準であるCSSやJavaScriptを含むHTMLから高品質のPDFを生成するためのシンプルなAPI(ChromePdfRenderer)を提供します。 これにより、Pythonアプリケーションから直接PDFドキュメントを動的に作成および保存するための効果的なツールとなっています。
















