
PythonでPDFからテキストを行ごとに抽出する方法
このガイドでは、Python で IronPDF を使用して PDF ドキュメントからテキストを順番に抽出する際のニュアンスを説明します。 Python 環境の設定から PDF テキスト抽出用の最初の Python プログラムの実行まで、すべてをカバーします。
PDFから行ごとにテキストを抽出する方法
- Python を使用して PDF ライブラリをダウンロードしてインストールし、PDF ファイルの行からテキストを抽出します。
- 好みの IDE で Python プロジェクトを作成します。
- テキスト コンテンツを取得するために、必要な PDF ファイルを読み込みます。
- PDF をループし、組み込みライブラリの機能を使用してテキストを順番に抽出します。
- 抽出したテキストをファイルに保存します。
IronPDF PDF Python ライブラリ
IronPDFは、Python で PDF ファイルを操作できる便利なツールです。 PDF ファイルの読み取り、作成、編集を容易にする便利なアシスタントとしてお考えください。 PDF ドキュメントからコンテンツを抽出したり、最新の情報を追加したり、Web ページを PDF 形式に変換したりする場合でも、IronPDF は包括的なソリューションを提供します。 これは有料のソフトウェア パッケージですが、購入する前に試用版で試してみることができます。
スクリプトに進む前に、Python 環境を設定することが重要です。 このステップバイステップ ガイドは、環境を構成し、Visual Studio Code で新しい Python プロジェクトを作成し、IronPDF ライブラリ環境構成を設定するのに役立ちます。
Python のダウンロードとインストール: Python をインストールしていない場合は、公式 Python Web サイトから最新リリースをダウンロードします。 特定のオペレーティング システムのインストール手順に従ってください。
Python のインストールを確認します。ターミナルまたはコマンド プロンプトを開き、 python --versionと入力します。 このコマンドを実行すると、インストールされた Python のバージョンが出力され、インストールが成功したことが確認されます。
pip を更新: pipは Python パッケージ インストーラーです。 pip install --upgrade pip を実行して、最新であることを確認してください。
Visual Studio Code で新しい Python プロジェクトを作成する
Visual Studio Code をダウンロードします。まだインストールしていない場合は、公式 Web サイトからダウンロードしてください。
Python 拡張機能をインストールする: Visual Studio Code を開き、拡張機能マーケットプレイスに移動します。 Microsoft の Python 拡張機能を検索してインストールします。
新しいフォルダーの作成: Python プロジェクトを保存する新しいフォルダーを作成します。 PDF_Text_Extractorのような適切な名前を付けます。
VS Code でフォルダーを開く:フォルダーを Visual Studio Code にドラッグするか、 [ファイル] > [フォルダーを開く]メニュー オプションを使用してフォルダーを開きます。
Python ファイルを作成する: VS Code エクスプローラー パネルを右クリックし、 [新しいファイル]を選択します。 ファイルにmain.pyなどの名前を付けます。 このファイルには Python プログラムが保存されます。
 Visual Studio Codeで新しいPythonファイルを作成する
Visual Studio Codeで新しいPythonファイルを作成する
IronPDF ライブラリの要件とセットアップ
IronPDF は、PDF からテキスト コンテンツを取得するために不可欠です。 インストール方法は次のとおりです。
VS Code でターミナルを開く:**ターミナル > 新しいターミナル**に移動すると、VS Code 内でターミナルを開くことができます。
IronPDFをインストールします。ターミナルで次のコマンドを実行して、最新バージョンのIronPDFをインストールします。
pip install ironpdf
このプロセスでは、必要なモジュールとともに IronPDF ライブラリを取得してインストールします。
 IronPDFパッケージをインストールする
IronPDFパッケージをインストールする
これで完了です! これで、Python 環境のセットアップ、Visual Studio Code での新しいプロジェクトの作成、IronPDF ライブラリのインストールが完了しました。
PDFから行ごとにテキストを抽出
ライセンスキーの適用
続行する前に、IronPDF ライセンス キーを適用していることを確認してください。
from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"YOUR-LICENSE-KEY-HEREを実際のIronPDFライセンスキーに置き換えます。 このライセンスにより、プロジェクトのすべてのライブラリ機能のロックを解除できます。
PDFファイル形式の読み込み
既存の PDF ファイルを Python プログラムに読み込む必要があります。 これはIronPDFのPdfDocument.FromFileメソッドで達成できます。
pdfFileObj = PdfDocument.FromFile("content.pdf")pdfFileObj = PdfDocument.FromFile("content.pdf")"content.pdf"は、読みたい PDF ファイルを指します。 このロードされたPDFファイルはpdfFileObjとして使用されます。
PDF文書全体からテキストを抽出する
PDFファイルからすべてのテキストデータを一度に取得したい場合は、ExtractAllTextメソッドを使用できます。
all_text = pdfFileObj.ExtractAllText()all_text = pdfFileObj.ExtractAllText()ここではExtractAllTextメソッドがデモ目的で使用されています。 このメソッドはPDFファイルからすべてのテキストを抽出し、all_textという変数に格納します。
特定のPDFページからテキストを抽出する
IronPDFはExtractTextFromPageメソッドを使用して特定のページからテキストを抽出することを可能にします。 この方法は、一部のページのテキストのみが必要な場合に便利です。
page_2_text = pdfFileObj.ExtractTextFromPage(1)page_2_text = pdfFileObj.ExtractTextFromPage(1)ここでは、インデックス 1 に対応する 2 ページ目からテキストを抽出しています。
抽出したテキストを書き込むためのテキストファイルの初期化
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:with open("extracted_text.txt", "w", encoding='utf-8') as text_file:"extracted_text.txt"という名前のファイルを開き、テキスト データを保存します。 Pythonの組み込みencoding='utf-8'で処理します。
各ページをループして行ごとにテキストを抽出します
for i in range(0, pdfFileObj.get_Pages().Count):for i in range(0, pdfFileObj.get_Pages().Count):上記のコードはIronPDFのget_Pages().Countを使用してPDFファイル内の各ページをループして、総ページ数を取得します。
テキストを抽出して行に分割する
page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')各ページに対して、splitメソッドを使用して行ごとに分割します。 これにより、ループできる行のリストが生成されます。
抽出した行をテキストファイルに書き込む
for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')ここで、コードは行リスト内の各行を反復処理し、それをコンソールに出力し、各行の後に改行文字 ( \n ) を追加してファイルに書き込み、このテキストを適切にフォーマットします。
完全なコード
包括的な実装は次のとおりです。
from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')出力
Visual Studio Code ターミナルに次のコマンドを入力して、Python ファイルを実行します。
python main.pypython main.pyこの結果はターミナルに表示されます:
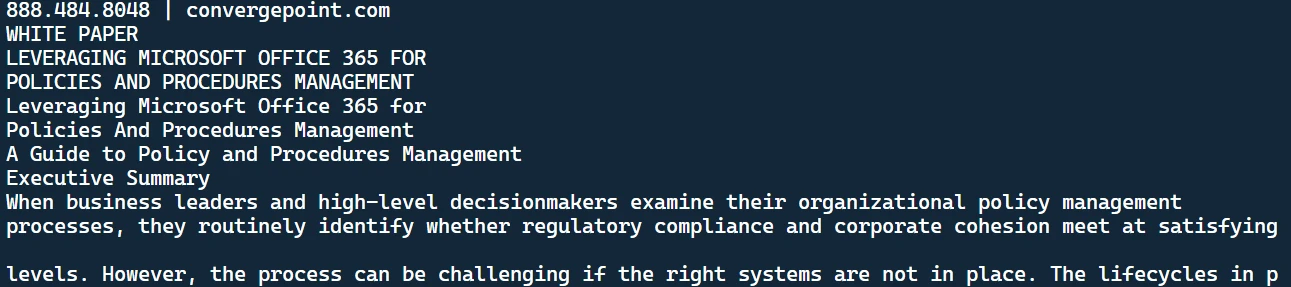 抽出されたテキスト
抽出されたテキスト
これはPDFファイルから取得されたテキストです。また、ディレクトリ内にテキストドキュメントが作成されていることにも気づくでしょう。
 抽出されたテキストはTXTファイルに保存されます
抽出されたテキストはTXTファイルに保存されます
このテキスト ファイルには、取得されたテキスト形式が順番に表示されます。
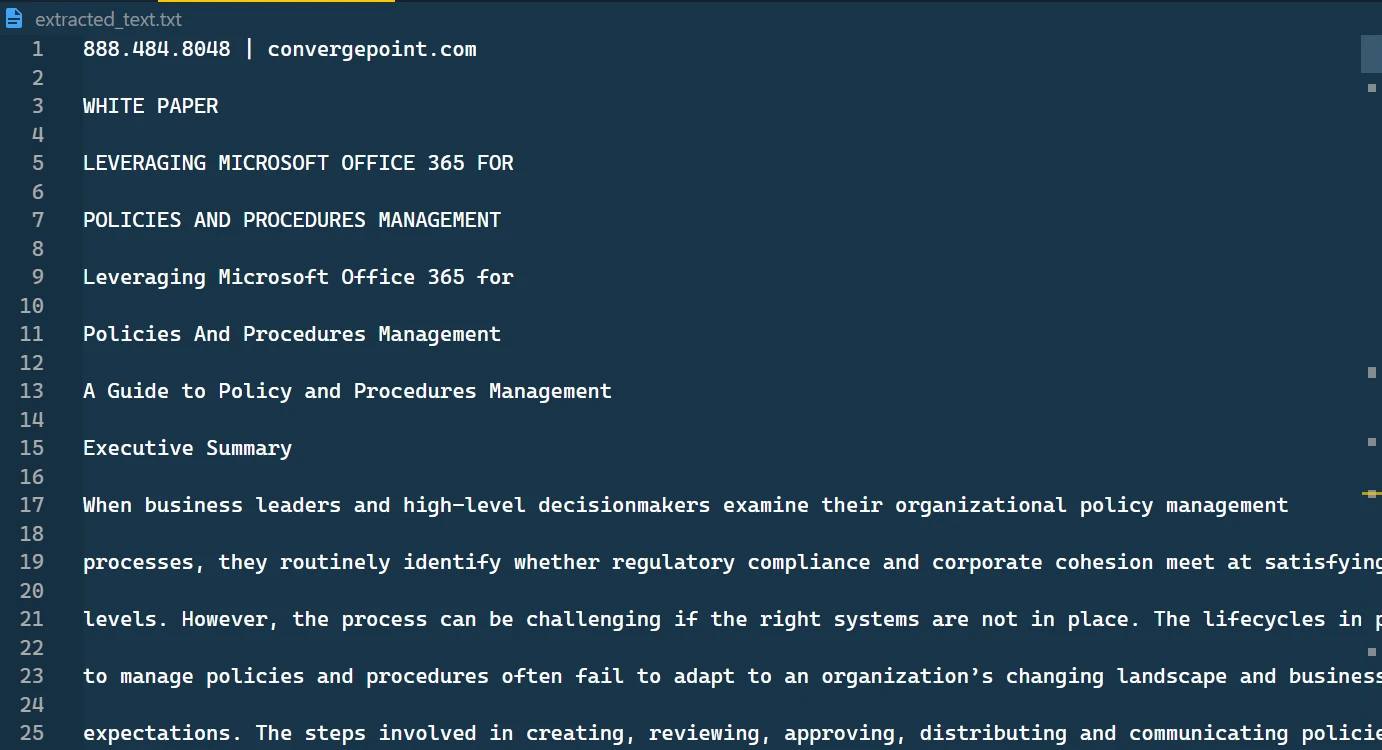 抽出されたテキストファイルの内容
抽出されたテキストファイルの内容
結論
結論として、IronPDFとPythonを使ってPDFファイルからテキストを抽出することは、文書全体、特定のページ、あるいは行単位など、どの範囲からでも堅牢かつシンプルなアプローチです。抽出したテキストをテキストファイルに保存できるという利点は、データを効率的に管理し、将来の処理に活用できるという点にもつながります。 IronPDF は、テキスト抽出だけでなくさまざまな機能を提供しており、PDF の処理に非常に役立つツールであることが証明されています。 IronPDF を使用してPython で PDF をテキストに変換することもできます。
さらに、インタラクティブ PDF の作成、インタラクティブ フォームの記入と送信、PDF ファイルの結合と分割、テキストと画像の抽出、PDF ファイル内のテキストの検索、 PDF から画像へのラスタライズ、フォント サイズ、境界線、背景色の変更、PDF ファイルの変換など、IronPDF ツールキットが役立つタスクはすべてあります。
IronPDF はオープンソースの Python ライブラリではありません。 プロジェクトでIronPDFを使用することを検討している場合、パッケージのライセンスは$799から始まります。 ただし、投資について明確な説明が必要な場合、IronPDF では機能を徹底的に調べるための無料トライアルを提供しています。
よくある質問
Pythonを使用してPDFからテキストを抽出するにはどうすればよいですか?
PythonでPDFファイルからテキストを抽出するにはIronPDFを使用できます。PdfDocument.FromFileメソッドを使用してPDFを読み込み、ページを反復してテキストを行ごとに抽出します。
PythonでPDFからテキストを抽出するために必要なものは何ですか?
PythonでPDFからテキストを抽出するには、PythonとpipでインストールできるIronPDFライブラリが必要です。スクリプトの作成と実行には、Visual Studio CodeなどのIDEが推奨されます。
IronPDFはPDFの特定のページからテキストを抽出できますか?
はい、IronPDFはページインデックスを指定することでExtractTextFromPageメソッドを使用してPDFの特定のページからテキストを抽出できます。
Pythonで抽出したテキストをファイルに保存するにはどうすれば良いですか?
IronPDFを使用してテキストを抽出した後、Pythonのファイル操作メソッドを使用して抽出されたテキストをテキストファイルに書き込むことで保存できます。
IronPDFはテキスト抽出以外にどのような機能を提供していますか?
IronPDFはPDFの作成、編集、変換、PDF文書のマージと分割、画像の抽出、PDFを他のファイル形式に変換するなどの幅広い機能を提供しています。
PythonプロジェクトでIronPDFをライセンスするにはどうすれば良いですか?
IronPDFをライセンスするには、Pythonスクリプト内のLicense.LicenseKeyプロパティを使用してライセンスキーを設定し、ライブラリの全機能を解放します。
購入前にIronPDFを試用することは可能ですか?
はい、IronPDFは購入を決める前に機能を評価できる試用版を提供しています。
PDFテキスト抽出中に問題が発生した場合はどうすれば良いですか?
IronPDFが正しくインストールおよびライセンスされていること、Python環境が正しく設定されているかを確認してください。一般的な問題のトラブルシューティングにはドキュメントやサポートリソースを参照してください。
IronPDFを使用してPDFを画像に変換できますか?
はい、IronPDFはPDFを画像にラスタライズする機能を提供しており、ドキュメント全体または特定のページを画像ファイルに変換できます。
PDFテキスト抽出のため for Pythonスクリプトを実行するにはどうすればよいですか?
スクリプトを書いた後、python main.pyをIDEのターミナルで実行することで、スクリプトを実行できます。ここでmain.pyはスクリプトファイルの名前です。
















