
How to Extract Text From PDF Line By Line
This guide will show the nuances of using IronPDF to extract text sequentially from PDF documents in Python. It will cover everything from setting up your Python environment to executing your first Python program for PDF text extraction.
How to Extract Text from PDF Line by Line
- Download and install the PDF library using Python to extract text from the PDF file line.
- Create a Python project in your preferred IDE.
- Load the desired PDF file for retrieving textual content.
- Loop through the PDF and extract text sequentially using the built-in library's function.
- Save the extracted text to a file.
IronPDF PDF Python Library
IronPDF is a handy tool that lets you work with PDF files in Python. Think of it as a helpful assistant that makes reading, creating, and editing PDF files accessible. Whether you aim to extract content from a PDF document, include fresh information, or transform a web page into a PDF format, IronPDF offers comprehensive solutions. It's a paid software package, but they offer a trial version for you to explore before committing to a purchase.
Before diving into the script, setting up your Python environment is essential. This step-by-step guide will help you configure your environment, create a new Python project in Visual Studio Code, and set up the IronPDF library environment configuration.
Download and Install Python: If you haven't installed Python, download the most recent release from the official Python website. Follow the installation instructions for your specific operating system.
Check Python Installation: Open your terminal or command prompt and type python --version. This command should print the installed Python version, confirming the installation was successful.
Update pip: Pip is the Python package installer. Make sure it's up to date by running pip install --upgrade pip.
Creating a New Python Project in Visual Studio Code
Download Visual Studio Code: If you don't have it, download it from the official website.
Install Python Extension: Open Visual Studio Code and head to the Extensions Marketplace. Search for the Python extension by Microsoft and install it.
Create a New Folder: Create a new folder where you want to house your Python project. Name it something relevant, like PDF_Text_Extractor.
Open the Folder in VS Code: Drag the folder into Visual Studio Code or use the File > Open Folder menu option to open the folder.
Create a Python File: Right-click in the VS Code Explorer panel and choose New File. Name the file main.py or something similar. This file will hold your Python program.
 Create new Python file in Visual Studio Code
Create new Python file in Visual Studio Code
IronPDF Library Requirement and Setup
IronPDF is essential for retrieving textual content from PDFs. Here's how to install it:
Open Terminal in VS Code: You can open a terminal inside VS Code by going to Terminal > New Terminal.
Install IronPDF: In the terminal, execute the following to install the latest version of IronPDF:
pip install ironpdf
This process retrieves and installs the IronPDF library along with any required modules.
 Install IronPDF package
Install IronPDF package
And there you have it! You've now successfully set up your Python environment, created a new project in Visual Studio Code, and installed the IronPDF library.
Extract Text From PDF Line By Line
Applying License Key
Before you proceed, make sure you apply your IronPDF license key.
from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Replace YOUR-LICENSE-KEY-HERE with your actual IronPDF license key. This license allows you to unlock all library features for your project.
Loading the PDF File Format
You need to load an existing PDF file into your Python program. You can achieve this with the PdfDocument.FromFile method from IronPDF.
pdfFileObj = PdfDocument.FromFile("content.pdf")pdfFileObj = PdfDocument.FromFile("content.pdf")"content.pdf" refers to the PDF file you wish to read. This loaded PDF file is stored in the pdfFileObj variable, used as a PDF reader or the PDF file object pdfFileObj.
Extracting Text from the Entire PDF Document
If you want to grab all the text data from the PDF file at once, you can use the ExtractAllText method.
all_text = pdfFileObj.ExtractAllText()all_text = pdfFileObj.ExtractAllText()The ExtractAllText method is used here for demonstration purposes. This method extracts all the text from the PDF file and stores it in a variable called all_text.
Extracting Text from a Specific PDF Page
IronPDF enables text extraction from a specific page using the ExtractTextFromPage method. This method is useful when you only need text from some pages.
page_2_text = pdfFileObj.ExtractTextFromPage(1)page_2_text = pdfFileObj.ExtractTextFromPage(1)Here, we're extracting text from the second page, corresponding to an index of 1.
Initializing a Text File for Writing Extracted Text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:with open("extracted_text.txt", "w", encoding='utf-8') as text_file:Open a file named "extracted_text.txt," to save the text data. The Python's built-in open function is used for this, setting the file mode to "write" ("w"), with encoding='utf-8' to handle Unicode characters.
Loop Through Each Page for Line by Line Text Extraction
for i in range(0, pdfFileObj.get_Pages().Count):for i in range(0, pdfFileObj.get_Pages().Count):The above code loops through each page in the PDF file using IronPDF's get_Pages().Count to get the total number of pages.
Extract Text and Segment It into Lines
page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')For each page, the ExtractTextFromPage method is used to get all the text and then use Python's split method to break it into lines. This results in a list of lines that can be looped through.
Write Extracted Lines to Text File
for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')Here, the code iterates through each line in the list of lines, printing it to the console, and writing it to the file by adding a newline character (\n) after each line to properly format this text.
Complete Code
Here is the comprehensive implementation:
from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')Output
Run the Python file by writing the following command in the Visual Studio Code terminal:
python main.pypython main.pyThis outcome will show on the terminal:
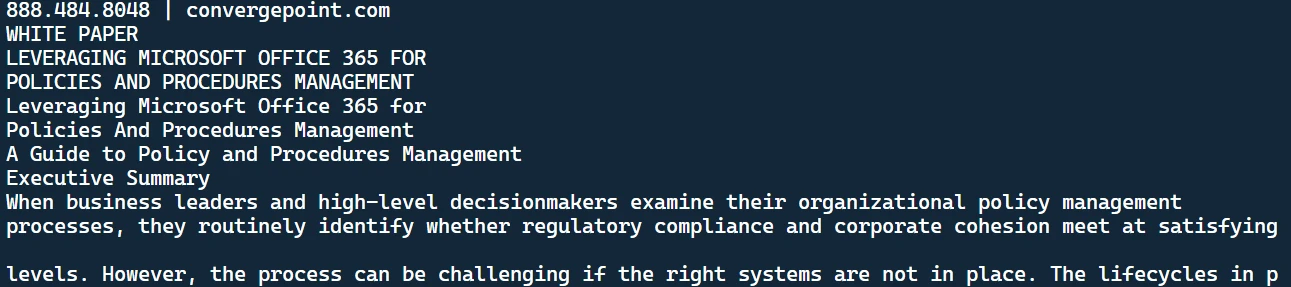 The extracted text
The extracted text
It is the retrieved text from the PDF file. You'll also notice a text document created in your directory.
 The extracted text stored in TXT file
The extracted text stored in TXT file
In this text file, you'll find the text format that has been retrieved, presented sequentially.
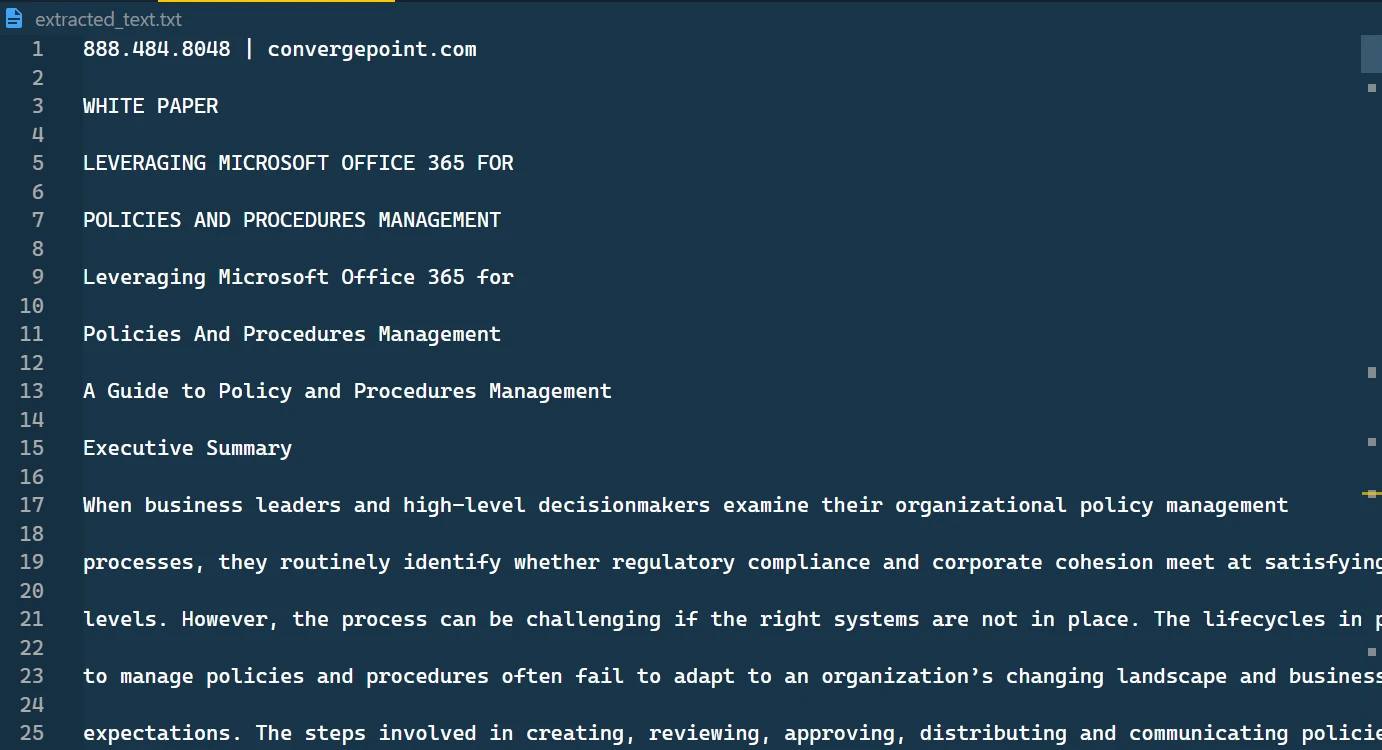 The extracted text file content
The extracted text file content
Conclusion
In conclusion, using IronPDF and Python to extract text from PDF files is a robust and straightforward approach, whether pulling text from the entire document, specific pages, or even line by line. The added benefit of saving this retrieved text into a text file enables you to efficiently manage and utilize the data for future processing. IronPDF proves to be an invaluable tool in handling PDFs, offering a range of functionalities beyond just text extraction. You can also convert PDF to Text in Python using IronPDF.
Additionally, creating interactive PDFs, completing and submitting interactive forms, merging and dividing PDF files, extracting text and images, searching text within PDF files, rasterizing PDFs to images, changing font size, border and background color, and converting PDF files are all tasks that the IronPDF toolkit can help with.
IronPDF is not an open-source Python library. If you're considering using IronPDF for your projects, the license for the package starts at $999. However, if you need clarification on the investment, IronPDF offers a free trial to explore its features thoroughly.
Frequently Asked Questions
How can I extract text from a PDF using Python?
You can use IronPDF to extract text from PDF files in Python. It involves loading the PDF with the PdfDocument.FromFile method and iterating through pages to extract text line by line.
What is required to start extracting text from PDFs in Python?
To extract text from PDFs in Python, you need to have Python installed, along with the IronPDF library, which can be installed via pip. An IDE like Visual Studio Code is recommended for writing and executing your scripts.
Can IronPDF extract text from a specific page in a PDF?
Yes, IronPDF allows you to extract text from a specific page of a PDF using the ExtractTextFromPage method by specifying the page index.
How can I save extracted text to a file in Python?
After extracting text using IronPDF, you can save it to a file by writing the extracted text lines to a text file using Python's file handling methods.
What additional features does IronPDF offer besides text extraction?
IronPDF offers a wide range of features including creating, editing, and converting PDFs, merging and splitting PDF documents, extracting images, and converting PDFs to other file formats.
How do I license IronPDF in my Python project?
To license IronPDF, set your license key in the Python script using the License.LicenseKey property, which unlocks the full functionality of the library.
Is it possible to trial IronPDF before purchasing?
Yes, IronPDF offers a trial version that allows you to evaluate its features before deciding to purchase a full license.
What should I do if I encounter issues during PDF text extraction?
Ensure that IronPDF is properly installed and licensed, and that your Python environment is correctly set up. Consult the documentation or support resources for troubleshooting common issues.
Can I convert a PDF to an image using IronPDF?
Yes, IronPDF provides functionality to rasterize PDFs into images, allowing you to convert entire documents or specific pages into image files.
How do I execute a Python script for PDF text extraction?
After writing your script, you can execute it by running python main.py in your IDE's terminal, where main.py is the name of your script file.
















