
How to Split PDF Files in Python
In the world of digital document management, the ability to manipulate and organize PDF files efficiently is a crucial skill for many developers and professionals. Python, a versatile and powerful programming language, offers a wide range of libraries and tools to tackle this task. One such task is splitting large PDF files, which can be essential for tasks like extracting specific pages, creating smaller documents, or automating document workflows.
In this article, we will explore the Python library that empowers us to split PDF files with ease, providing a comprehensive guide for anyone seeking to harness the potential of Python in their PDF manipulation endeavors. Whether you're a seasoned developer or a newcomer to Python, this article will equip you with the knowledge and tools necessary to split PDFs effectively and efficiently. The Python library and example we will use in this article is IronPDF for Python. It's one of the easiest with advanced features for manipulating PDF files.
How to Split PDF Files in Python
- Install the Python library for splitting PDF files.
- Utilize the RenderHtmlAsPdf method to generate a PDF file.
- Use the Split method in Python to split the generated PDF file.
- Save the newly generated PDF documents using the SaveAs method.
- Split the existing PDF file using the split method.
1. IronPDF for Python
IronPDF is a cutting-edge library that brings the power of PDF generation and manipulation to the world of Python programming. In today's digital age, creating and working with PDF documents is an integral part of countless applications and workflows, from generating reports to managing invoices and delivering content. IronPDF bridges the gap between Python and PDFs, offering developers a versatile and feature-rich solution for seamlessly creating, editing, and manipulating PDF files programmatically.
In this article, we will delve into the capabilities of IronPDF, exploring how it simplifies PDF-related tasks in Python and equips developers with the tools they need to harness the full potential of PDF documents in their applications. Whether you're building a web application, generating reports, or automating document workflows, IronPDF for Python is a powerful ally that can streamline your development process, save time, and enhance the functionality of your projects.
2. Creating a New Python Project
Creating a new Python project in PyCharm is a straightforward process that allows you to organize your Python scripts and manage dependencies efficiently. Here's a step-by-step guide on how to create a new Python project in PyCharm:
- Open PyCharm: Launch PyCharm if it's not already open. You should see the PyCharm welcome screen.
Create a New Project: Click on "File" in the top menu, then select "New Project...". You can also use the keyboard shortcut "Ctrl + Shift + N" (Windows/Linux) or "Cmd + Shift + N" (macOS) to open the New Project dialog.
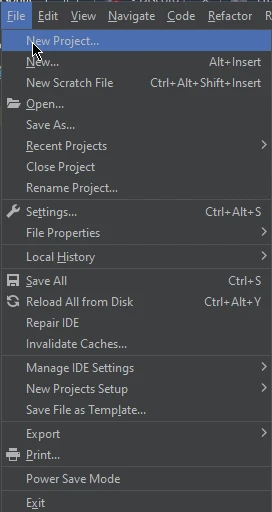
- Set Up Your Project:
- Project Location: Choose a location on your file system where you want to create the project directory. At the end of the location, write your project name.
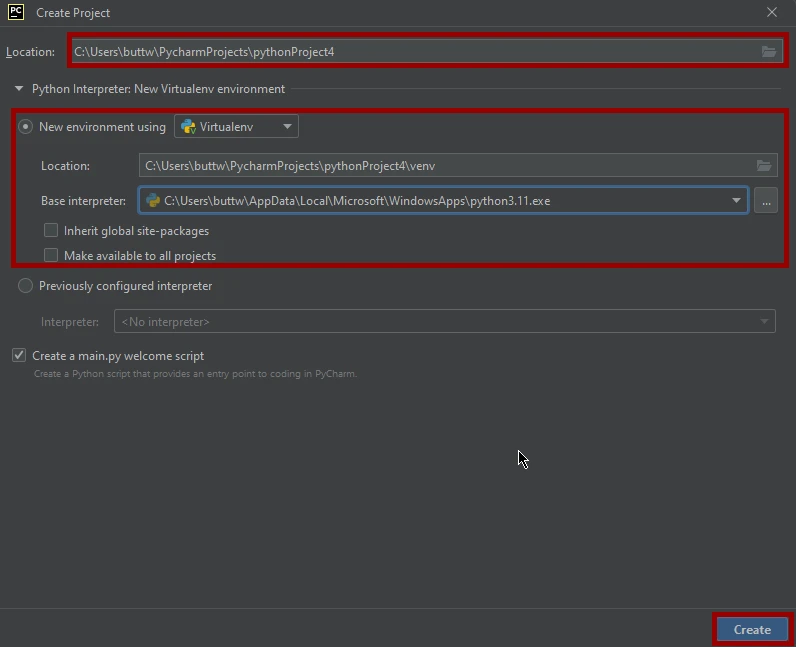
- Project Interpreter: Select the Python interpreter you want to use for this project. You can choose an existing interpreter or create a new one. It's recommended to use a virtual environment to isolate your project's dependencies.
Create: Click the "Create" button to create your new Python project.
3. Install IronPDF for Python
Prerequisite for IronPDF for Python
IronPDF for Python relies on the .NET 6.0 framework as its underlying technology. Therefore, it is necessary to have the .NET 6.0 SDK installed on your machine in order to use IronPDF for Python.
Installation
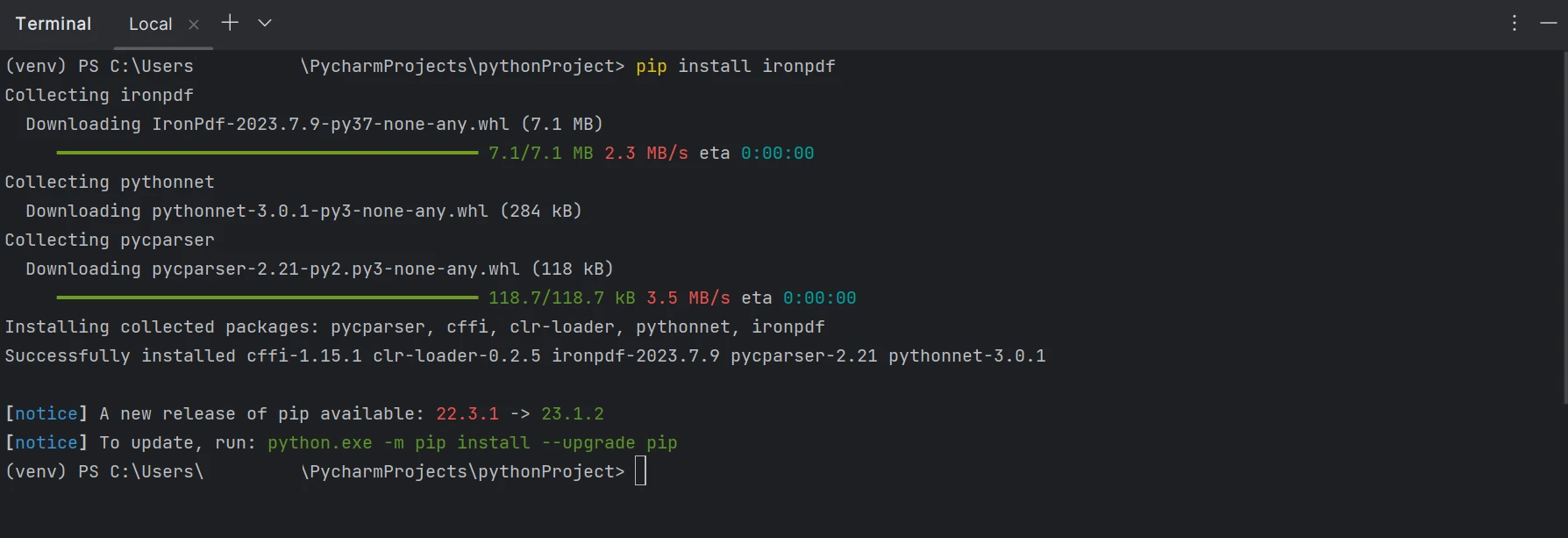
IronPDF can be easily installed using the system terminal or PyCharm's built-in command line terminal. Just run the following command, and IronPDF will be installed in a few seconds.
pip install ironpdf
The installation of the ironpdf package is shown in the screenshot below.
4. Split PDF Document Using IronPDF for Python
In this article, we will delve into the world of splitting PDFs using IronPDF for Python, exploring its features, functionalities, and demonstrating how it simplifies the often-complex task of extracting and managing PDF content, all while enhancing your Python-powered document processing endeavors.
In the code snippet below, we will see how you can easily split a PDF with just a few lines of code.
from ironpdf import ChromePdfRenderer
# Define HTML content with page breaks
html = """<p> Hello Iron </p>
<p> This is the 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is the 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is the 3rd Page</p>"""
# Render the HTML into a PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# Copy and save the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy and save the second and third pages as a single document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")from ironpdf import ChromePdfRenderer
# Define HTML content with page breaks
html = """<p> Hello Iron </p>
<p> This is the 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is the 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is the 3rd Page</p>"""
# Render the HTML into a PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# Copy and save the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy and save the second and third pages as a single document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")This Python script leverages IronPDF to split an HTML document into separate PDF files. It starts by defining an HTML content string containing multiple paragraphs, with page breaks indicated by the <div style='page-break-after: always;'></div> element. Next, it utilizes IronPDF's ChromePdfRenderer to render the HTML as a new PDF file.
Then, it copies the first page based on the page index (starting from 0) of the original file into a separate document named "Split1.pdf" using the function pdf.CopyPage(0). Finally, it creates another PDF containing the second and third PDF pages based on the number of pages using the function pdf.CopyPages(1, 2) and saves it as a new file named "Split2.pdf". This code showcases how IronPDF facilitates the extraction and splitting of PDF content into several PDF files, making it a valuable tool for PDF document manipulation in Python applications.
4.1. Output PDF Files
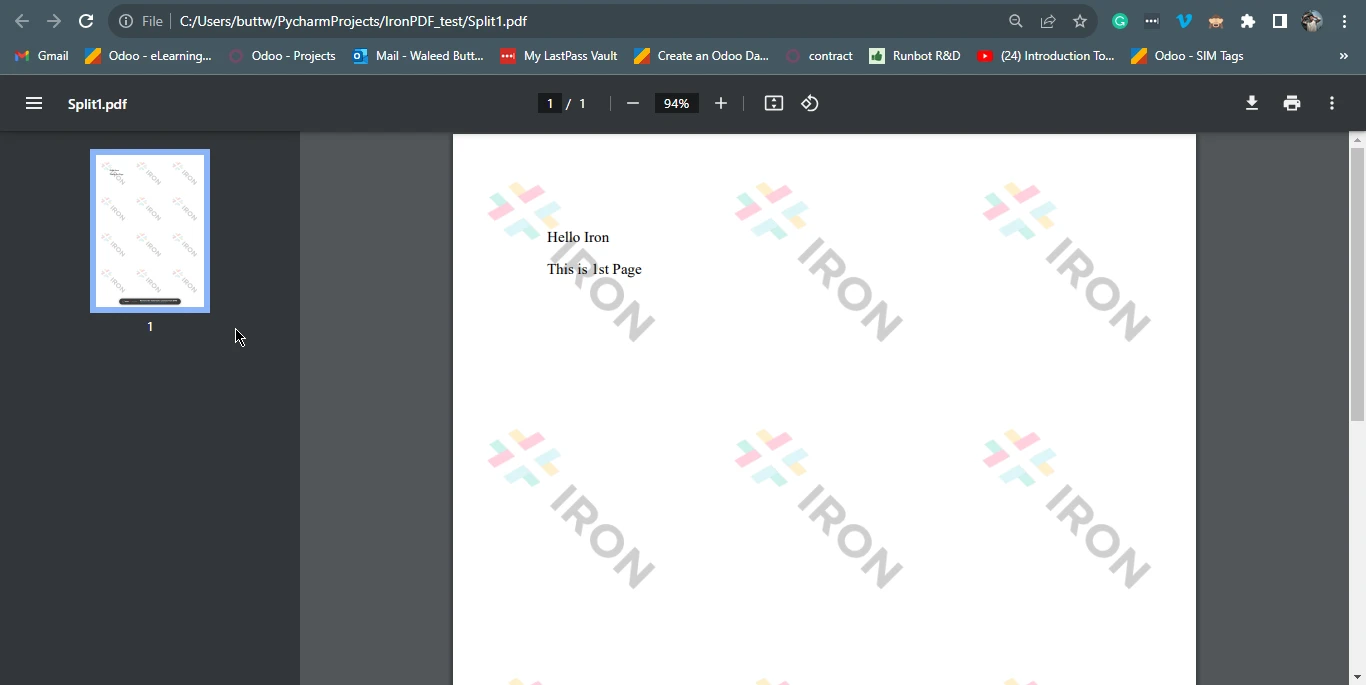
You can also split existing PDFs into several pages in a new PDF document format. To split an existing PDF into multiple PDF files, follow the code example below:
from ironpdf import PdfDocument
# Open the existing PDF document
pdf = PdfDocument("document.pdf")
# Copy and save the first page as a separate file
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy additional pages and save them as a separate document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")from ironpdf import PdfDocument
# Open the existing PDF document
pdf = PdfDocument("document.pdf")
# Copy and save the first page as a separate file
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy additional pages and save them as a separate document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")The above code opens an existing PDF using the PdfDocument method by providing the original file name and splits it into two separate PDF files.
5. Conclusion
Python's versatility and the powerful IronPDF library have been showcased in this article, providing a comprehensive guide for both novice and experienced developers seeking to split and manipulate PDF files efficiently. IronPDF bridges the gap between Python and PDFs, offering a feature-rich solution for various applications and workflows, from generating reports to automating document processes.
The article has not only guided readers through setting up a Python project and installing IronPDF but has also presented clear code examples for splitting PDFs, whether from HTML content or existing files. By harnessing IronPDF's capabilities, developers can enhance their document processing tasks, streamline their workflows, and unlock the full potential of processing PDF files and documents within their Python applications, making it a valuable asset for document management and manipulation.
For more information on HTML to PDF conversion with the IronPDF library, visit the following tutorial page. The code example on splitting PDF files can be found here.
IronPDF for Python offers a free trial license for commercial use to test out its complete functionality. After that, it needs to be licensed for commercial purposes. For more information, you can visit the IronPDF's license page.
Frequently Asked Questions
How can I split a PDF file using Python?
You can split a PDF file in Python using IronPDF by employing methods such as CopyPage and CopyPages, which allow you to extract specific pages from a PDF and save them as separate documents.
What steps are necessary to install IronPDF for Python?
To install IronPDF for Python, use the command pip install ironpdf. Ensure that you have the .NET 6.0 SDK installed on your machine, as it is a prerequisite for using IronPDF.
Can IronPDF convert HTML to PDF in Python?
Yes, IronPDF can convert HTML to PDF in Python using the RenderHtmlAsPdf method, which seamlessly transforms HTML web content into PDF format.
What are the benefits of splitting PDF files?
Splitting PDF files is beneficial for extracting specific pages, creating smaller, more manageable documents, and automating document workflows. This capability is crucial for efficient digital document management.
How can I automate document workflows using IronPDF?
IronPDF supports the automation of document workflows by providing tools to programmatically split, merge, and manipulate PDF documents within Python applications, streamlining processes and enhancing efficiency.
Is there a trial version available for IronPDF in Python?
Yes, IronPDF offers a free trial license for commercial use, allowing you to test its features and functionalities before committing to a commercial license for continued use.
How do you create a new Python project in PyCharm for PDF manipulation?
To create a new Python project in PyCharm, navigate to 'File' > 'New Project', set the desired project location and interpreter, then click 'Create'. This setup allows you to start integrating libraries like IronPDF.
Why is PDF manipulation important for developers?
PDF manipulation is crucial for developers as it enables the efficient organization, extraction, and management of PDF files, supporting various document workflows and applications in digital document management.
















