
Cómo Dividir Archivos PDF en Python
En el mundo de la gestión digital de documentos, la capacidad de manipular y organizar archivos PDF de manera eficiente es una habilidad crucial para muchos desarrolladores y profesionales. Python, un lenguaje de programación versátil y poderoso, ofrece una amplia gama de bibliotecas y herramientas para abordar esta tarea. Una de estas tareas es dividir archivos PDF grandes, lo cual puede ser esencial para tareas como extraer páginas específicas, crear documentos más pequeños o automatizar flujos de trabajo de documentos.
En este artículo exploraremos la biblioteca de Python que nos permite dividir archivos PDF con facilidad, brindando una guía completa para cualquiera que busque aprovechar el potencial de Python en sus esfuerzos de manipulación de PDF. Ya seas un desarrollador experimentado o un recién llegado a Python, este artículo te equipará con el conocimiento y las herramientas necesarias para dividir archivos PDF de manera efectiva y eficiente. La biblioteca de Python y el ejemplo que utilizaremos en este artículo es IronPDF for Python. Es una de las más fáciles con características avanzadas para manipular archivos PDF.
Cómo dividir archivos PDF en Python
- Instalar la biblioteca de Python para dividir archivos PDF.
- Utilizar el método RenderHtmlAsPdf para generar un archivo PDF.
- Usar el método Split en Python para dividir el archivo PDF generado.
- Guardar los nuevos documentos PDF generados utilizando el método SaveAs.
- Dividir el archivo PDF existente utilizando el método split.
1. IronPDF for Python
IronPDF es una biblioteca de última generación que lleva el poder de la generación y manipulación de PDF al mundo de la programación en Python. En la era digital de hoy, crear y trabajar con documentos PDF es una parte integral de innumerables aplicaciones y flujos de trabajo, desde generar informes hasta gestionar facturas y entregar contenido. IronPDF cierra la brecha entre Python y los PDF, ofreciendo a los desarrolladores una solución versátil y rica en funciones para crear, editar y manipular archivos PDF de manera fluida a nivel programático.
En este artículo, exploraremos las capacidades de IronPDF, analizando cómo simplifica las tareas relacionadas con PDF en Python y equipa a los desarrolladores con las herramientas que necesitan para aprovechar al máximo los documentos PDF en sus aplicaciones. Ya sea que estés construyendo una aplicación web, generando informes o automatizando flujos de trabajo de documentos, IronPDF for Python es un poderoso aliado que puede agilizar tu proceso de desarrollo, ahorrar tiempo y mejorar la funcionalidad de tus proyectos.
2. Creación de un nuevo proyecto Python
Crear un nuevo proyecto de Python en PyCharm es un proceso sencillo que te permite organizar tus scripts de Python y gestionar las dependencias de manera eficiente. Aquí tienes una guía paso a paso sobre cómo crear un nuevo proyecto de Python en PyCharm:
- Abrir PyCharm: Inicia PyCharm si no está abierto ya. Deberías ver la pantalla de bienvenida de PyCharm.
- Crear un nuevo proyecto: Haz clic en "File" en el menú superior, luego selecciona "New Project...". También puedes usar el atajo de teclado "Ctrl + Shift + N" (Windows/Linux) o "Cmd + Shift + N" (macOS) para abrir el diálogo de nuevo proyecto.
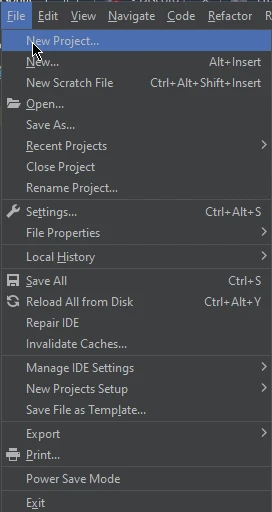 3. Configura tu proyecto:
3. Configura tu proyecto:
- Ubicación del proyecto: Elige dónde crear el directorio del proyecto.
- Ubicación del Proyecto: Elija una ubicación en su sistema de archivos donde desea crear el directorio del proyecto. - Intérprete de proyecto: Selecciona el intérprete de Python para este proyecto.
- Intérprete del Proyecto: Seleccione el intérprete de Python que desea utilizar para este proyecto. Se recomienda usar un entorno virtual para aislar las dependencias de tu proyecto. 4. Crear: Haz clic en el botón "Create" para crear tu nuevo proyecto de Python.
- Crear: Haga clic en el botón "Crear" para crear su nuevo proyecto de Python.
3. Instalar IronPDF for Python ### Prerrequisito para IronPDF for Python IronPDF for Python se basa en el marco .NET 6.0 como su tecnología subyacente.
3. Instalar IronPDF for Python
Requisitos previos para IronPDF for Python
IronPDF for Python se basa en el marco .NET 6.0 como su tecnología subyacente. 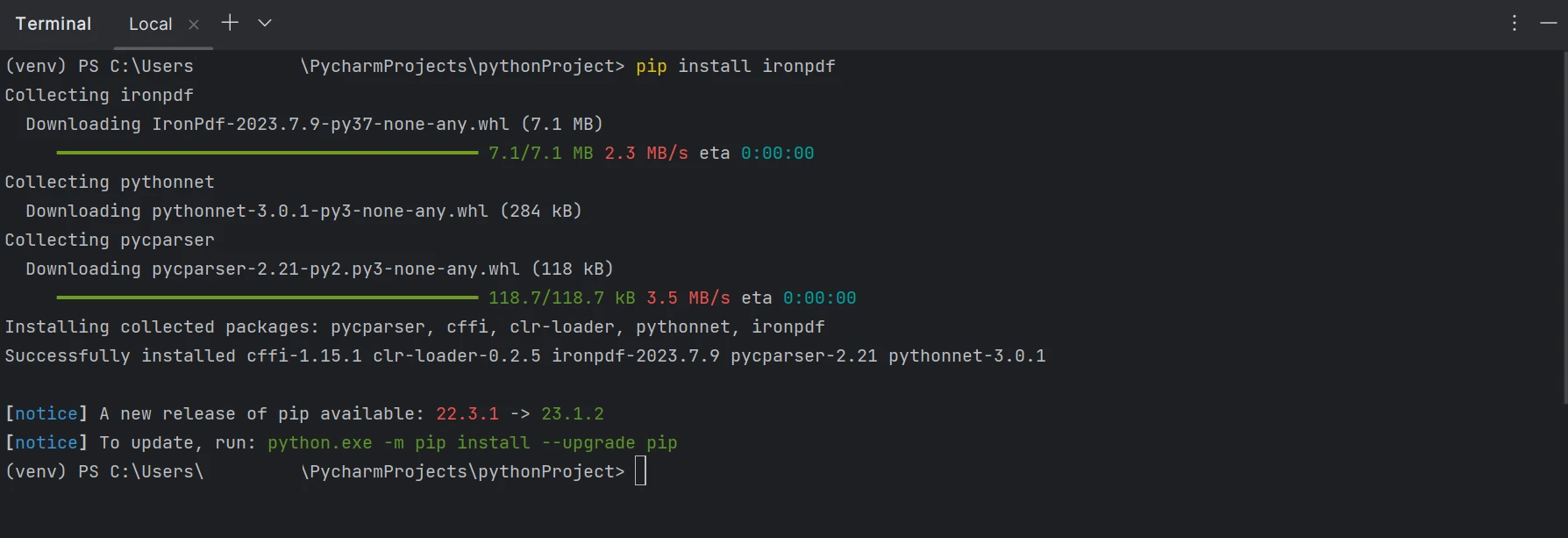
Instalación
IronPDF se puede instalar fácilmente utilizando el terminal del sistema o el terminal de línea de comandos integrado de PyCharm. Ejecuta el siguiente comando, e IronPDF se instalará en segundos.
pip install ironpdf
La instalación del paquete ironpdf se muestra en la captura de pantalla siguiente.
4. Dividir un documento PDF utilizando IronPDF for Python
Comienza definiendo una cadena de contenido HTML que contiene múltiples párrafos, con saltos de página indicados por el elemento <div style="page-break-after:> always;"></div>.
A continuación, utiliza ChromePdfRenderer de IronPDF para renderizar el HTML como un nuevo archivo PDF.
from ironpdf import ChromePdfRenderer
# Define HTML content with page breaks
html = """<p> Hello Iron </p>
<p> This is the 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is the 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is the 3rd Page</p>"""
# Render the HTML into a PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# Copy and save the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy and save the second and third pages as a single document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")from ironpdf import ChromePdfRenderer
# Define HTML content with page breaks
html = """<p> Hello Iron </p>
<p> This is the 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is the 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is the 3rd Page</p>"""
# Render the HTML into a PDF document
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# Copy and save the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy and save the second and third pages as a single document
page23doc = pdf.CopyPages(1, 2)
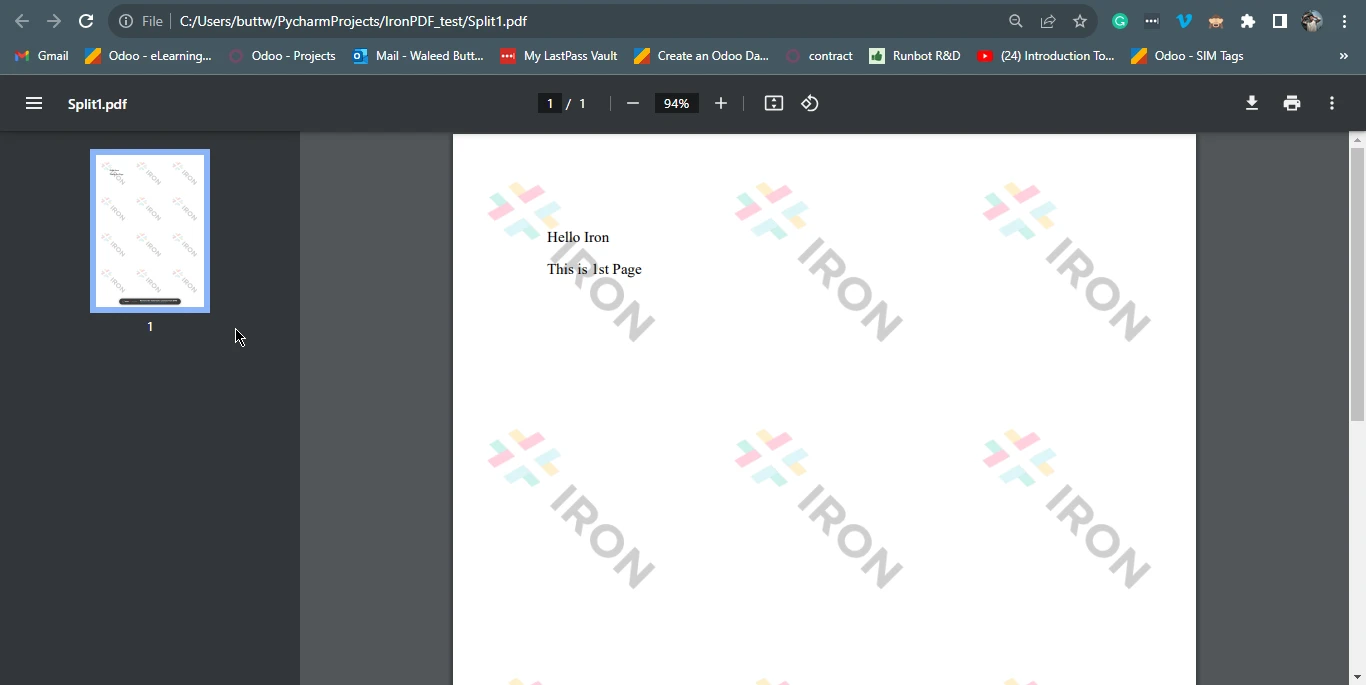
page23doc.SaveAs("Split2.pdf")Este script usa IronPDF para dividir un documento HTML en PDFs separados. Comienza definiendo una cadena de contenido HTML que contiene varios párrafos, con saltos de página indicados por el elemento <div style='page-break-after: always;'></div>. A continuación, utiliza ChromePdfRenderer de IronPDF para convertir el HTML en un nuevo archivo PDF.
A continuación, copia la primera página según el índice de páginas (empezando por 0) del archivo original en un documento independiente llamado "Split1.pdf" utilizando la función pdf.CopyPage(0). Por último, crea otro PDF que contiene la segunda y tercera páginas del PDF en función del número de páginas utilizando la función pdf.CopyPages(1, 2) y lo guarda como un nuevo archivo llamado "Split2.pdf". 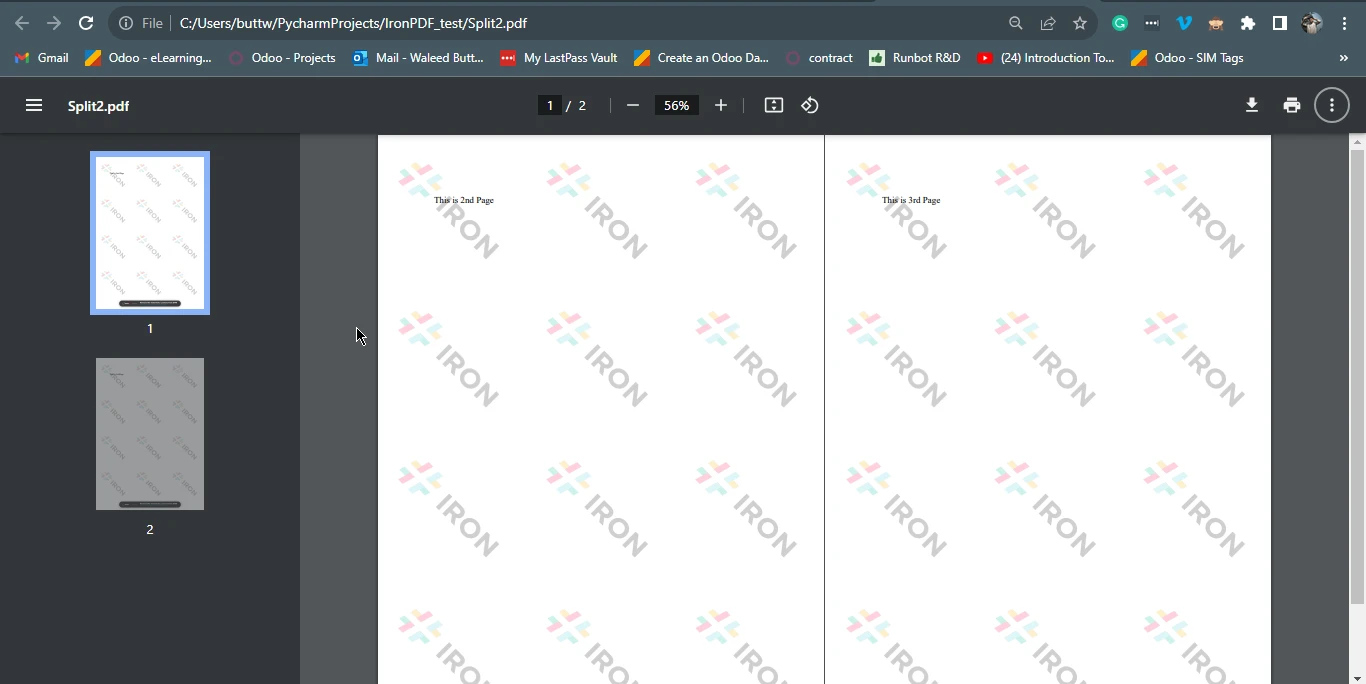
4.1. Salida de archivos PDF
4.1. Archivos PDF de Salida IronPDF une Python y PDFs, ofreciendo una solución rica en funciones para informes y automatización de documentos.
from ironpdf import PdfDocument
# Open the existing PDF document
pdf = PdfDocument("document.pdf")
# Copy and save the first page as a separate file
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy additional pages and save them as a separate document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")from ironpdf import PdfDocument
# Open the existing PDF document
pdf = PdfDocument("document.pdf")
# Copy and save the first page as a separate file
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# Copy additional pages and save them as a separate document
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")El código anterior abre un PDF existente utilizando el método PdfDocument, proporcionando el nombre del archivo original, y lo divide en dos archivos PDF separados.
5. Conclusión
Con IronPDF, los desarrolladores optimizan el procesamiento de documentos y flujos de trabajo, maximizando el manejo de PDFs en aplicaciones de Python. Para obtener más información sobre la conversión de HTML a PDF con la biblioteca IronPDF, visita la siguiente página de tutoriales.
El ejemplo de código sobre cómo dividir archivos PDF se puede encontrar aquí. IronPDF for Python ofrece una licencia de prueba gratuita para uso comercial para probar su funcionalidad completa.
Para más información sobre la conversión de HTML a PDF con la biblioteca IronPDF, visite la siguiente página de tutoriales. Para obtener más información, puedes visitar la página de licencias de IronPDF.
IronPDF for Python ofrece una licencia de prueba gratuita para uso comercial para probar su funcionalidad completa. Además, debe tener licencia comercial. Para obtener más información, puede visitar la página licencia de IronPDF.
Preguntas Frecuentes
¿Cómo puedo dividir un archivo PDF usando Python?
Puedes dividir un archivo PDF en Python usando IronPDF empleando métodos como CopyPage y CopyPages, que te permiten extraer páginas específicas de un PDF y guardarlas como documentos separados.
¿Qué pasos son necesarios para instalar IronPDF for Python?
Para instalar IronPDF for Python, usa el comando pip install ironpdf. Asegúrate de tener el SDK de .NET 6.0 instalado en tu máquina, ya que es un requisito previo para usar IronPDF.
¿Puede IronPDF convertir HTML a PDF en Python?
Sí, IronPDF puede convertir HTML a PDF en Python usando el método RenderHtmlAsPdf, que transforma sin problemas el contenido web HTML en formato PDF.
¿Cuáles son los beneficios de dividir archivos PDF?
Dividir archivos PDF es beneficioso para extraer páginas específicas, crear documentos más pequeños y manejables, y automatizar flujos de trabajo de documentos. Esta capacidad es crucial para una gestión eficiente de documentos digitales.
¿Cómo puedo automatizar flujos de trabajo de documentos usando IronPDF?
IronPDF admite la automatización de flujos de trabajo de documentos proporcionando herramientas para dividir, fusionar y manipular documentos PDF de forma programática dentro de aplicaciones Python, simplificando procesos y mejorando la eficiencia.
¿Existe una versión de prueba disponible para IronPDF en Python?
Sí, IronPDF ofrece una licencia de prueba gratuita para uso comercial, permitiéndote probar sus características y funcionalidades antes de comprometerte con una licencia comercial para su uso continuo.
¿Cómo se crea un nuevo proyecto de Python en PyCharm para la manipulación de PDF?
Para crear un nuevo proyecto de Python en PyCharm, navega a 'Archivo' > 'Nuevo Proyecto', establece la ubicación deseada del proyecto y el intérprete, luego haz clic en 'Crear'. Esta configuración te permite comenzar a integrar bibliotecas como IronPDF.
¿Por qué es importante la manipulación de PDF para los desarrolladores?
La manipulación de PDF es crucial para los desarrolladores ya que permite la organización, extracción y gestión eficiente de archivos PDF, apoyando varios flujos de trabajo de documentos y aplicaciones en la gestión de documentos digitales.
















