
How to Convert PDF to Text in Python (Tutorial)
This article will demonstrate how to use IronPDF for Python, one of the most powerful PDF libraries, to extract any text available in a PDF document.
How to Convert PDF to Text in Python
- Install a Python library to convert PDF to text
- Load an existing PDF document or render a new one
- Utilize the
ExtractAllTextmethod to read text from the opened file - Use another overload of the method to read text from specific page(s).
- Print the extracted text to the console or save it to a text file
2.0 How to Extract Text from a PDF Using Python?
- Install the latest version of Python from Python download page
- Open any IDE tools for Python
- Install .NET Core runtime
- Install the IronPDF for Python library or download from PyPI download page
- Extract text from the PDF
2.1 What is IronPDF for Python?
It is straightforward to integrate the IronPDF library in Python as it is a much more dynamic language compared to other languages and enables developers to create graphical user interfaces quickly and easily. It has a plethora of pre-installed tools, including PyQT, wxWidgets, kivy, and numerous additional packages and libraries, all of which may be used to rapidly and securely create a fully complete GUI.
IronPDF for Python is an extremely efficient library, particularly useful for web development. The availability of so many Python web development paradigms, like Django, Flask, and Pyramid, is partly to blame for this. These frameworks have been used by numerous websites and online services, including Reddit, Mozilla, and Spotify.
2.2 Features of IronPDF
- A PDF file can be created from a variety of sources, including HTML, HTML5, ASP, and PHP websites. In addition to HTML files, it is also possible to convert image files to PDF.
- IronPDF allows you to build interactive PDF documents, fill out and send interactive forms, split and combine PDF files, extract text and images from PDF files, search for certain words within a PDF file, rasterize PDF pages to images, convert PDF to HTML, and print PDF files.
- IronPDF can open PDF files and print from a URL. Additionally, it enables user agents to log in behind HTML login forms, proxies, cookies, HTTP headers, custom network login credentials, form variables, and user agents.
- Images can be extracted from documents using IronPDF.
- With IronPDF, it is very easy to add headers and footers, text and pictures, bookmarks and watermarks, and more to documents.
- It is possible to combine and separate pages using a new or existing document using IronPDF.
- Without utilizing an Acrobat viewer, documents can be converted to PDF objects.
- A CSS file can be used to make a PDF document.
- The creation of documents is possible using media-type CSS files.
2.3 Import IronPDF Library
Include the following import statements at the start of the source files where IronPDF will be used in order to import IronPDF:
from ironpdf import *from ironpdf import *2.4 Set License Key (if Required)
Although IronPDF for Python is free to use, it watermarks PDF files with a tiled backdrop for free users. You must give the library a legitimate license key in order to use IronPDF to create PDFs free of watermarks. How to set up the library with a license key is shown in the following snippet of code:
# Set the license key for IronPDF
License.LicenseKey = "IRONPDF-LICENSE-KEY-ABCDEFGH"# Set the license key for IronPDF
License.LicenseKey = "IRONPDF-LICENSE-KEY-ABCDEFGH"Before creating PDF files or making changes to their content, make sure the license key is configured. The LicenseKey method should be called before any other lines of code. To get a free trial license key, visit the licensing page.
2.5 Set Log Files
A text file called "Default" can store log messages produced by Custom.log within the Python script's directory. The code snippet below can be used to set the LogFilePath property and customize the log file name and location:
# Enable debugging and set the log file path and mode
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging and set the log file path and mode
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All3.0 Extract PDF Text with IronPDF
The IronPDF for Python library can convert PDF pages into PDF objects and enables text extraction from PDF files, which includes scanned PDF files. Here's an example that shows how to read an existing PDF using IronPDF.
The first method involves extracting all text available in a PDF; a sample of the code is provided below.
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract all the text from the entire PDF document
all_text = pdf.ExtractAllText()
# Display the extracted text
print(all_text)from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract all the text from the entire PDF document
all_text = pdf.ExtractAllText()
# Display the extracted text
print(all_text)As illustrated in the code above, the FromFile method is a PDF reader object which loads the existing PDF file and converts it into PDF-document objects. This object can be used to read the text and images that are available on the PDF pages. The object provides a method called ExtractAllText that pulls every piece of text from the whole PDF file, holding the text in a string that may be processed. And then use the print function to display the text.
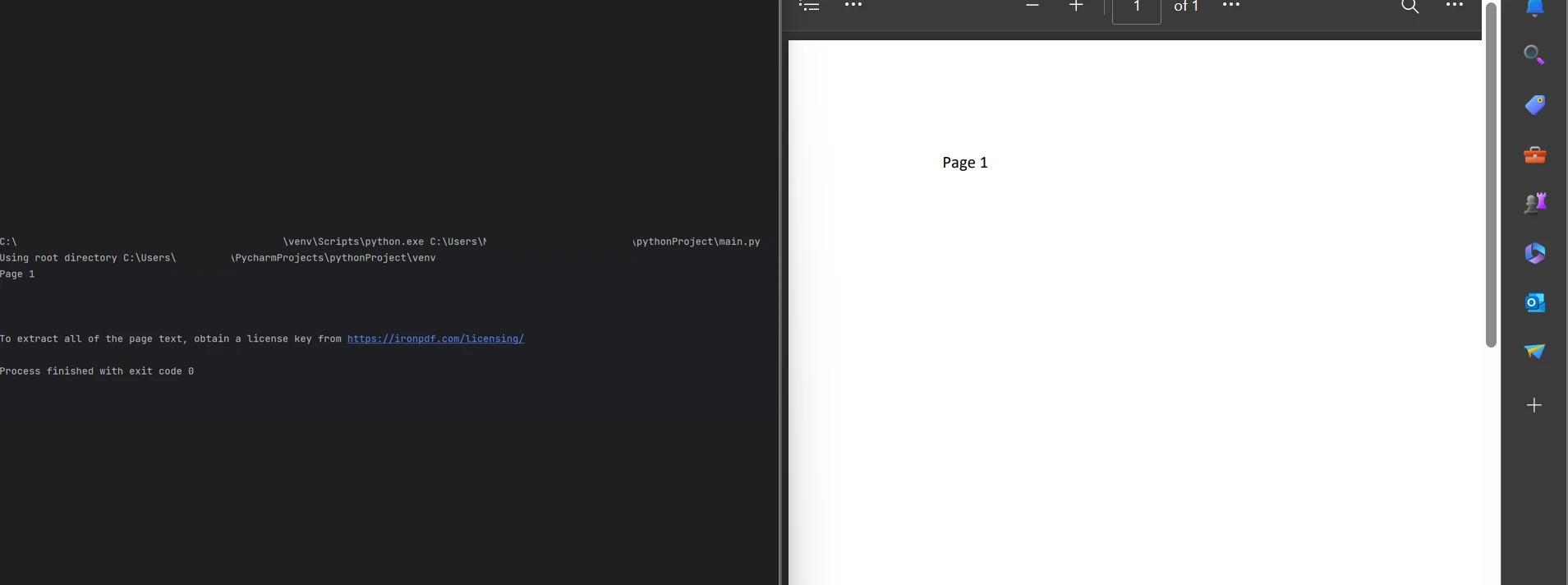 Displaying the text
Displaying the text
The code example for the second method that can be used to page-by-page, extracting text from a PDF file. It's provided below.
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Display the extracted text from the specified page
print(page_text)from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Display the extracted text from the specified page
print(page_text)The FromFile method is used to load the PDF file from an existing file and convert it into a PDF file object, as shown in the code above. A method on the PDF page object called ExtractTextFromPage retrieves all the text from a page in a PDF file. The page number must be provided as a parameter to extract text from that particular page. Then, after extracting the text, page_text can be used to hold the information that can be processed.
Check out more examples to extract text from a PDF.
4.0 Conclusion
The IronPDF library, in contrast, offers strong security measures to reduce potential risks. It is not tailored to any one browser and works with all commonly used ones. IronPDF allows programmers to easily produce and read PDF files with just a few lines of code. The IronPDF library provides a range of licensing options, including a free developer license and extra development licenses that are available for purchase, to meet the needs of different developers.
IronPDF includes a perpetual license, a 30-day money-back guarantee, a year of software support, and upgrade options. There are no additional expenses after the initial purchase. These licenses can be used in development, staging, and production environments. Learn more about product licensing.
Download the software product.
Frequently Asked Questions
How can I convert a PDF to text in Python?
You can convert a PDF to text in Python by using IronPDF's PdfDocument.FromFile method to load your PDF, and then employ the ExtractAllText or ExtractTextFromPage methods to extract the required text.
What setup is required to use a PDF library in Python?
To use IronPDF, you need to have Python and an IDE installed, along with the .NET Core runtime. IronPDF can be installed via the PyPI download page.
Can I extract text from a specific page in a PDF using Python?
Yes, with IronPDF, you can use the ExtractTextFromPage method to extract text from a specific page by providing the page number as a parameter.
Are there free options for using a PDF library in Python?
IronPDF for Python offers a free version that adds a watermark to PDFs. To remove watermarks and unlock full features, you would need a license key.
How do I integrate a PDF library with web frameworks like Django or Flask?
IronPDF seamlessly integrates with web frameworks such as Django and Flask, allowing you to generate and manipulate PDFs within your web application projects.
What features should I look for in a Python PDF library?
A comprehensive PDF library like IronPDF should support creating PDFs from HTML and images, extracting text, filling forms, merging PDFs, and adding bookmarks and watermarks.
How do I set a license key for a PDF library in Python?
For IronPDF, set the license key using the License.LicenseKey method before executing any other code to register your license and remove watermarks.
Does the Python PDF library support PDF creation from web pages?
IronPDF can create PDFs from HTML, HTML5, and web pages built with ASP or PHP, making it a versatile tool for web-based PDF generation.
How can I enable debugging in a PDF library for Python?
Enable debugging in IronPDF by setting Logger.EnableDebugging to true and defining a log file path using Logger.LogFilePath.
What are the security features of a Python PDF library?
IronPDF ensures security and cross-browser compatibility, offering a reliable solution for developers seeking secure PDF manipulation in Python.
















