
Cómo Convertir PDF A Texto en Python (Tutorial)
Este artículo demostrará cómo usar IronPDF for Python, una de las bibliotecas PDF más poderosas, para extraer cualquier texto disponible en un documento PDF.
Cómo convertir PDF a texto en Python
- Instalar una biblioteca Python para convertir PDF a texto
- Carga un documento PDF existente o renderiza uno nuevo
- Utilice el método
ExtractAllTextpara leer el texto del archivo abierto - Utilice otra sobrecarga del método para leer texto de páginas específicas.
- Imprimir el texto extraído en la consola o guardarlo en un archivo de texto
2.0 ¿Cómo extraer texto de un PDF con Python?
- Instale la última versión de Python desde la página de descargas de Python
- Abra cualquier herramienta IDE for Python
- Instalar el runtime de .NET Core
- Instalar la biblioteca IronPDF for Python o descargar desde la página de descargas de PyPI
- Extraer texto del PDF
2.1 ¿Qué es IronPDF for Python?
Es sencillo integrar la biblioteca IronPDF en Python ya que es un lenguaje mucho más dinámico en comparación con otros lenguajes y permite a los desarrolladores crear interfaces gráficas de usuario rápida y fácilmente. Cuenta con una gran cantidad de herramientas preinstaladas, incluyendo PyQT, wxWidgets, kivy, y numerosos paquetes y bibliotecas adicionales, todos los cuales pueden usarse para crear una interfaz gráfica de usuario completamente completa de manera rápida y segura.
IronPDF for Python es una biblioteca extremadamente eficiente, particularmente útil para el desarrollo web. La disponibilidad de tantos paradigmas de desarrollo web en Python, como Django, Flask y Pyramid, es en parte responsable de esto. Estos frameworks han sido utilizados por numerosos sitios web y servicios en línea, incluyendo Reddit, Mozilla y Spotify.
2.2 Características de IronPDF
- Un archivo PDF puede ser creado desde una variedad de fuentes, incluyendo sitios web HTML, HTML5, ASP y PHP. Además de los archivos HTML, también es posible convertir archivos de imagen a PDF.
- IronPDF permite crear documentos PDF interactivos, completar y enviar formularios interactivos, dividir y combinar archivos PDF, extraer texto e imágenes de archivos PDF, buscar ciertas palabras dentro de un archivo PDF, rasterizar páginas de PDF a imágenes, convertir PDF a HTML, y imprimir archivos PDF.
- IronPDF puede abrir archivos PDF e imprimir desde una URL. Además, permite a los agentes de usuario iniciar sesión detrás de formularios de inicio de sesión HTML, proxies, cookies, cabeceras HTTP, credenciales de inicio de sesión de red personalizadas, variables de formulario y agentes de usuario.
- Las imágenes pueden ser extraídas de documentos usando IronPDF.
- Con IronPDF, es muy fácil agregar encabezados y pies de página, texto e imágenes, marcadores y marcas de agua, y más a documentos.
- Es posible combinar y separar páginas usando un documento nuevo o existente utilizando IronPDF.
- Sin utilizar un visor de Acrobat, los documentos pueden ser convertidos a objetos PDF.
- Se puede usar un archivo CSS para crear un documento PDF.
- La creación de documentos es posible utilizando archivos CSS de tipo media.
2.3 Importar la biblioteca IronPDF
Incluya las siguientes declaraciones de importación al inicio de los archivos fuente donde se utilizará IronPDF para importar IronPDF:
from ironpdf import *from ironpdf import *2.4 Establecer la clave de licencia (si es necesario)
Aunque IronPDF for Python es gratuito de usar, pone marcas de agua en los archivos PDF con un fondo de mosaico para los usuarios gratuitos. Debe proporcionar a la biblioteca una clave de licencia legítima para usar IronPDF y crear PDFs libres de marcas de agua. Cómo configurar la biblioteca con una clave de licencia se muestra en el siguiente fragmento de código:
# Set the license key for IronPDF
License.LicenseKey = "IRONPDF-LICENSE-KEY-ABCDEFGH"# Set the license key for IronPDF
License.LicenseKey = "IRONPDF-LICENSE-KEY-ABCDEFGH"Antes de crear archivos PDF o realizar cambios en su contenido, asegúrese de que la clave de licencia esté configurada. El método LicenseKey debe llamarse antes que cualquier otra línea de código. Para obtener una clave de licencia de prueba gratuita, visite la página de licencias.
2.5 Establecer archivos de registro
Un archivo de texto llamado "Default" puede almacenar mensajes de registro producidos por Custom.log dentro del directorio del script de Python. El fragmento de código siguiente se puede utilizar para establecer la propiedad LogFilePath y personalizar el nombre y la ubicación del archivo de registro:
# Enable debugging and set the log file path and mode
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging and set the log file path and mode
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All3.0 Extraer texto PDF con IronPDF
La biblioteca IronPDF for Python puede convertir páginas PDF en objetos PDF y permite la extracción de texto de archivos PDF, lo cual incluye archivos PDF escaneados. Aquí hay un ejemplo que muestra cómo leer un PDF existente usando IronPDF.
El primer método implica extraer todo el texto disponible en un PDF; se proporciona una muestra del código a continuación.
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract all the text from the entire PDF document
all_text = pdf.ExtractAllText()
# Display the extracted text
print(all_text)from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract all the text from the entire PDF document
all_text = pdf.ExtractAllText()
# Display the extracted text
print(all_text)Como se ilustra en el código anterior, el método FromFile es un objeto lector de PDF que carga el archivo PDF existente y lo convierte en objetos de documento PDF. Este objeto se puede utilizar para leer el texto y las imágenes que están disponibles en las páginas del PDF. El objeto proporciona un método llamado ExtractAllText que extrae cada fragmento de texto de todo el archivo PDF, almacenando el texto en una cadena que puede procesarse. Y luego utilice la función print para mostrar el texto.
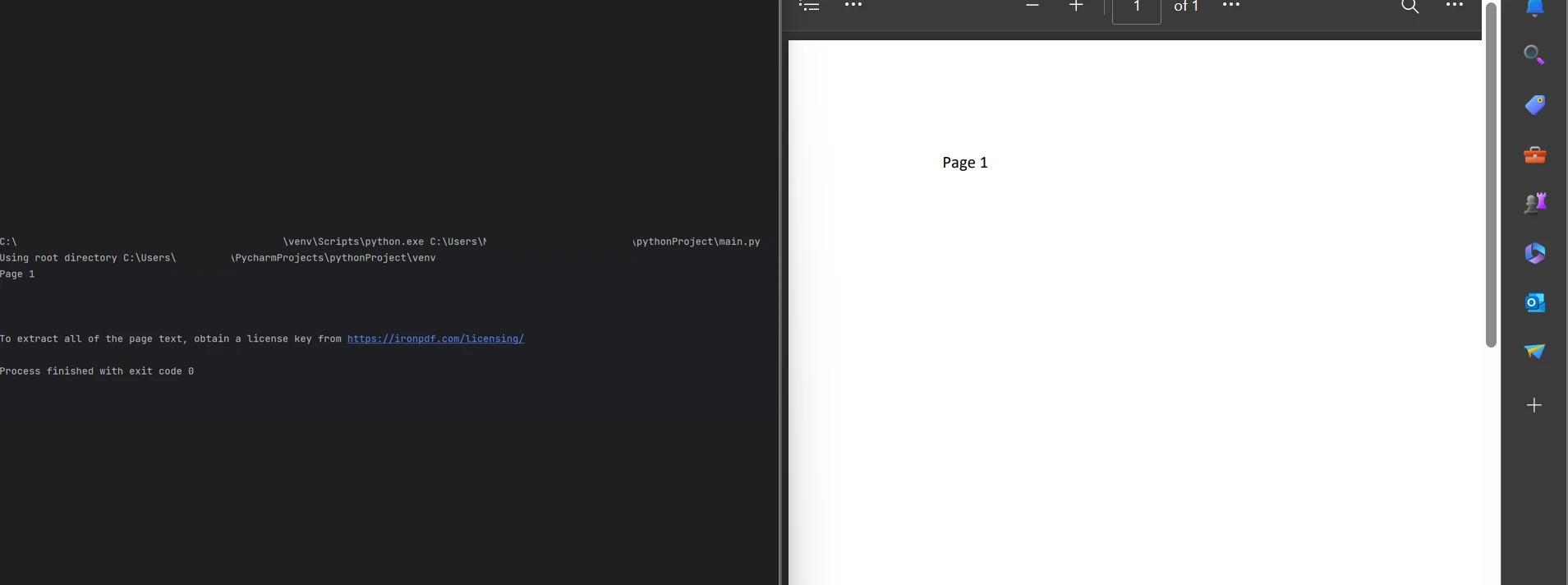 Mostrando el texto
Mostrando el texto
El ejemplo de código para el segundo método que se puede usar para extraer texto página por página de un archivo PDF se proporciona a continuación.
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Display the extracted text from the specified page
print(page_text)from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Display the extracted text from the specified page
print(page_text)El método FromFile se utiliza para cargar el archivo PDF desde un archivo existente y convertirlo en un objeto de archivo PDF, tal y como se muestra en el código anterior. Un método del objeto de página PDF denominado ExtractTextFromPage recupera todo el texto de una página de un archivo PDF. Se debe proporcionar el número de página como parámetro para extraer el texto de esa página en concreto. A continuación, tras extraer el texto, se puede utilizar page_text para almacenar la información que se va a procesar.
Consulte más ejemplos para extraer texto de un PDF.
4.0 Conclusión
La biblioteca IronPDF, en contraste, ofrece fuertes medidas de seguridad para reducir riesgos potenciales. No está diseñada para ningún navegador en particular y funciona con todos los más usados. IronPDF permite a los programadores producir y leer archivos PDF fácilmente con solo unas pocas líneas de código. La biblioteca IronPDF ofrece una variedad de opciones de licencia, incluyendo una licencia gratuita para desarrolladores y licencias de desarrollo adicionales que están disponibles para su compra, para satisfacer las necesidades de diferentes desarrolladores.
IronPDF incluye una licencia perpetua, una garantía de devolución de dinero de 30 días, un año de soporte de software y opciones de actualización. No hay costos adicionales después de la compra inicial. Estas licencias se pueden utilizar en entornos de desarrollo, pruebas y producción. Más sobre licencias de productos.
Descargar el producto de software.
Preguntas Frecuentes
¿Cómo puedo convertir un PDF a texto en Python?
Puedes convertir un PDF a texto en Python usando el método PdfDocument.FromFile de IronPDF para cargar tu PDF, y luego emplear los métodos ExtractAllText o ExtractTextFromPage para extraer el texto requerido.
¿Qué configuración es necesaria para usar una biblioteca PDF en Python?
Para usar IronPDF, necesitas tener Python y un IDE instalado, junto con el runtime de .NET Core. IronPDF puede instalarse a través de la página de descarga de PyPI.
¿Puedo extraer texto de una página específica en un PDF usando Python?
Sí, con IronPDF, puedes usar el método ExtractTextFromPage para extraer texto de una página específica proporcionando el número de la página como parámetro.
¿Hay opciones gratuitas para usar una biblioteca PDF en Python?
IronPDF for Python ofrece una versión gratuita que añade una marca de agua a los PDFs. Para eliminar las marcas de agua y desbloquear todas las funciones, necesitarías una clave de licencia.
¿Cómo integró una biblioteca PDF con frameworks web como Django o Flask?
IronPDF se integra perfectamente con frameworks web como Django y Flask, permitiéndote generar y manipular PDFs dentro de tus proyectos de aplicaciones web.
¿Qué características debo buscar en una biblioteca PDF for Python?
Una biblioteca PDF integral como IronPDF debería soportar la creación de PDFs desde HTML e imágenes, extracción de texto, relleno de formularios, fusión de PDFs y añadir marcadores y marcas de agua.
¿Cómo establezco una clave de licencia para una biblioteca PDF en Python?
Para IronPDF, establece la clave de licencia usando el método License.LicenseKey antes de ejecutar cualquier otro código para registrar tu licencia y eliminar marcas de agua.
¿La biblioteca Python PDF soporta la creación de PDF desde páginas web?
IronPDF puede crear PDFs desde HTML, HTML5 y páginas web construidas con ASP o PHP, convirtiéndola en una herramienta versátil para la generación de PDFs basados en la web.
¿Cómo puedo habilitar la depuración en una biblioteca PDF for Python?
Habilita la depuración en IronPDF configurando Logger.EnableDebugging en verdadero y definiendo una ruta de archivo de registro usando Logger.LogFilePath.
¿Cuáles son las características de seguridad de una biblioteca PDF for Python?
IronPDF garantiza la seguridad y compatibilidad entre navegadores, ofreciendo una solución confiable para desarrolladores que buscan manipulación segura de PDFs en Python.
















