
HTTPX Python (Jak działa: Przewodnik dla programistów)
HTTPX to nowoczesny, w pełni funkcjonalny klient HTTP dla języka Python, wyposażony w synchroniczne i asynchroniczne interfejsy API. Biblioteka ta zapewnia wysoką wydajność w obsłudze żądań HTTP. Kilka funkcji tej biblioteki stanowi rozszerzenie tradycyjnych bibliotek, takich jak Requests; Dlatego jest bardziej wydajny, ponieważ obsługuje HTTP/2, pulę połączeń i zarządzanie plikami cookie.
Zintegrowany z IronPDF, kompleksową biblioteką .NET do tworzenia i edycji wszystkich dokumentów PDF, HTTPX może pobierać dane z interfejsów API lub nawet stron internetowych i przekształcać je w długie, ładnie sformatowane raporty PDF. Dzięki możliwości generowania plików PDF z HTML, obrazów i zwykłego tekstu przez IronPDF można tworzyć profesjonalne, atrakcyjne wizualnie dokumenty, a nawet korzystać z zaawansowanych funkcji, takich jak dodawanie nagłówków, stopek i znaków wodnych. Integracja jest kompletna: od pobierania danych po tworzenie raportów, oferuje ona wydajny sposób przekazywania spostrzeżeń w dopracowanej formie.
Czym jest Httpx python?
HTTPX to nowoczesny klient HTTP nowej generacji dla języka Python, który wykorzystuje kilka ciekawych sposobów korzystania z popularnej biblioteki Requests i łączy je z obsługą synchronicznych i asynchronicznych interfejsów API. Ma on na celu rozwiązywanie złożonych zadań HTTP za pomocą różnych zaawansowanych funkcji, takich jak obsługa HTTP/2, pulowanie połączeń, a nawet automatyczne zarządzanie plikami cookie. HTTPX umożliwia programistom wysyłanie wielu różnych żądań HTTP jednocześnie, przyspieszając działanie aplikacji w przypadkach, gdy interakcje internetowe stanowią główną oczekiwaną funkcjonalność.
Oferuje doskonałą interoperacyjność z biblioteką Requests, zapewniając łatwą ścieżkę aktualizacji dla programistów pragnących zaktualizować swojego klienta HTTP i uzyskać dostęp do bardziej złożonych funkcji. HTTPX to elastyczne narzędzie do nowoczesnego programowania w języku Python; nadaje się dobrze do zadań od prostych zapytań HTTP po bardziej skomplikowane interakcje internetowe, w których kluczowa jest wydajność. HTTPX może obsługiwać zarówno żądania synchroniczne, jak i asynchroniczne z obsługą połączeń przez proxy SOCKS.
Funkcje Httpx python
HTTPX w języku Python zapewnia najbardziej przydatne funkcje, które rozszerzają i usprawniają obsługę żądań HTTP. Oto niektóre z jego kluczowych funkcji:
Synchroniczne i asynchroniczne interfejsy API:
Obsługuje zarówno synchroniczne, jak i asynchroniczne przetwarzanie żądań. Programista może zastosować dowolną z dostępnych opcji w aplikacji w zależności od swoich potrzeb.
Obsługa HTTP/2:
Ta platforma oferuje natywną obsługę protokołu HTTP/2, co pozwala na szybszą i bardziej wydajną komunikację z serwerami, które go obsługują.
Pula połączeń:
Inteligentne połączenie HTTP: ponowne wykorzystanie już nawiązanych połączeń i sesji puli połączeń w celu zmniejszenia opóźnień i zwiększenia szybkości obsługi wielu żądań.
Automatyczne dekodowanie treści:
Automatyzuje dekodowanie skompresowanej odpowiedzi, zazwyczaj zakodowanej w formacie gzip, co znacznie ułatwia obsługę i zmniejsza zapotrzebowanie na przepustowość.
Limity czasu i ponowne próby:
Zdefiniuj ustawienia limitu czasu dla żądań gwarantujących brak blokowania, które przekraczają limit czasu żądania — dodatkowe mechanizmy ponawiania prób w celu radzenia sobie z przejściowymi awariami.
Obsługa WebSockets:
Obsługuje połączenia WebSocket, umożliwiając dwukierunkową komunikację między klientem a serwerem za pośrednictwem jednego, długotrwałego połączenia.
Obsługa serwerów proxy:
Posiada wbudowaną obsługę serwerów proxy HTTP. Umożliwi to wysyłanie żądań przez serwery pośredniczące w celu zapewnienia prywatności lub zarządzania siecią.
Obsługa plików cookie:
Biblioteka będzie obsługiwać pliki cookie, śledząc stan sesji między żądaniami.
Certyfikat klienta:
Obsługiwane są certyfikaty po stronie klienta w celu zabezpieczenia komunikacji z serwerami korzystającymi z wzajemnego uwierzytelniania TLS.
Oprogramowanie pośredniczące i haki:
Umożliwia dostosowanie obsługi żądań i odpowiedzi za pomocą oprogramowania pośredniczącego i haków. Zapewnia to programistom doskonałą rozszerzalność, umożliwiającą rozszerzenie funkcjonalności HTTPX zgodnie z ich wymaganiami. Kompatybilność z Requests: Został zaprojektowany do korzystania z API Requests, co znacznie ułatwia programistom korzystającym z Requests przejście na projekt HTTPX i uzyskanie wielu nowych, doskonałych funkcji oraz ulepszeń.
Utwórz i skonfiguruj Httpx w języku Python.
Najpierw należy zainstalować bibliotekę i skonfigurować środowisko w celu skonfigurowania HTTPX w języku Python. Projekt HTTPX opiera się na bibliotece HTTP Core i bibliotece async, które są wykrywane automatycznie jako zależności, ale powinny być zainstalowane bezpośrednio podczas instalacji projektu HTTPX. Istnieje również odmiana HTTPX jako klient wiersza poleceń, który oferuje bogatą obsługę terminali; Jednak w tym artykule skupimy się wyłącznie na HTTPX w języku Python. Poniższy przewodnik przedstawia przykład prostego żądania HTTP GET. Bardziej wyczerpujące informacje na temat Dokumentacji API można znaleźć w dokumentacji HTTPX dostępnej tutaj.
Zainstaluj HTTPX
Najpierw upewnij się, że masz zainstalowany HTTPX. Do instalacji można użyć klienta wiersza poleceń:
pip install httpxpip install httpxZaimportuj HTTPX i wyślij podstawowe żądanie
Po zainstalowaniu można zaimportować HTTPX i wysłać proste żądanie HTTP GET w następujący sposób:
import httpx
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
# Create a client instance to manage HTTP requests
response = httpx.get(url)
# Print response HTTP status codes and content
print(f"Status Code: {response.status_code}")
# Print Unicode Response Bodies
print(f"Response Content: {response.text}")import httpx
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
# Create a client instance to manage HTTP requests
response = httpx.get(url)
# Print response HTTP status codes and content
print(f"Status Code: {response.status_code}")
# Print Unicode Response Bodies
print(f"Response Content: {response.text}")- Funkcja fetch_data, wykorzystująca wewnątrz asynchroniczny menedżer kontekstu do otwarcia klienta HTTP, wysyła żądanie GET do podanego adresu URL.
- Przechowuje obiekt odpowiedzi HTTP zwrócony przez
httpx.get(url).
Konfiguracja zaawansowanych funkcji w HTTPX
Zaawansowane funkcje HTTPX obsługują szeroki wachlarz innych konfiguracji, takich jak obsługa serwerów proxy, nagłówków i limitów czasu. Oto jak skonfigurować HTTPX z dodatkowymi opcjami:
import httpx
def fetch_data_with_config(url):
# Create a client with a timeout and custom headers
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Print response status code and content
print(f"Status Code: {response.status_code}")
print(f"Response Content: {response.json()}")import httpx
def fetch_data_with_config(url):
# Create a client with a timeout and custom headers
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Print response status code and content
print(f"Status Code: {response.status_code}")
print(f"Response Content: {response.json()}")- Timeout: Ustawia limit czasu dla żądania HTTP na 30 sekund. Ma to na celu zapobieżenie blokowaniu żądania na czas nieokreślony.
- Dodaje niestandardowy nagłówek
User-Agentdo żądania{ "User-Agent": "MyApp/1.0" }, identyfikujący aplikację kliencką. - response.json() - Analizuje zawartość odpowiedzi jako JSON, zakładając, że odpowiedź zawiera dane JSON.

Pierwsze kroki
Aby używać HTTPX z Pythonem i IronPDF do generowania plików PDF. Najpierw należy skonfigurować HTTPX do pobierania danych z określonego źródła, a następnie IronPDF utworzy raport PDF na podstawie uzyskanych danych. Oto szczegółowa instrukcja:
Czym jest IronPDF?
Potężna i solidna biblioteka Python IronPDF umożliwia tworzenie, edycję i odczyt plików PDF. Pozwala to programistom na wykonywanie wielu operacji programowych na plikach PDF, takich jak edycja istniejących plików PDF oraz konwersja plików HTML do formatu PDF. IronPDF sprawia, że generowanie wysokiej jakości raportów w formacie PDF jest prostsze i bardziej elastyczne. Dzięki temu rozwiązanie to sprawdza się w aplikacjach, które dynamicznie tworzą i przetwarzają pliki PDF.
Konwersja HTML do PDF
IronPDF umożliwia konwersję dowolnych danych HTML na dokument PDF, niezależnie od tego, kiedy zostały one utworzone. Umożliwia to tworzenie zachwycających, artystycznych publikacji w formacie PDF na podstawie treści internetowych, w pełni wykorzystujących nowoczesne możliwości HTML5, CSS3 i JavaScript.
Tworzenie i edycja plików PDF
Za pomocą języka programowania można generować nowe dokumenty PDF zawierające tekst, obrazy, tabele i inne treści. IronPDF może również otwierać i modyfikować istniejące dokumenty PDF w celu dodatkowego dostosowania. Wszelkie treści zawarte w dokumencie PDF mogą być dowolnie dodawane, zmieniane lub usuwane.
Złożony projekt i stylizacja
Osiąga się to dzięki stylizacji treści PDF za pomocą CSS, który pozwala obsługiwać skomplikowane układy z różnymi czcionkami, kolorami i innymi elementami projektu. Ponadto obsługa treści dynamicznych w plikach PDF jest zapewniona w miejsce JavaScript, co powinno ułatwić renderowanie treści HTML.
Zainstaluj IronPDF
IronPDF można zainstalować za pomocą pip. Polecenie instalacyjne wygląda następująco:
pip install ironpdfpip install ironpdfPołącz httpx z IronPDF for Python
Użyj HTTPX do pobrania danych z API lub strony internetowej. Poniższy przykład pokazuje, jak pobrać dane z fikcyjnego API w formacie JSON.
import httpx
from ironpdf import ChromePdfRenderer
# Set your IronPDF license key
License.LicenseKey = ""
def fetch_data_with_config(url):
# Create an HTTPX client with added configurations
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Create a PDF document renderer
iron_pdf = ChromePdfRenderer()
# Create HTML content from fetched data
html_content = f"""
<html>
<head><title>Data Report</title></head>
<body>
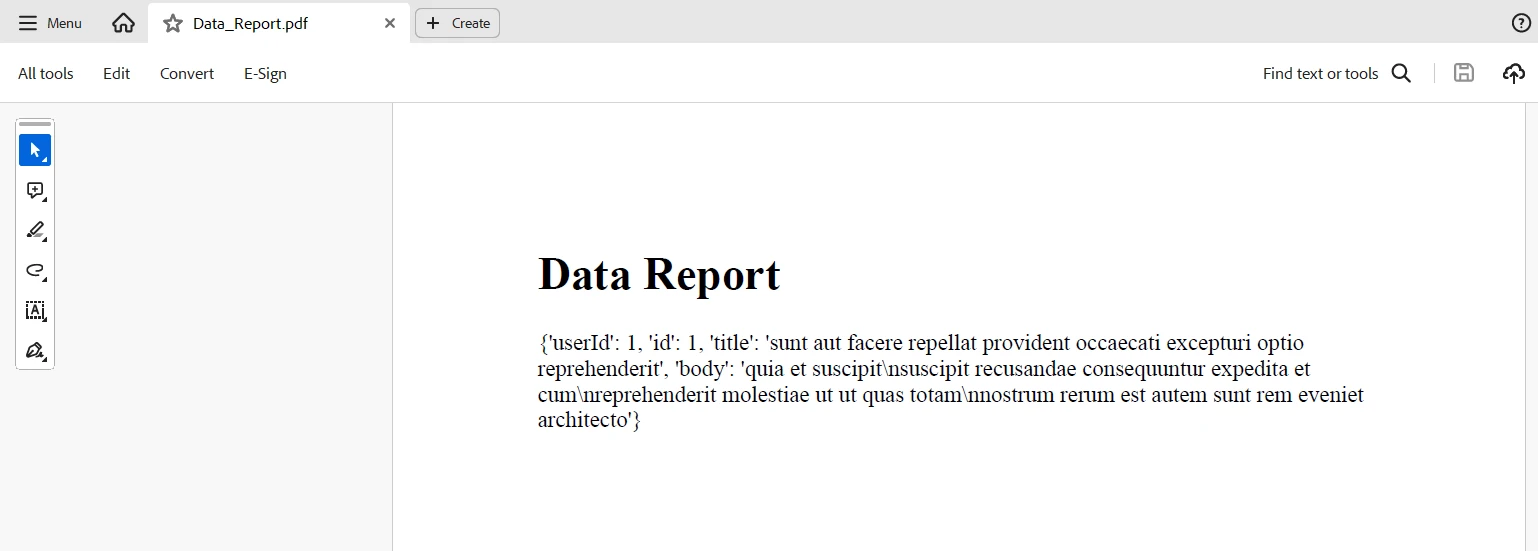
<h1>Data Report</h1>
<p>{response.json()}</p>
</body>
</html>"""
# Render the HTML content as a PDF
pdf = iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
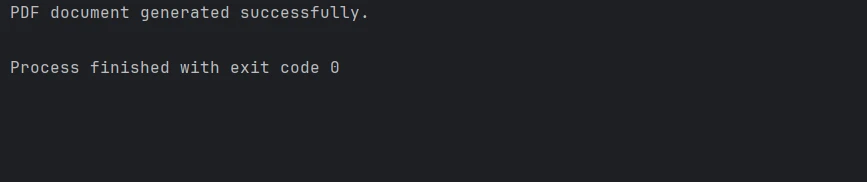
pdf.SaveAs("Data_Report.pdf")
print("PDF document generated successfully.")import httpx
from ironpdf import ChromePdfRenderer
# Set your IronPDF license key
License.LicenseKey = ""
def fetch_data_with_config(url):
# Create an HTTPX client with added configurations
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Create a PDF document renderer
iron_pdf = ChromePdfRenderer()
# Create HTML content from fetched data
html_content = f"""
<html>
<head><title>Data Report</title></head>
<body>
<h1>Data Report</h1>
<p>{response.json()}</p>
</body>
</html>"""
# Render the HTML content as a PDF
pdf = iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("Data_Report.pdf")
print("PDF document generated successfully.")- Jest to zaprojektowane do synchronicznego pobierania danych z interfejsów API lub stron internetowych przy użyciu HTTPX. Jest to biblioteka praktyczna, ponieważ jest przygotowana zarówno do operacji synchronicznych, jak i asynchronicznych, przetwarzając jednocześnie różne żądania HTTP. Przykładem może być wywołanie fikcyjnego punktu końcowego API zwracającego dane JSON.
- IronPDF jest wykorzystywany za pośrednictwem języka Python; silnik .NET, który ma generować raporty PDF z wykorzystaniem wyżej wymienionych danych. IronPDF może generować pliki PDF z treści HTML i konwertować te dane na dokumenty ustrukturyzowane.
- Integracja z IronPDF: Python umożliwia interakcję z IronPDF. Wynikiem tego będzie utworzenie dokumentu PDF (
pdf) na podstawie dynamicznie generowanej treści HTML (html_content). Dane są pobierane za pośrednictwem HTTPX. Ta treść HTML będzie oparta na danych pobieranych dynamicznie; dzięki czemu można uzyskać spersonalizowane raporty w czasie rzeczywistym.
Wnioski
Ta integracja HTTPX z IronPDF łączy w Twoim Pythonie dwie potężne funkcje: pobieranie danych i generowanie profesjonalnych plików PDF. Oznacza to, że HTTPX będzie idealnym rozwiązaniem do pobierania danych za pośrednictwem interfejsów API lub stron internetowych, ponieważ obsługuje zarówno asynchroniczny, jak i synchroniczny styl obsługi żądań HTTP. Z drugiej strony, IronPDF ułatwia generowanie dopracowanych i profesjonalnych raportów PDF na podstawie pobranych danych poprzez interoperacyjność Python .NET, wzbogacając w ten sposób wizualizację i przekazywanie wniosków dotyczących danych.
Ułatwia to wszystko, od najprostszego pobierania danych po pisanie raportów, zapewniając elastyczność przy pracy z wieloma odrębnymi źródłami danych i formatami. Umożliwia to programistom generowanie szczegółowych plików PDF do prezentacji lub dokumentacji, a nawet archiwizowanie wszystkich wyników analizy danych. Wszystkie te narzędzia i aplikacje w języku Python przekształcają surowe dane w profesjonalnie sformatowane raporty, zapewniając wydajność i ułatwiając podejmowanie decyzji w dowolnej dziedzinie.
Zintegruj produkty IronPDF i IronSoftware, aby zapewnić swoim klientom i ich użytkownikom bogate, zaawansowane rozwiązania programowe. Usprawni to działania i procedury projektowe.
Oprócz wszystkich podstawowych funkcji, IronPDF oferuje kompletną dokumentację, aktywną społeczność i częste aktualizacje. Na podstawie tych informacji firma Iron Software jest niezawodnym partnerem w zakresie nowoczesnych projektów programistycznych. Programiści mogą wypróbować IronPDF w ramach bezpłatnej wersji próbnej, aby zapoznać się ze wszystkimi jego funkcjami. Następnie licencja zaczyna się od $799 i wyżej.
















