
HTTPX Python (Como funciona: um guia para desenvolvedores)
HTTPX é um cliente HTTP moderno e completo para Python que oferece APIs síncronas e assíncronas. Esta biblioteca proporciona alta eficiência no processamento de requisições HTTP . Diversas funcionalidades desta biblioteca ampliam as funcionalidades de bibliotecas tradicionais como Requests; Portanto, é mais poderoso porque suporta HTTP/2, agrupamento de conexões e gerenciamento de cookies.
Integrado ao IronPDF, uma biblioteca .NET abrangente para criação e edição de todos os tipos de documentos PDF, o HTTPX pode buscar dados de APIs da web ou até mesmo de sites e transformar esses dados em relatórios PDF longos e bem formatados. É possível produzir documentos profissionais e com ótima aparência graças à capacidade do IronPDF de gerar PDFs a partir de HTML, imagens e texto simples, além de oferecer suporte a recursos avançados, como a adição de cabeçalhos, rodapés e marcas d'água. A integração está completa: da recuperação de dados à geração de relatórios, ela oferece uma maneira eficiente de comunicar informações de forma refinada.
O que é Httpx em Python?
HTTPX é um cliente HTTP moderno e de última geração para Python que aproveita algumas funcionalidades interessantes da popular biblioteca Requests e as combina com suporte a APIs síncronas e assíncronas. Busca resolver tarefas HTTP complexas com diferentes funcionalidades avançadas, como suporte a HTTP/2, agrupamento de conexões e até mesmo gerenciamento automático de cookies. O HTTPX permite que os desenvolvedores enviem várias solicitações HTTP diferentes simultaneamente, acelerando o desempenho de um aplicativo nos casos em que as interações baseadas na web são as principais funcionalidades esperadas.
Oferece excelente interoperabilidade com a biblioteca Requests, proporcionando um caminho de atualização fácil para desenvolvedores que desejam atualizar seu cliente HTTP e acessar recursos mais complexos. HTTPX é uma ferramenta flexível para o desenvolvimento moderno em Python; É bastante adequado para tarefas que vão desde consultas HTTP simples até interações web mais complexas e que exigem alto desempenho. O HTTPX pode realizar requisições síncronas e assíncronas com suporte a proxy SOCKS.
Características do Httpx em Python
O HTTPX em Python oferece os recursos mais valiosos que ampliam e aprimoram o tratamento de requisições HTTP. Aqui estão algumas de suas principais características:
APIs Síncronas e Assíncronas:
Ele suporta o processamento de solicitações síncronas e assíncronas. Um desenvolvedor pode aplicar qualquer uma das opções disponíveis em um aplicativo, com base em suas necessidades.
Suporte a HTTP/2:
Este framework possui suporte nativo ao protocolo HTTP/2, permitindo uma comunicação mais rápida e eficiente com servidores que o suportam.
Agrupamento de Conexões:
Conexão HTTP inteligente: Reutilize conexões já estabelecidas e sessões de pool de conexões para reduzir a latência e aumentar a velocidade em várias requisições.
Decodificação Automática de Conteúdo:
Ele automatiza a decodificação de uma resposta compactada, geralmente codificada em gzip, tornando-a muito mais fácil de processar e reduzindo o consumo de largura de banda.
Tempos de espera e tentativas:
Defina configurações de tempo limite para solicitações garantidamente não bloqueantes que ultrapassem o tempo limite da solicitação — mecanismos adicionais de repetição para lidar com falhas transitórias.
Suporte a WebSockets:
Ele suporta conexões WebSocket, permitindo a comunicação bidirecional entre o cliente e o servidor através de uma única conexão de longa duração.
Suporte a Proxy:
Possui suporte integrado para proxies HTTP. Isso permitirá o envio de solicitações por meio de servidores intermediários para fins de privacidade ou gerenciamento de rede.
Manipulação de Cookies:
A biblioteca irá gerenciar os cookies, mantendo o controle do estado da sessão entre as requisições.
Certificado de Cliente:
Os certificados do lado do cliente são suportados para proteger as comunicações com servidores que usam autenticação TLS mútua.
Middleware and Hooks:
Permite a personalização do tratamento de requisições e respostas com middleware e hooks. Isso proporciona excelente extensibilidade para que os desenvolvedores ampliem a funcionalidade do HTTPX de acordo com suas necessidades. Compatibilidade com Requests: Foi projetado para usar a API do Requests, facilitando muito a migração de desenvolvedores do Requests para o projeto HTTPX e permitindo que eles obtenham muitos novos recursos e melhorias excelentes.
Criar e configurar o Httpx em Python.
Primeiro, você deve instalar a biblioteca e configurar um ambiente para configurar o HTTPX em Python. O projeto HTTPX depende do núcleo HTTP e da detecção automática da biblioteca assíncrona como dependências, mas eles devem ser instalados diretamente ao instalar o projeto HTTPX. Existe também uma variação do HTTPX como um cliente de linha de comando que oferece suporte avançado a terminais; No entanto, neste artigo, focaremos estritamente no HTTPX em Python. O guia abaixo apresenta um exemplo de uma solicitação HTTP GET simples. Para uma referência de API mais completa, visite a documentação do HTTPX aqui .
Install HTTPX
Primeiro, certifique-se de ter o HTTPX instalado. Você pode usar o cliente de linha de comando para instalar:
pip install httpxpip install httpxImportar HTTPX e Fazer uma Solicitação Básica
Após a instalação, você pode importar o HTTPX e enviar uma solicitação HTTP GET simples da seguinte forma:
import httpx
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
# Create a client instance to manage HTTP requests
response = httpx.get(url)
# Print response HTTP status codes and content
print(f"Status Code: {response.status_code}")
# Print Unicode Response Bodies
print(f"Response Content: {response.text}")import httpx
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
# Create a client instance to manage HTTP requests
response = httpx.get(url)
# Print response HTTP status codes and content
print(f"Status Code: {response.status_code}")
# Print Unicode Response Bodies
print(f"Response Content: {response.text}")- Uma função
fetch_data, que utiliza um gerenciador de contexto assíncrono interno para abrir um cliente HTTP, faz uma requisição GET para uma URL específica. - Armazena o objeto de resposta HTTP retornado por
httpx.get(url).
Configurando Recursos Avançados no HTTPX
Os recursos avançados do HTTPX suportam uma ampla gama de outras configurações, como o gerenciamento de proxies, cabeçalhos e tempos limite. Veja como configurar o HTTPX com mais opções:
import httpx
def fetch_data_with_config(url):
# Create a client with a timeout and custom headers
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Print response status code and content
print(f"Status Code: {response.status_code}")
print(f"Response Content: {response.json()}")import httpx
def fetch_data_with_config(url):
# Create a client with a timeout and custom headers
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Print response status code and content
print(f"Status Code: {response.status_code}")
print(f"Response Content: {response.json()}")- Tempo limite: Define o tempo limite da solicitação HTTP para 30 segundos. Isso serve para evitar que a solicitação fique bloqueada indefinidamente.
- Adiciona um cabeçalho personalizado
User-Agentà solicitação{ "User-Agent": "MyApp/1.0" }, identificando a aplicação cliente. - response.json() - Esta função analisa o conteúdo da resposta como JSON, assumindo que a resposta inclua dados JSON.

Começando
Como usar HTTPX com Python e IronPDF para gerar PDFs. Primeiro, você precisa configurar o HTTPX para buscar dados de alguma fonte e, em seguida, o IronPDF criará um relatório em PDF a partir dos dados obtidos. Veja aqui como fazer isso em detalhes:
O que é o IronPDF ?
A poderosa e robusta biblioteca Python IronPDF permite a produção, edição e leitura de PDFs. Permite que os programadores realizem diversas operações programáticas em PDFs, como editar PDFs já existentes e converter arquivos HTML em arquivos PDF. O IronPDF torna a geração de relatórios de alta qualidade em formato PDF mais simples e flexível. Assim, isso torna o sistema prático para aplicações que criam e processam PDFs dinamicamente.
Conversão de HTML para PDF
O IronPDF permite a conversão de quaisquer dados HTML em um documento PDF, independentemente de sua idade. Isso permite a criação de publicações em PDF impressionantes e artísticas a partir de conteúdo da web, explorando totalmente os recursos modernos de HTML5, CSS3 e JavaScript.
Criar e editar PDFs
É possível gerar novos documentos PDF contendo texto, imagens, tabelas e outros conteúdos por meio de uma linguagem de programação. O IronPDF também pode abrir e modificar documentos PDF preexistentes para personalização adicional. Qualquer conteúdo incluído em um documento PDF pode ser adicionado, alterado ou removido à vontade.
Design e estilo complexos
Isso é conseguido através da estilização do conteúdo do PDF via CSS, que consegue lidar com layouts complexos com diversas fontes, cores e outros elementos de design. Além disso, o processamento de conteúdo dinâmico em PDFs é garantido no lugar do JavaScript, o que facilita a renderização de conteúdo HTML.
Instale o IronPDF
O IronPDF pode ser instalado com o pip. O comando para instalação é o seguinte:
pip install ironpdf
Combine o httpx com o IronPDF for Python
Utilize HTTPX para obter dados de uma API ou site. O exemplo a seguir mostra como recuperar dados de uma API fictícia em formato JSON.
import httpx
from ironpdf import ChromePdfRenderer
# Set your IronPDF license key
License.LicenseKey = ""
def fetch_data_with_config(url):
# Create an HTTPX client with added configurations
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Create a PDF document renderer
iron_pdf = ChromePdfRenderer()
# Create HTML content from fetched data
html_content = f"""
<html>
<head><title>Data Report</title></head>
<body>
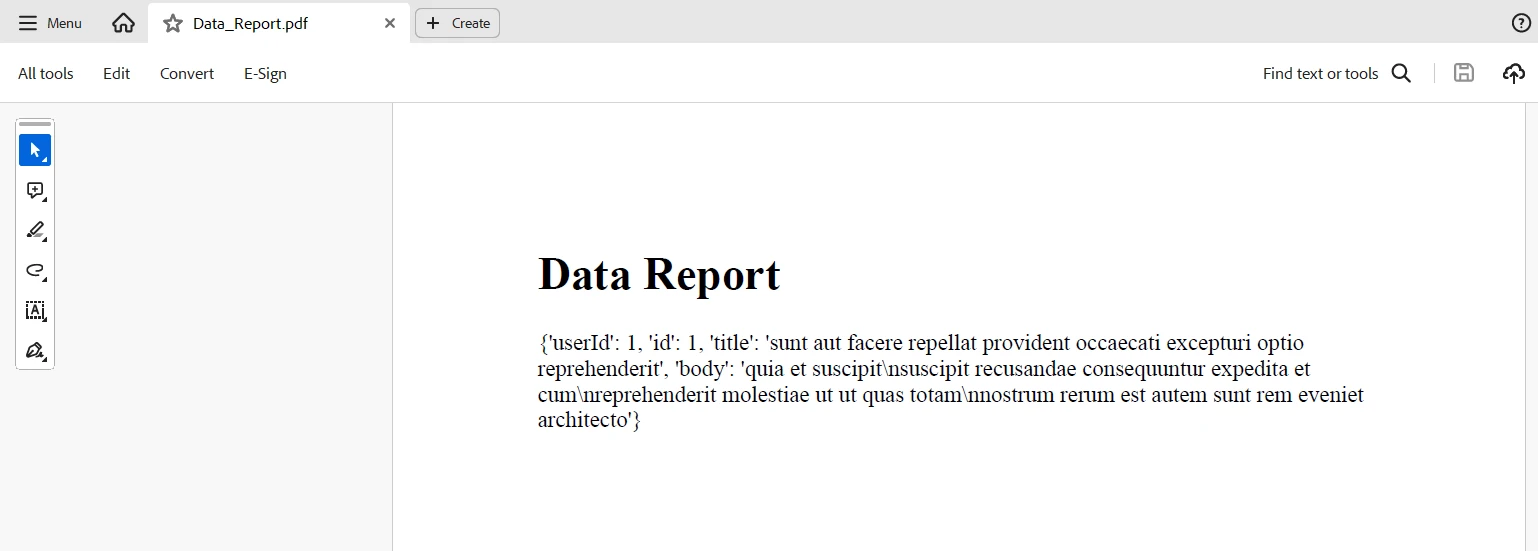
<h1>Data Report</h1>
<p>{response.json()}</p>
</body>
</html>"""
# Render the HTML content as a PDF
pdf = iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("Data_Report.pdf")
print("PDF document generated successfully.")import httpx
from ironpdf import ChromePdfRenderer
# Set your IronPDF license key
License.LicenseKey = ""
def fetch_data_with_config(url):
# Create an HTTPX client with added configurations
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Create a PDF document renderer
iron_pdf = ChromePdfRenderer()
# Create HTML content from fetched data
html_content = f"""
<html>
<head><title>Data Report</title></head>
<body>
<h1>Data Report</h1>
<p>{response.json()}</p>
</body>
</html>"""
# Render the HTML content as a PDF
pdf = iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("Data_Report.pdf")
print("PDF document generated successfully.")- Este recurso foi projetado para buscar dados de APIs da web ou sites de forma síncrona usando HTTPX. É uma biblioteca prática porque está preparada tanto para operações síncronas quanto assíncronas, processando diferentes requisições HTTP simultaneamente. Um exemplo seria acessar um endpoint de API simulado que retorna dados JSON.
- O IronPDF é utilizado através do Python; Um mecanismo .NET foi contratado para gerar relatórios em PDF com os dados obtidos mencionados acima. O IronPDF pode gerar PDFs a partir de conteúdo HTML e converter esses dados em documentos estruturados.
- Integração com o IronPDF : O Python permite que você interaja com o IronPDF. Isso resultará no desenvolvimento de um documento PDF (
pdf) baseado em conteúdo HTML gerado dinamicamente (html_content). Os dados são obtidos através do HTTPX. Este conteúdo HTML será baseado em dados obtidos dinamicamente; Dessa forma, é possível obter relatórios personalizados e em tempo real.
Conclusão
Essa integração HTTPX com o IronPDF combina duas funcionalidades poderosas em seu código Python: recuperação de dados e geração de PDFs de nível profissional. Isso significa que o HTTPX é perfeito para buscar dados em APIs ou sites da web, já que oferece suporte a estilos assíncronos e síncronos para lidar com solicitações HTTP. Por outro lado, o IronPDF facilita a geração de relatórios em PDF refinados e de nível profissional a partir de dados obtidos por meio da interoperabilidade com Python .NET , aprimorando assim a visualização e a transmissão de informações sobre os dados.
Isso facilita tudo, desde a recuperação de dados mais simples até a elaboração de relatórios, oferecendo flexibilidade ao lidar com diversas fontes e formatos de dados distintos. Isso permite ao desenvolvedor gerar PDFs detalhados para apresentações ou documentação, ou até mesmo arquivar todas as descobertas da análise de dados. Todas essas ferramentas e aplicações em Python transformarão dados brutos em relatórios formatados profissionalmente, garantindo produtividade e tomada de decisões em qualquer área escolhida.
Integre os produtos IronPDF e Iron Software para fornecer soluções de software ricas e de alta qualidade aos seus clientes e seus usuários. Isso irá agilizar as operações e os procedimentos do projeto.
Além de todos os recursos básicos, o IronPDF possui documentação completa, uma comunidade ativa e atualizações frequentes. Com base nessas informações, a Iron Software é uma parceira confiável para projetos modernos de desenvolvimento de software. Os desenvolvedores podem experimentar o IronPDF gratuitamente para analisar todos os seus recursos. Depois disso, a licença começa em $999 e acima.
















