
Grakn Python (Como funciona: um guia para desenvolvedores)
No mundo da programação atual, os bancos de dados estão evoluindo para acompanhar as demandas de novas aplicações. Embora os bancos de dados relacionais tradicionais ainda sejam utilizados, agora contamos com avanços como o Mapeamento Objeto-Relacional (ORM), que permite aos desenvolvedores interagir com os bancos de dados usando abstrações de programação de nível superior, em vez de depender exclusivamente do SQL. Essa abordagem simplifica o gerenciamento de dados e promove uma organização de código mais limpa. Além disso, os bancos de dados NoSQL surgiram como ferramentas úteis para lidar com dados não estruturados, particularmente em aplicações de big data e análises em tempo real.
Os bancos de dados nativos da nuvem também estão causando um impacto significativo, oferecendo serviços escaláveis, confiáveis e gerenciados que reduzem o ônus da manutenção da infraestrutura subjacente. Além disso, os bancos de dados NewSQL e de grafos combinam os pontos fortes do SQL e do NoSQL, oferecendo a confiabilidade dos bancos de dados relacionais com a flexibilidade do NoSQL. Essa combinação os torna adequados para muitas aplicações modernas. Ao integrar esses diversos tipos de banco de dados com paradigmas de programação inovadores, podemos criar soluções escaláveis e adaptáveis que estejam alinhadas com as demandas atuais centradas em dados. O Grakn, agora conhecido como TypeDB, exemplifica essa tendência ao oferecer suporte ao gerenciamento e à consulta de grafos de conhecimento. Neste artigo, exploraremos o Grakn (TypeDB) e sua integração com o IronPDF, uma ferramenta crucial para a geração e manipulação programática de PDFs.
O que é Grakn?
Grakn (agora TypeDB ), criado pela Grakn Labs, é um banco de dados de grafos de conhecimento projetado para gerenciar e analisar redes complexas de dados. Ele se destaca na modelagem de relações complexas em conjuntos de dados existentes e oferece poderosos recursos de raciocínio sobre dados armazenados. A linguagem de consulta da Grakn, Graql, permite a manipulação e consulta precisa de dados, possibilitando o desenvolvimento de sistemas inteligentes capazes de extrair informações valiosas de conjuntos de dados complexos. Ao aproveitar os principais recursos do Grakn, as organizações podem gerenciar estruturas de dados com uma representação de conhecimento robusta e inteligente.
Graql, a linguagem de consulta do Grakn, foi especificamente criada para interagir de forma eficaz com o modelo de grafo de conhecimento do Grakn, permitindo transformações de dados detalhadas e precisas. Devido à sua escalabilidade horizontal e capacidade de lidar com grandes conjuntos de dados, o TypeDB é ideal para áreas como finanças, saúde, descoberta de medicamentos e segurança cibernética, onde a compreensão e o gerenciamento de estruturas gráficas complexas são cruciais.
Instalação e configuração do Grakn em Python
Instalando Grakn
Para desenvolvedores Python interessados em usar Grakn (TypeDB), a instalação da biblioteca typedb-driver é essencial. Este cliente oficial facilita a interação com o TypeDB. Utilize o seguinte comando pip para instalar esta biblioteca:
pip install typedb-driverpip install typedb-driverConfigurar o servidor TypeDB
Antes de escrever o código, certifique-se de que seu servidor TypeDB esteja funcionando corretamente. Siga as instruções de instalação e configuração fornecidas no site do TypeDB para o seu sistema operacional. Após a instalação, você pode usar o seguinte comando para iniciar o servidor TypeDB:
./typedb server./typedb serverUsando Grakn em Python
Código Python para interagir com o TypeDB
Esta seção ilustra como estabelecer uma conexão com um servidor TypeDB, configurar um esquema de banco de dados e realizar operações básicas como inserção e recuperação de dados.
Criando um esquema de banco de dados
No bloco de código a seguir, definimos a estrutura do banco de dados criando um tipo chamado person com dois atributos: name e age. Abrimos uma sessão no modo SCHEMA, permitindo modificações estruturais. Eis como o esquema é definido e confirmado:
from typedb.driver import TypeDB, SessionType, TransactionType
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Create a database (if not already created)
database_name = "example_db"
if not client.databases().contains(database_name):
client.databases().create(database_name)
with client.session(database_name, SessionType.SCHEMA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
transaction.query().define("""
define
person sub entity, owns name, owns age;
name sub attribute, value string;
age sub attribute, value long;
""")
transaction.commit()from typedb.driver import TypeDB, SessionType, TransactionType
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Create a database (if not already created)
database_name = "example_db"
if not client.databases().contains(database_name):
client.databases().create(database_name)
with client.session(database_name, SessionType.SCHEMA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
transaction.query().define("""
define
person sub entity, owns name, owns age;
name sub attribute, value string;
age sub attribute, value long;
""")
transaction.commit()Inserindo dados
Após estabelecer o esquema, o script insere os dados no banco de dados. Abrimos uma sessão no modo DATA, adequado para operações de dados, e executamos uma consulta de inserção para adicionar uma nova entidade person com o nome "Alice" e idade 30:
# Insert data into the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
# Create a person entity
transaction.query().insert("""
insert $p isa person, has name "Alice", has age 30;
""")
transaction.commit()# Insert data into the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
# Create a person entity
transaction.query().insert("""
insert $p isa person, has name "Alice", has age 30;
""")
transaction.commit()Consultando dados
Finalmente, recuperamos informações do banco de dados consultando entidades com o nome "Alice". Abrimos uma nova sessão em modo DATA e iniciamos uma transação de leitura usando TransactionType.READ. Os resultados são processados para extrair e exibir o nome e a idade:
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Query entities where the person has the name 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
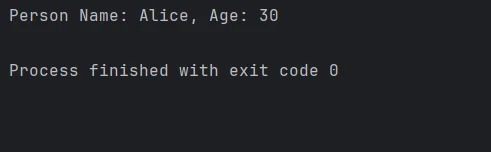
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
print(f"Person Name: {person_name}, Age: {person_age}")# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Query entities where the person has the name 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
print(f"Person Name: {person_name}, Age: {person_age}")Saída
Encerrando a conexão com o cliente
Para liberar adequadamente recursos e evitar interações adicionais com o servidor TypeDB, feche a conexão do cliente usando client.close():
# Close the client connection
client.close()# Close the client connection
client.close()Apresentando o IronPDF
IronPDF for Python é uma biblioteca poderosa para criar e manipular arquivos PDF programaticamente. Oferece funcionalidades abrangentes para criar PDFs a partir de HTML, mesclar arquivos PDF e anotar documentos PDF existentes. O IronPDF também permite a conversão de conteúdo HTML ou da web em PDFs de alta qualidade, tornando-o uma escolha ideal para gerar relatórios, faturas e outros documentos com layout fixo.
A biblioteca oferece recursos avançados, como extração de conteúdo, criptografia de documentos e personalização do layout da página. Ao integrar o IronPDF em aplicações Python, os desenvolvedores podem automatizar fluxos de trabalho de geração de documentos e aprimorar os recursos gerais de manipulação de PDFs.
Instalando a biblioteca IronPDF
Para habilitar a funcionalidade IronPDF em Python, instale a biblioteca usando o pip:
pip install ironpdf
Integrando o Grakn TypeDB com o IronPDF
Ao combinar TypeDB e IronPDF em um ambiente Python, os desenvolvedores podem gerar e gerenciar com eficiência documentação em PDF com base em dados estruturados de forma complexa em um banco de dados Grakn (TypeDB). Aqui está um exemplo de integração:
from typedb.driver import TypeDB, SessionType, TransactionType
from ironpdf import *
import warnings
# Suppress potential warnings
warnings.filterwarnings('ignore')
# Replace with your own license key
License.LicenseKey = "YOUR LICENSE KEY GOES HERE"
# Initialize data list
data = []
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Fetch details of persons named 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
data.append({"name": person_name, "age": person_age})
# Close the client connection
client.close()
# Create a PDF from HTML content
html_to_pdf = ChromePdfRenderer()
content = "<h1>Person Report</h1>"
for item in data:
content += f"<p>Name: {item['name']}, Age: {item['age']}</p>"
# Render the HTML content as a PDF
pdf_document = html_to_pdf.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf_document.SaveAs("output.pdf")from typedb.driver import TypeDB, SessionType, TransactionType
from ironpdf import *
import warnings
# Suppress potential warnings
warnings.filterwarnings('ignore')
# Replace with your own license key
License.LicenseKey = "YOUR LICENSE KEY GOES HERE"
# Initialize data list
data = []
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Fetch details of persons named 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
data.append({"name": person_name, "age": person_age})
# Close the client connection
client.close()
# Create a PDF from HTML content
html_to_pdf = ChromePdfRenderer()
content = "<h1>Person Report</h1>"
for item in data:
content += f"<p>Name: {item['name']}, Age: {item['age']}</p>"
# Render the HTML content as a PDF
pdf_document = html_to_pdf.RenderHtmlAsPdf(content)
# Save the PDF to a file
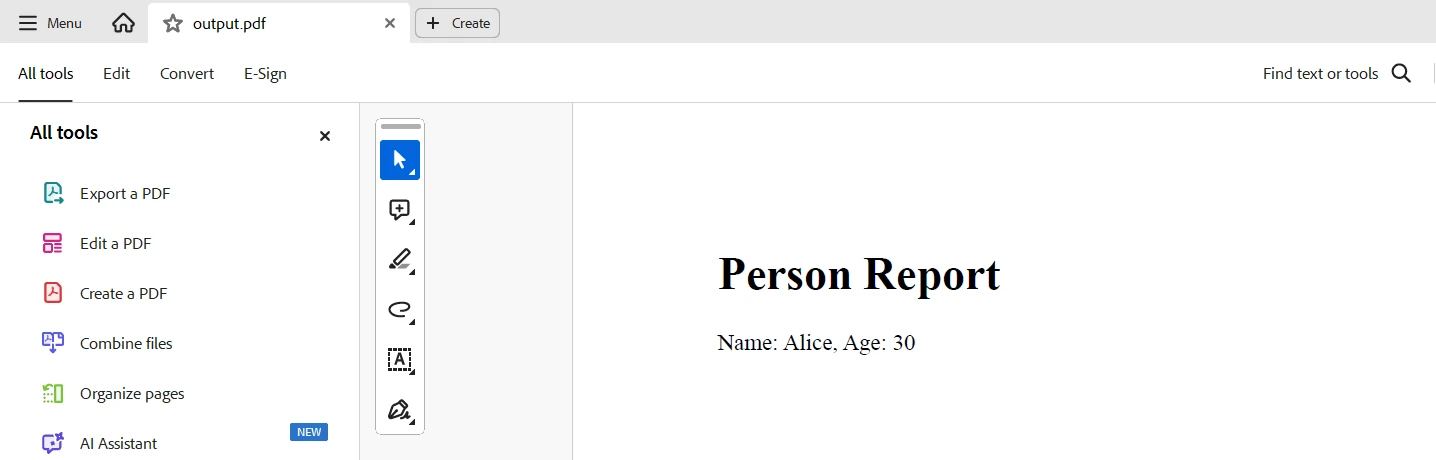
pdf_document.SaveAs("output.pdf")Este código demonstra o uso do TypeDB e do IronPDF em Python para extrair dados de um banco de dados TypeDB e gerar um relatório em PDF. Ele se conecta a um servidor TypeDB local, busca entidades chamadas "Alice" e recupera seus nomes e idades. Os resultados são então usados para construir conteúdo HTML, que é convertido em um documento PDF usando o ChromePdfRenderer do IronPDF, e salvo como "output.pdf".
Saída
Licenciamento
É necessária uma chave de licença para remover as marcas d'água dos PDFs gerados. Você pode se inscrever para um teste gratuito neste link . Observe que não é necessário cartão de crédito para o cadastro; Para a versão de avaliação gratuita, basta um endereço de e-mail.
Conclusão
O Grakn (agora TypeDB) integrado ao IronPDF oferece uma solução robusta para gerenciar e analisar grandes volumes de dados de documentos PDF. Com os recursos do IronPDF para extração e manipulação de dados, e a proficiência do Grakn em modelagem de relacionamentos e raciocínio complexos, você pode transformar dados de documentos não estruturados em informações estruturadas e consultáveis.
Essa integração simplifica a extração de informações valiosas de PDFs, aprimorando suas capacidades de consulta e análise com maior precisão. Ao combinar o gerenciamento de dados de alto nível do Grakn com os recursos de processamento de PDF do IronPDF, você pode desenvolver maneiras mais eficientes de lidar com informações para uma melhor tomada de decisão e uma compreensão mais profunda de conjuntos de dados complexos. Iron Software também oferece uma variedade de bibliotecas para facilitar o desenvolvimento de aplicações em diversos sistemas operacionais e plataformas, incluindo Windows, Android, macOS, Linux, e mais.
















