
Jak wyodrębnić tabelę z pliku PDF w języku Python
W tym artykule pokażemy, jak używać IronPDF, potężnej biblioteki do przetwarzania plików PDF, aby bez wysiłku wyodrębniać dane ze złożonych tabel w dowolnym pliku PDF.
IronPDF
Python zapewnia programistom znacznie większą elastyczność w porównaniu z innymi językami i pozwala im łatwo i efektywnie projektować graficzne interfejsy użytkownika. Dlatego włączenie biblioteki IronPDF do języka Python jest prostym procesem. Aby szybko i bezpiecznie stworzyć w pełni funkcjonalny interfejs graficzny, można wykorzystać szereg preinstalowanych narzędzi, w tym PyQt, wxWidgets, Kivy oraz różne inne pakiety i biblioteki.
IronPDF upraszcza projektowanie i tworzenie stron internetowych w języku Python. Wynika to przede wszystkim z dużej liczby dostępnych frameworków do tworzenia stron internetowych w języku Python, takich jak Django, Flask i Pyramid. Niektóre znane strony internetowe i serwisy online, które wykorzystują te frameworki, to między innymi Reddit, Mozilla i Spotify.
Jak wyodrębnić tabelę z pliku PDF w języku Python
- Pobierz moduł Python do wyodrębniania tabel z plików PDF
- Użyj metody
FromFile,aby zaimportować plik PDF - Wyodrębnij tekst z tabel za pomocą metody
ExtractAllText - Przejrzyj wyodrębniony tekst, aby podzielić wiersze
- Wyświetl wyodrębniony tekst w konsoli lub w pliku tekstowym
Funkcje IronPDF
Poniżej przedstawiono niektóre funkcje IronPDF:
- Pliki PDF można tworzyć z różnych źródeł, takich jak HTML, HTML5, ASP, PHP i inne. Dodatkowo pliki graficzne można konwertować do formatu PDF wraz z plikami HTML.
- IronPDF umożliwia tworzenie interaktywnych dokumentów PDF. Oferuje takie funkcje, jak dzielenie i łączenie plików PDF, wyodrębnianie tekstu i obrazów z plików PDF, rasteryzacja stron PDF do obrazów, konwersja PDF do HTML, drukowanie plików PDF, wypełnianie i przesyłanie interaktywnych formularzy oraz dzielenie i scalanie plików PDF.
- Dzięki IronPDF możliwe jest wygenerowanie dokumentu na podstawie adresu URL. Obsługuje również agenty użytkownika, którzy logują się za pomocą formularzy logowania HTML, serwerów proxy, plików cookie, nagłówków HTTP, specjalnych poświadczeń logowania do sieci, zmiennych formularzy i agentów użytkownika.
- Program IronPDF umożliwia przeglądanie i dodawanie adnotacji do plików PDF.
- IronPDF umożliwia wyodrębnianie obrazów z dokumentów.
- IronPDF umożliwia użytkownikom dodawanie do dokumentów nagłówków, stopek, tekstu, zdjęć, zakładek, znaków wodnych i innych elementów.
- Korzystając z IronPDF, można dzielić i łączyć strony w nowym lub istniejącym dokumencie.
- Konwersja dokumentów na obiekty PDF jest możliwa bez konieczności korzystania z przeglądarki Acrobat.
- IronPDF umożliwia tworzenie dokumentów PDF na podstawie plików CSS.
- Dokumenty można tworzyć przy użyciu plików CSS zawierających definicje typów mediów za pomocą IronPDF.
Konfiguracja środowiska Python
Konfiguracja Python
Upewnij się, że na Twoim komputerze jest zainstalowany Python. Aby pobrać i zainstalować najnowszą wersję języka Python dla swojego systemu operacyjnego, przejdź na oficjalną stronę internetową języka Python. Po zainstalowaniu Pythona należy wyodrębnić wymagania projektu, tworząc środowisko wirtualne. Za pomocą modułu venv możesz tworzyć wirtualne środowiska i zarządzać nimi, aby zapewnić swojemu projektowi konwersji schludną i uporządkowaną przestrzeń roboczą.
Nowy projekt w PyCharm
W tym samouczku zalecane jest użycie PyCharm, środowiska IDE do programowania w języku Python.
Po uruchomieniu środowiska PyCharm wybierz z menu opcję "New Project", jak pokazano na poniższym rysunku.
 Środowisko IDE PyCharm
Środowisko IDE PyCharm
Jak widać na poniższym obrazku, po wybraniu opcji "New Project" pojawi się nowe okno, w którym można zdefiniować lokalizację projektu i środowisko Python.
 Utwórz nowy projekt w PyCharm
Utwórz nowy projekt w PyCharm
Po wybraniu lokalizacji i środowiska dla projektu kliknij przycisk Utwórz, aby go zainicjować. Pliki Python można otworzyć w nowo uruchomionym oknie, aby wprowadzić kod. W niniejszym przewodniku wykorzystano Python 3.9.
 główny plik w języku Python
główny plik w języku Python
Wymagania dotyczące biblioteki IronPDF
IronPDF for Python opiera się na technologii .NET 6.0 jako swojej podstawowej technologii. Dlatego, aby korzystać z IronPDF for Python, na komputerze musi być zainstalowane środowisko uruchomieniowe .NET 6.0. Użytkownicy systemów Linux i Mac mogą być zmuszeni do zainstalowania platformy .NET, zanim będą mogli korzystać z tego modułu języka Python. Pobierz niezbędne środowisko uruchomieniowe ze strony Microsoft.
Konfiguracja biblioteki IronPDF
Aby tworzyć, edytować i otwierać pliki z rozszerzeniem ".PDF", należy zainstalować pakiet ironpdf. Aby zainstalować pakiet w PyCharm, otwórz okno terminala i wpisz następujące polecenie:
pip install ironpdf
Poniższy zrzut ekranu ilustruje proces instalacji pakietu ironpdf.
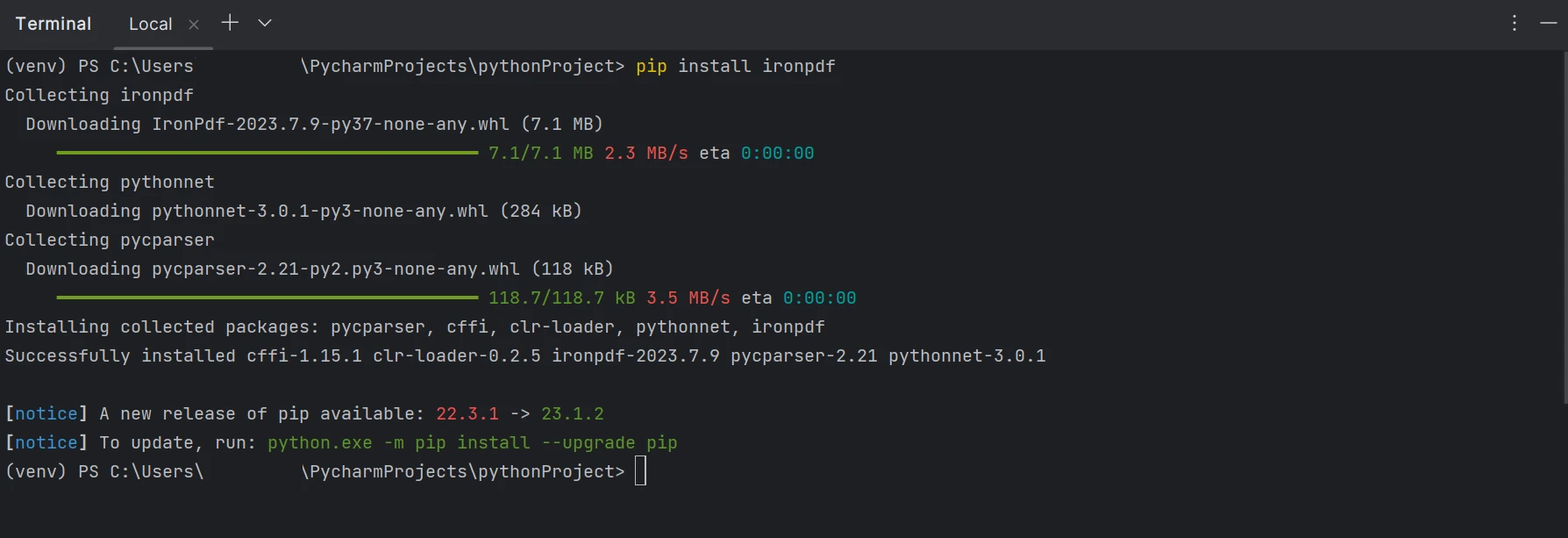 Zainstaluj pakiet IronPDF
Zainstaluj pakiet IronPDF
Pobieranie danych z tabeli z pliku PDF
Możemy bez trudu wyodrębniać dane z plików PDF za pomocą biblioteki IronPDF for Python. IronPDF ułatwia analizę danych tekstowych i wyodrębnianie tabel z plików PDF. Poniżej znajduje się przykładowy kod pokazujący, jak wyodrębnić dane z tabel w pliku PDF, wykorzystując podany obrazek jako odniesienie.
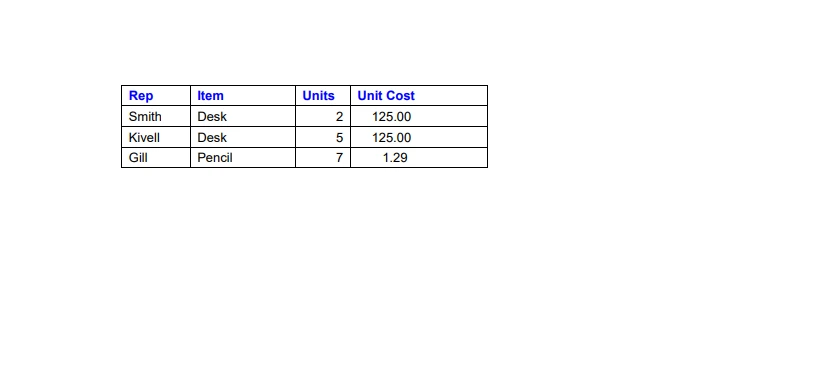 Przykładowe dane z pliku PDF
Przykładowe dane z pliku PDF
from ironpdf import PdfDocument
# Load the PDF document
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Split the extracted text into rows and print each row
for row in all_text.split("\n"):
print(row)from ironpdf import PdfDocument
# Load the PDF document
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Split the extracted text into rows and print each row
for row in all_text.split("\n"):
print(row)Podany kod pokazuje, jak można użyć IronPDF do wyodrębniania tabel z plików PDF za pomocą zaledwie kilku wierszy kodu w języku Python. Na początku importujemy bibliotekę IronPDF, aby uzyskać dostęp do jej funkcjonalności i wszystkich funkcji IronPDF. Następnie, przy pomocy klasy PdfDocument, istniejące pliki PDF mogą być przetwarzane w celu wykonania na nich różnych operacji.
Podczas korzystania z funkcji FromFile dostępny jest argument służący do wczytania pliku PDF. Następnie funkcja ExtractAllText wyodrębnia wszystkie dane tabel z wszystkich stron w plikach PDF. Następnie funkcja split służy do podzielenia wyodrębnionych danych tabeli na wiele wierszy i wyświetlenia ich na ekranie konsoli.
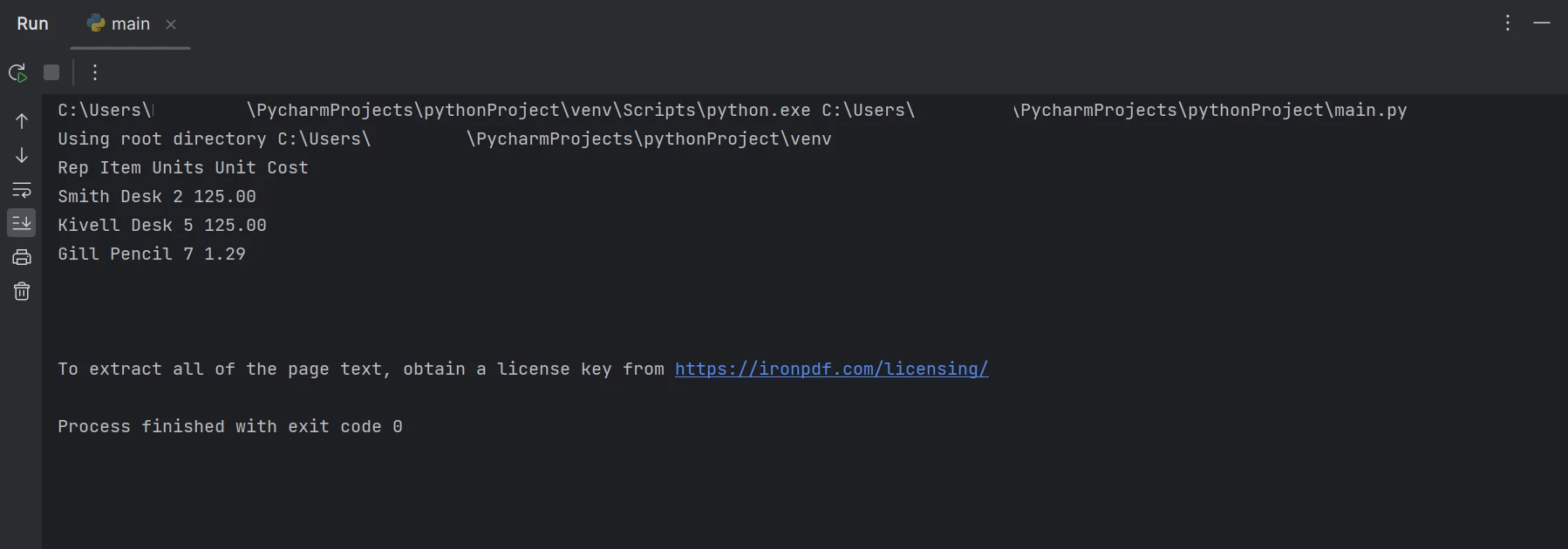 Wyodrębnione dane
Wyodrębnione dane
W powyższym wyniku dane są wyświetlane wiersz po wierszu, pokazując, w jaki sposób można wyodrębnić dane z tabeli. Dowiedz się więcej o IronPDF, zapoznając się z dokumentacją produktu.
Wnioski
Biblioteka IronPDF zapewnia solidne zabezpieczenia, które minimalizują potencjalne ryzyko i gwarantują bezpieczeństwo danych. Jest kompatybilny ze wszystkimi popularnymi przeglądarkami i nie ogranicza się do żadnej konkretnej. Dzięki IronPDF programiści mogą efektywnie tworzyć i odczytywać pliki PDF za pomocą zaledwie kilku wierszy kodu. Aby zaspokoić różnorodne potrzeby programistów, biblioteka IronPDF oferuje różne opcje licencyjne, w tym bezpłatną licencję dla programistów oraz dodatkowe licencje programistyczne dostępne w sprzedaży.
Pakiet Lite, w cenie $799, obejmuje Licencję wieczystą, 30-dniową gwarancję zwrotu pieniędzy, roczną konserwację oprogramowania oraz możliwość aktualizacji. Po dokonaniu pierwszego zakupu nie są pobierane żadne dodatkowe opłaty, a licencje te mogą być wykorzystywane w środowiskach produkcyjnych, testowych i programistycznych. IronPDF zapewnia również bezpłatne licencje z pewnymi ograniczeniami czasowymi i dotyczącymi redystrybucji. Użytkownicy mogą przetestować produkt w rzeczywistym srodowisku dzięki bezpłatnemu okresowi próbnym, który nie zawiera znaku wodnego. Aby uzyskać szczegółowe informacje dotyczące kosztów i licencji wersji próbnej IronPDF, kliknij poniższą stronę poświęconą licencjom.
Często Zadawane Pytania
Jak wyodrębnić tabele z pliku PDF w języku Python?
Aby wyodrębnić tabele z pliku PDF przy użyciu IronPDF w języku Python, można skorzystać z metody PdfDocument.FromFile() w celu załadowania pliku PDF, a następnie użyć metody ExtractAllText() do wyodrębnienia tekstu. Tekst można następnie przetworzyć i podzielić na wiersze w celu pobrania danych z tabeli.
Jakie kroki należy wykonać, aby skonfigurować środowisko Python do korzystania z IronPDF?
Aby skonfigurować środowisko Python do korzystania z IronPDF, upewnij się, że masz zainstalowany Python, utwórz środowisko wirtualne i zainstaluj środowisko uruchomieniowe .NET 6.0. Następnie możesz zainstalować IronPDF za pomocą polecenia pip install ironpdf.
Jakie funkcje manipulacji plikami PDF oferuje IronPDF w języku Python?
IronPDF oferuje szeroki zakres funkcji do pracy z plikami PDF w języku Python, w tym możliwość tworzenia plików PDF z HTML, obrazów i innych źródeł, wyodrębniania tekstu i obrazów oraz tworzenia interaktywnych plików PDF z adnotacjami, nagłówkami, stopkami i znakami wodnymi.
Czy mogę przekonwertować HTML na PDF za pomocą IronPDF w Pythonie?
Tak, IronPDF umożliwia konwersję HTML do PDF w języku Python. Za pomocą metod IronPDF można renderować ciągi znaków lub pliki HTML jako pliki PDF, co ułatwia tworzenie dokumentów PDF na podstawie treści internetowych.
Jakie opcje licencyjne są dostępne dla IronPDF w języku Python?
IronPDF oferuje kilka opcji licencyjnych, w tym bezpłatną licencję deweloperską do testowania, pakiet Lite z Licencją wieczystą oraz dodatkowe pakiety licencyjne do zakupu, objęte 30-dniową gwarancją zwrotu pieniędzy.
Jak rozwiązywać typowe problemy podczas wyodrębniania tabel z plików PDF przy użyciu IronPDF?
Aby rozwiązać problemy z wyodrębnianiem danych w IronPDF, upewnij się, że środowisko Python jest poprawnie skonfigurowane i zawiera wszystkie niezbędne instalacje. Sprawdź, czy plik PDF jest dostępny, oraz zweryfikuj składnię kodu pod kątem użycia metod PdfDocument.FromFile() i ExtractAllText(). Aby uzyskać dalsze wskazówki, zapoznaj się z dokumentacją IronPDF.
Jakie funkcje bezpieczeństwa oferuje IronPDF w zakresie obsługi plików PDF?
IronPDF zawiera solidne funkcje bezpieczeństwa do obsługi plików PDF, takie jak ochrona hasłem i szyfrowanie, zapewniające bezpieczeństwo dokumentów podczas przetwarzania i dystrybucji.
Czy istnieje obsługa wyodrębniania obrazów z plików PDF przy użyciu IronPDF w języku Python?
Tak, IronPDF obsługuje wyodrębnianie obrazów z plików PDF w języku Python, umożliwiając izolowanie i zapisywanie obrazów z dokumentów PDF w ramach zadań związanych z przetwarzaniem danych.
Jakie środowisko IDE jest zalecane do programowania w języku Python z wykorzystaniem IronPDF?
Do programowania w języku Python z wykorzystaniem IronPDF zaleca się użycie PyCharm, ponieważ oferuje on kompleksowe środowisko IDE z zaawansowanymi funkcjami do efektywnego kodowania, debugowania i zarządzania projektami w języku Python.
















