Comment extraire un tableau d'un PDF en Python
Cet article va démontrer comment utiliser IronPDF, une bibliothèque de traitement PDF puissante, pour extraire facilement des données de tables complexes dans n'importe quel fichier PDF.
IronPDF
Python offre beaucoup plus de flexibilité pour les programmeurs comparé à d'autres langages et permet aux développeurs de concevoir facilement et efficacement des interfaces utilisateur graphiques. Par conséquent, l'incorporation de la bibliothèque IronPDF dans Python est un processus simple. Pour créer rapidement et en toute sécurité une interface graphique entièrement fonctionnelle, une gamme d'outils préinstallés, y compris PyQt, wxWidgets, Kivy, et divers autres packages et bibliothèques, peut être utilisée.
IronPDF simplifie la conception et le développement web avec Python. Ceci est principalement dû à l'abondance de frameworks de développement web Python disponibles, tels que Django, Flask, et Pyramid. Quelques sites web et services en ligne remarquables qui ont employé ces frameworks incluent Reddit, Mozilla, et Spotify.
Comment extraire un tableau d'un PDF en Python
- Téléchargez un module Python pour extraire un tableau d'un PDF
- Utilisez la méthode `FromFile` pour importer le fichier PDF
- Extrayez le texte des tableaux à l'aide de la méthode `ExtractAllText`
- Parcourir le texte extrait pour diviser les lignes
- Sortir le texte extrait vers la console ou un fichier texte
Fonctionnalités d'IronPDF
Voici quelques caractéristiques de IronPDF :
- Les fichiers PDF peuvent être créés à partir de diverses sources comme HTML, HTML5, ASP, PHP, et plus encore. De plus, les fichiers image peuvent être convertis en PDF avec les fichiers HTML.
- IronPDF permet la création de documents PDF interactifs. Il offre des fonctionnalités telles que diviser et combiner des fichiers PDF, extraire du texte et des images depuis des fichiers PDF, rasteriser des pages PDF en images, convertir des PDF en HTML, imprimer des fichiers PDF, remplir et soumettre des formulaires interactifs, et diviser et fusionner des fichiers PDF.
- Avec IronPDF, il est possible de générer un document à partir d'une URL. Il prend également en charge les agents utilisateurs se connectant via des formulaires de connexion HTML, des proxys, des cookies, des en-têtes HTTP, des identifiants de connexion réseau spéciaux, des variables de formulaire, et des agents utilisateurs.
- Le programme IronPDF permet l'inspection et l'annotation des fichiers PDF.
- IronPDF permet d'extraire des images de documents.
- IronPDF fournit aux utilisateurs la possibilité d'ajouter des en-têtes, pieds de page, texte, photos, marque-pages, filigranes, et plus aux documents.
- Avec IronPDF, vous pouvez diviser et fusionner des pages dans un document nouveau ou existant.
- La conversion de documents en objets PDF est possible sans avoir besoin d'une visionneuse Acrobat.
- IronPDF permet la création d'un document PDF à partir d'un fichier CSS.
- Les documents peuvent être créés en utilisant des fichiers CSS contenant des définitions de type de média avec IronPDF.
Configurer l'environnement Python
Configurer Python
Assurez-vous que Python est installé sur votre ordinateur. Pour télécharger et configurer la version la plus récente de Python pour votre système d'exploitation, rendez-vous sur le site officiel de Python. Une fois Python installé, séparez les besoins de votre projet en créant un environnement virtuel. Grâce au module venv, vous pouvez créer et gérer des environnements virtuels pour offrir à votre projet de conversion un espace de travail propre et organisé.
Nouveau projet dans PyCharm
Pour ce tutoriel, il est recommandé d'utiliser PyCharm, un IDE pour le développement en Python.
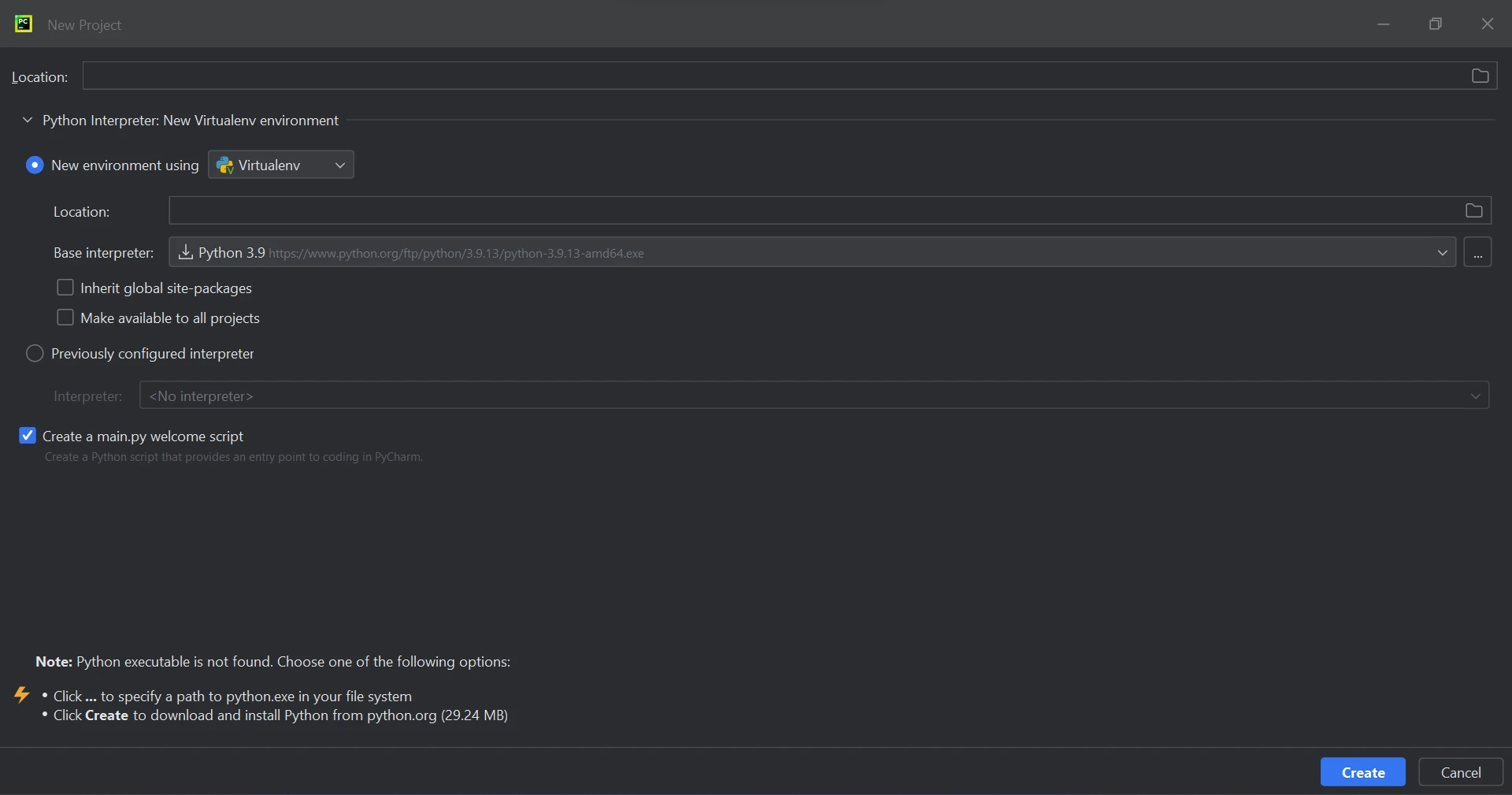
Après avoir lancé l'IDE PyCharm, sélectionnez "Nouveau projet" dans le menu, comme indiqué dans la figure ci-dessous.
 IDE PyCharm
IDE PyCharm
Comme vu dans l'image ci-dessous, quand vous choisissez "Nouveau projet", une nouvelle fenêtre apparaîtra et vous permettra de définir l'emplacement du projet et l'environnement Python.
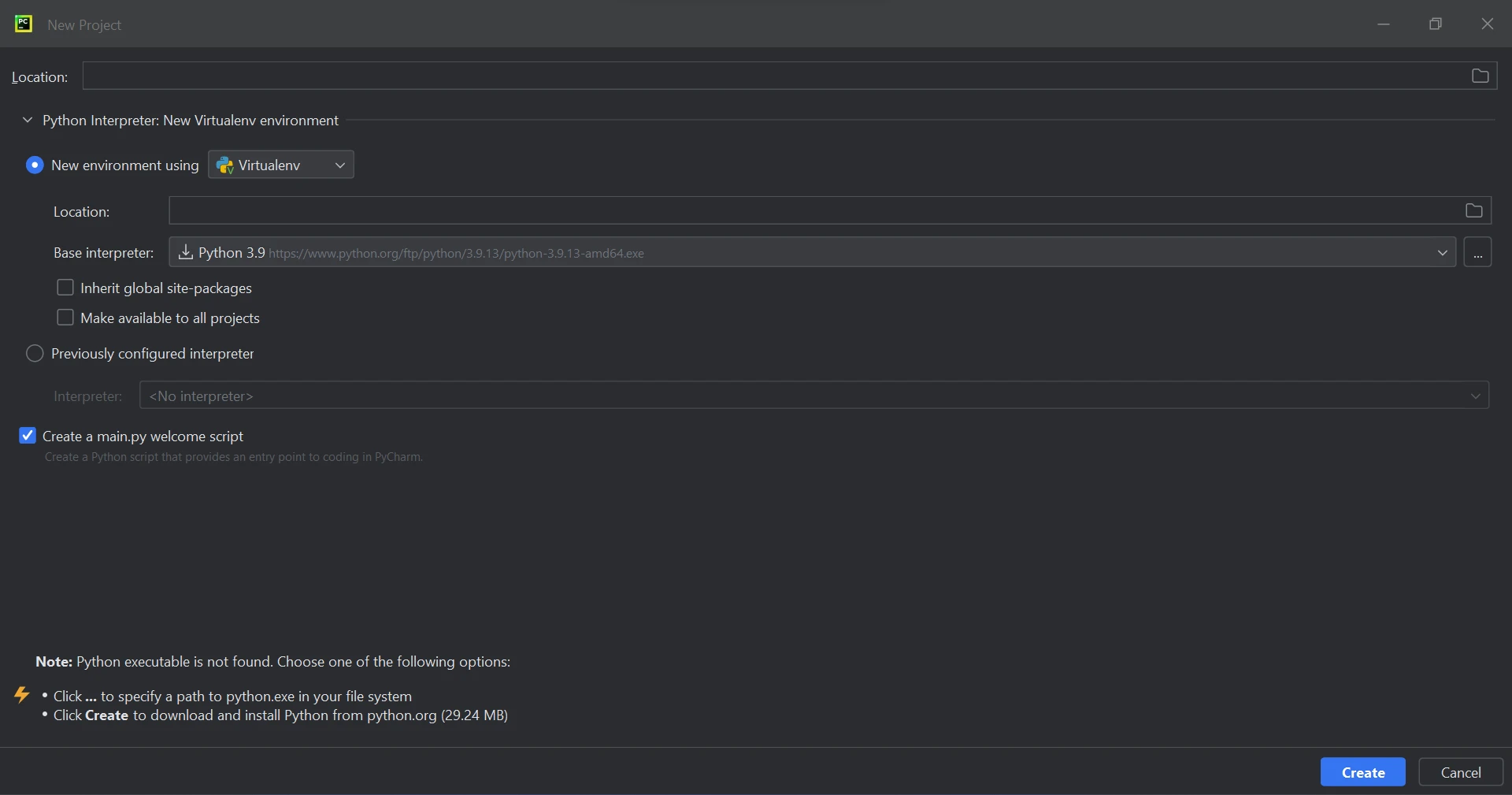 Créer un nouveau projet dans PyCharm
Créer un nouveau projet dans PyCharm
Après avoir sélectionné l'emplacement et l'environnement pour le projet, cliquez sur le bouton Créer pour l'initier. Les fichiers Python peuvent être ouverts dans la nouvelle fenêtre lancée pour que vous y entriez votre code. Ce guide utilise Python 3.9.
 le fichier Python principal
le fichier Python principal
Exigence de la bibliothèque IronPDF
IronPDF for Python s'appuie sur .NET 6.0 comme technologie de base. Par conséquent, pour utiliser IronPDF for Python, votre ordinateur doit avoir le runtime .NET 6.0 installé. Les utilisateurs de Linux et Mac peuvent avoir besoin d'installer .NET avant de pouvoir utiliser ce module Python. Téléchargez l'environnement d'exécution nécessaire depuis Microsoft.
Configuration de la bibliothèque IronPDF
Le package ironpdf doit être installé afin de créer, modifier et ouvrir des fichiers avec l'extension ".pdf". Pour installer le package dans PyCharm, ouvrez une fenêtre de terminal et tapez la commande suivante :
pip install ironpdf
La capture d'écran ci-dessous illustre le processus d'installation du package ironpdf.
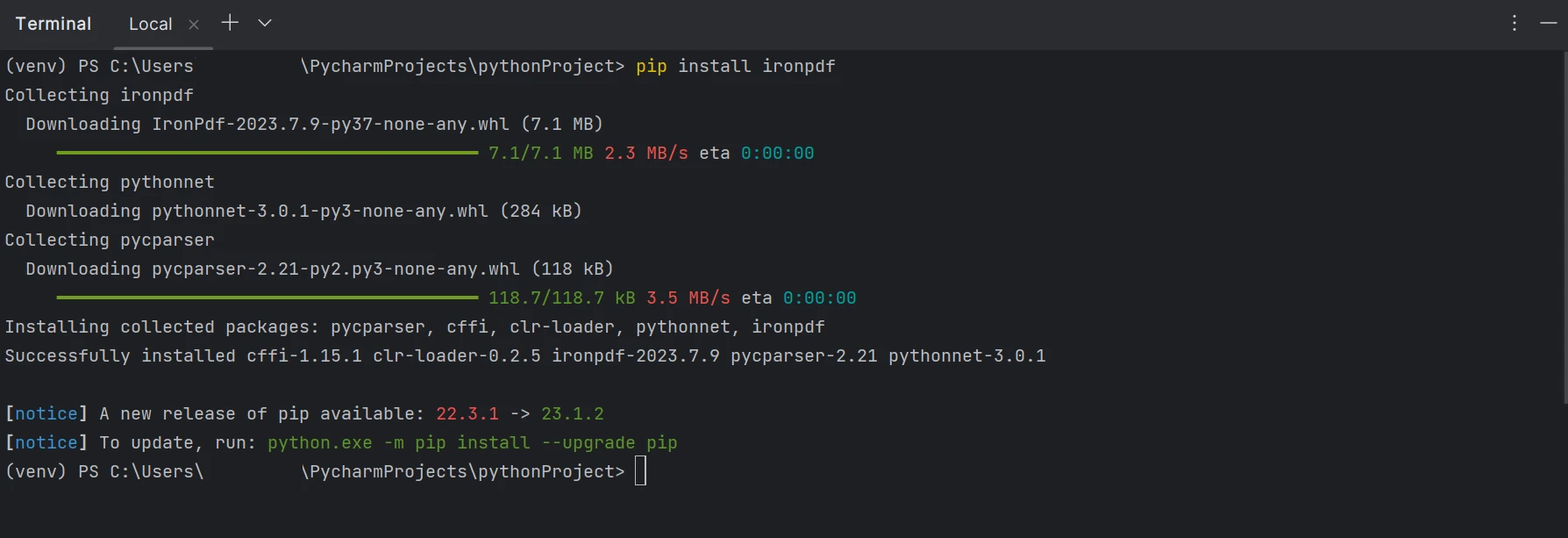 Installer le package IronPDF
Installer le package IronPDF
Extraction de données de tableau à partir d'un fichier PDF
Nous pouvons extraire facilement des données des fichiers PDF en utilisant la bibliothèque IronPDF for Python. IronPDF facilite l'analyse des données textuelles et l'extraction de tableaux à partir de fichiers PDF. Ci-dessous un exemple de code qui montre comment extraire des données de tableaux PDF, en utilisant l'image fournie comme référence.
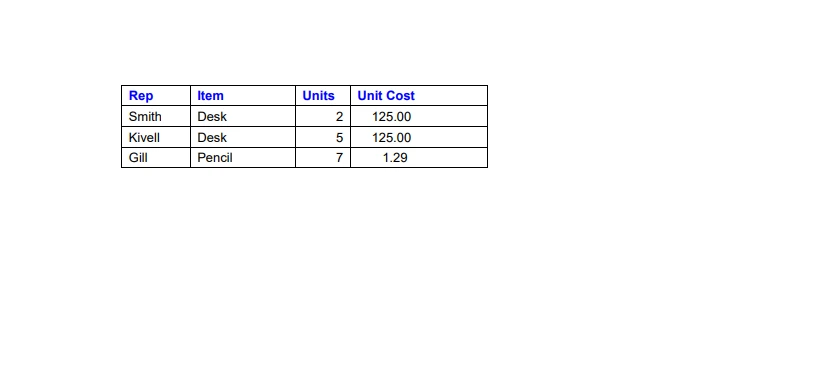 Les données échantillons d'un fichier PDF
Les données échantillons d'un fichier PDF
from ironpdf import PdfDocument
# Load the PDF document
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Split the extracted text into rows and print each row
for row in all_text.split("\n"):
print(row)from ironpdf import PdfDocument
# Load the PDF document
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Split the extracted text into rows and print each row
for row in all_text.split("\n"):
print(row)Le code fourni montre comment IronPDF peut être utilisé pour extraire des tableaux à partir de fichiers PDF à l'aide de quelques lignes de code Python. Initialement, nous importons la bibliothèque IronPDF pour accéder à ses fonctionnalités et pour accéder à toutes les fonctionnalités d'IronPDF. Ensuite, grâce à la classe PdfDocument, les fichiers PDF existants peuvent être traités pour effectuer diverses opérations sur eux.
Lors de l'utilisation de la fonction FromFile, l'argument permettant de charger le fichier PDF d'entrée est disponible. Ensuite, la fonction ExtractAllText extrait toutes les données du tableau de toutes les pages des fichiers PDF. Ensuite, la fonction split est utilisée pour diviser les données du tableau extraites en plusieurs lignes et les afficher sur l'écran de la console.
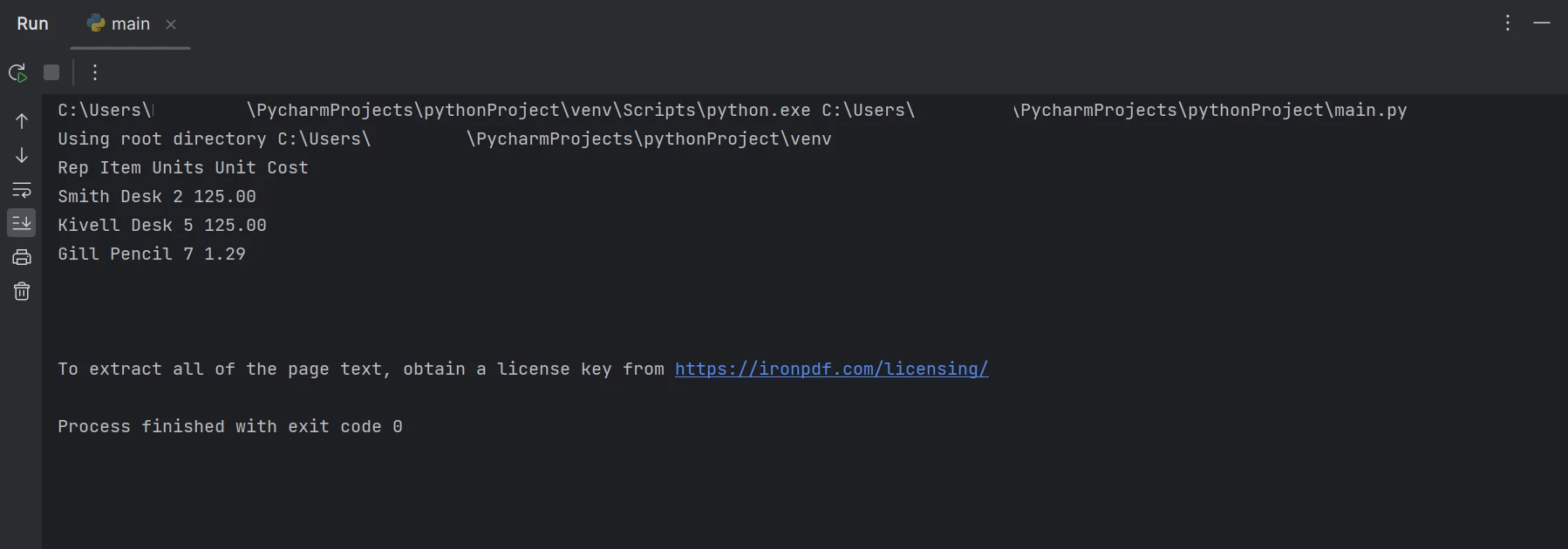 Les données extraites
Les données extraites
Dans le résultat ci-dessus, les données sont affichées ligne par ligne, montrant comment les données de tableau peuvent être extraites. En savoir plus sur IronPDF en consultant la documentation du produit.
Conclusion
La bibliothèque IronPDF fournit des mesures de sécurité robustes pour minimiser les risques potentiels et garantir la sécurité des données. Elle est compatible avec tous les navigateurs populaires et n'est pas limitée à un en particulier. Avec IronPDF, les programmeurs peuvent créer et lire efficacement des fichiers PDF à l'aide de quelques lignes de code. Pour répondre aux divers besoins des développeurs, la bibliothèque IronPDF propose différentes options de licence, y compris une licence développeur gratuite et des licences de développement supplémentaires disponibles à l'achat.
Le pack Lite , au prix de $999, comprend une licence perpétuelle, une garantie de remboursement de 30 jours, un an de maintenance logicielle et des possibilités de mise à niveau. Il n'y a pas de frais supplémentaires après l'achat initial, et ces licences peuvent être utilisées dans les environnements de production, de staging, et de développement. IronPDF propose également des licences gratuites avec certaines limitations de temps et de redistribution. Les utilisateurs peuvent tester le produit dans un environnement réel avec une période d'essai gratuite qui ne comprend pas de filigrane. Pour des informations détaillées concernant le coût et l'octroi de licences de la version d'essai d'IronPDF, cliquez sur la page des licences.
Questions Fréquemment Posées
Comment puis-je extraire des tableaux d'un PDF en Python ?
Pour extraire des tables d'un PDF en using IronPDF en Python, vous pouvez utiliser la méthode PdfDocument.FromFile() pour charger le PDF, puis utiliser ExtractAllText() pour extraire le texte. Le texte peut ensuite être traité et divisé en lignes pour récupérer les données de table.
Quelles sont les étapes pour configurer l'environnement Python pour utiliser IronPDF ?
Pour configurer votre environnement Python pour utiliser IronPDF, assurez-vous que Python est installé, créez un environnement virtuel et installez le runtime .NET 6.0. Vous pouvez ensuite installer IronPDF en utilisant la commande pip install ironpdf.
Quelles fonctionnalités de manipulation de PDF IronPDF propose-t-il en Python ?
IronPDF offre une large gamme de fonctionnalités de manipulation de PDF en Python, y compris la capacité de créer des PDF à partir de HTML, d'images et d'autres sources, d'extraire du texte et des images, et de créer des PDF interactifs avec annotations, en-têtes, pieds de page, et filigranes.
Puis-je convertir du HTML en PDF en using IronPDF en Python ?
Oui, IronPDF vous permet de convertir du HTML en PDF en Python. Vous pouvez rendre des chaînes ou des fichiers HTML sous forme de PDF en utilisant les méthodes d'IronPDF, facilitant la création de documents PDF à partir de contenus web.
Quelles options de licence sont disponibles pour IronPDF en Python ?
IronPDF propose plusieurs options de licence, y compris une licence de développeur gratuite pour les tests, un pack Lite avec une licence perpétuelle, et des forfaits de licence supplémentaires à l'achat, soutenus par une garantie de remboursement de 30 jours.
Comment puis-je résoudre les problèmes courants lors de l'extraction de tables d'un PDF en using IronPDF ?
Pour résoudre les problèmes d'extraction avec IronPDF, assurez-vous que votre environnement Python est correctement configuré avec toutes les installations nécessaires. Vérifiez que le fichier PDF est accessible et vérifiez la syntaxe de votre code pour l'utilisation des méthodes PdfDocument.FromFile() et ExtractAllText(). Consultez la documentation IronPDF pour plus de conseils.
Quelles fonctionnalités de sécurité IronPDF offre-t-il pour la gestion des PDF ?
IronPDF intègre des fonctionnalités de sécurité robustes pour la gestion des PDF, telles que la protection par mot de passe et le cryptage, garantissant que vos documents sont sécurisés pendant le traitement et la distribution.
Existe-t-il un support pour l'extraction d'images des PDF en using IronPDF en Python ?
Oui, IronPDF prend en charge l'extraction d'images des PDF en Python, vous permettant d'isoler et de sauvegarder les images des documents PDF dans le cadre de vos tâches de traitement de données.
Quel est l'IDE recommandé pour le développement Python avec IronPDF ?
PyCharm est recommandé pour le développement Python avec IronPDF, car il offre un IDE complet avec des fonctionnalités avancées pour le codage, le débogage et la gestion efficace des projets Python.