
Comment extraire des données d'un PDF en Python
Un package Python robuste appelé IronPDF peut être utilisé pour extraire des données, des images, des boutons radio, des boîtes de liste (au lieu de widgets de case à cocher), et d'autres informations à partir de fichiers PDF. Cet article montrera comment utiliser cette bibliothèque pour regrouper des formulaires interactifs avec des données et générer de nouveaux fichiers PDF et des formulaires PDF.
Comment Extraire des Données à partir du PDF en Python
- Obtenez le fichier PDF pour extraire le texte à des fins de traitement des données.
- Créez un projet dans PyCharm.
- Configurez les bibliothèques Python nécessaires pour votre projet.
- Extrayez des informations de pages spécifiques dans le document PDF.
- Imprimez le contenu textuel extrait du document PDF.
2. IronPDF
La bibliothèque IronPDF for Python améliore parfaitement la programmation Python en facilitant un traitement efficace des données PDF et en offrant une multitude d'opérations PDF. Ses capacités d'intégration s'étendent à divers frameworks, élargissant les capacités de développement d'interfaces utilisateur graphiques.
Python est un langage de programmation polyvalent qui permet une création rapide et facile d'interfaces graphiques conviviales, ce qui en fait un choix privilégié pour de nombreux développeurs. Sa nature dynamique le distingue des autres langages de programmation. L'introduction de la bibliothèque IronPDF à Python s'avère être un processus simple, permettant une gestion et un traitement efficaces des données PDF.
Pour le développement rapide et sécurisé d'interfaces graphiques entièrement fonctionnelles, les développeurs peuvent tirer parti d'une large gamme d'outils préinstallés et de bibliothèques Python populaires, y compris PyQt, wxWidgets, Kivy, et bien d'autres.
De plus, la bibliothèque IronPDF intègre parfaitement diverses fonctionnalités provenant d'autres frameworks, en particulier dans le contexte de .NET Core, qui étend le support à Python et plusieurs autres langages de programmation. De plus amples informations sur Python IronPDF peuvent être consultées en visitant le site officiel.
La bibliothèque IronPDF for Python simplifie le processus de création et de gestion de sites web, notamment en ce qui concerne le développement web basé sur Python utilisant des frameworks comme Django, Flask, et Pyramid. C'est un outil précieux sur lequel ces sites web et services en ligne populaires, tels que Reddit, Mozilla et Spotify, s'appuient pour améliorer leur fonctionnalité et leurs caractéristiques.
2.1 Fonctionnalités d'IronPDF
HTML, HTML5, ASPX et View Razor/MVC sont quelques-uns des formats qui peuvent être convertis en format PDF avec IronPDF. En outre, IronPDF offre la capacité pratique de générer des fichiers PDF à partir d'images et de pages HTML.
L'ensemble d'outils IronPDF peut aider à diverses tâches, y compris la création de PDF interactifs, la facilitation de la complète et de la soumission des formulaires interactifs, le fusionnement et division efficaces des fichiers PDF, l'extraction précise de texte et d'images, la recherche textuelle complète au sein des fichiers PDF, la transformation de PDF en images, et la flexibilité pour personnaliser les tailles de police, les bordures et les couleurs de fond. IronPDF peut également réaliser des conversions de fichiers PDF sans effort.
IronPDF va plus loin en étendant son support aux agents utilisateurs, proxys, cookies, en-têtes HTTP, et variables de formulaire, améliorant ainsi la validation des formulaires de connexion HTML. Il utilise des noms d'utilisateur et des mots de passe pour protéger l'accès utilisateur au texte sécurisé contenu dans les PDFs.
Un impression de fichier PDF peut être produit à partir de nombreuses sources, telles qu'une chaîne, un flux ou une URL, et est réalisable avec seulement quelques lignes de code.
IronPDF peut produire des documents PDF aplatis en convertissant les éléments interactifs et en s'assurant que le contenu du document reste inchangé et visible mais non modifiable.
3. Configuration et Installation
3.1 Installer Python et Créer un Environnement Virtuel
Assurez-vous d'avoir le langage de programmation Python installé sur votre ordinateur personnel. C'est important car les bibliothèques Python sont souvent requises pour diverses tâches. Pour ce faire, visitez le site officiel de Python et téléchargez la dernière version compatible avec votre système d'exploitation. Cela vous garantit d'avoir les bons outils pour travailler efficacement avec les bibliothèques Python.
Après avoir installé Python, établissez un environnement virtuel pour isoler les bibliothèques nécessaires à votre projet, car certains projets peuvent nécessiter certaines bibliothèques de Python. Le module venv, qui vous permet de construire et de maintenir des environnements virtuels, pourrait aider votre projet de conversion à avoir un espace de travail propre et autonome, surtout lorsque vous traitez avec plusieurs bibliothèques Python.
3.2 Configuration d'un Nouveau Projet dans PyCharm
Vous avez la flexibilité d'écrire du code Python en utilisant n'importe quel éditeur de texte ou environnement de programmation, comme Visual Studio Code, PyCharm, ou Sublime Text. Cependant, cet article utilise PyCharm, un IDE pour écrire du code Python, afin de créer un projet Python.
Une fois que l'IDE PyCharm est lancé, sélectionnez Nouveau Projet.
 IDE PyCharm pour créer un Nouveau Projet Python
IDE PyCharm pour créer un Nouveau Projet Python
Après avoir sélectionné Nouveau Projet, vous verrez une nouvelle fenêtre vous permettant de spécifier l'environnement et l'emplacement du projet. L'image ci-dessous pourrait apporter plus de clarté.
Après avoir configuré les détails de l'emplacement du projet et de l'environnement et en cliquant sur Créer vous entrerez dans l'interface de PyCharm. Ici, vous trouverez la structure de votre projet et les fichiers de code. C'est votre espace de travail pour gérer et développer votre projet. Python 3.9 est la version utilisée dans ce guide.
 Le fichier principal en Python
Le fichier principal en Python
3.3 Exigences de Bibliothèque pour IronPDF
La bibliothèque Python IronPDF s'interface communément avec .NET 6.0. Par conséquent, pour utiliser efficacement IronPDF for Python, votre ordinateur doit être équipé du runtime .NET 6.0.
Pour les utilisateurs Linux et Mac, il peut être nécessaire d'installer .NET avant d'utiliser ce module Python. Pour des conseils sur l'obtention de l'environnement runtime requis, veuillez visiter cette page de téléchargement Microsoft.
3.4 Installer la Bibliothèque IronPDF
Vous devez installer le package "IronPDF" pour travailler avec des fichiers PDF, y compris leur création, modification et ouverture. Pour ce faire dans PyCharm, ouvrez la fenêtre du terminal et entrez cette commande :
pip install ironpdf
Référez-vous à la capture d'écran ci-dessous pour l'installation du package ironpdf.
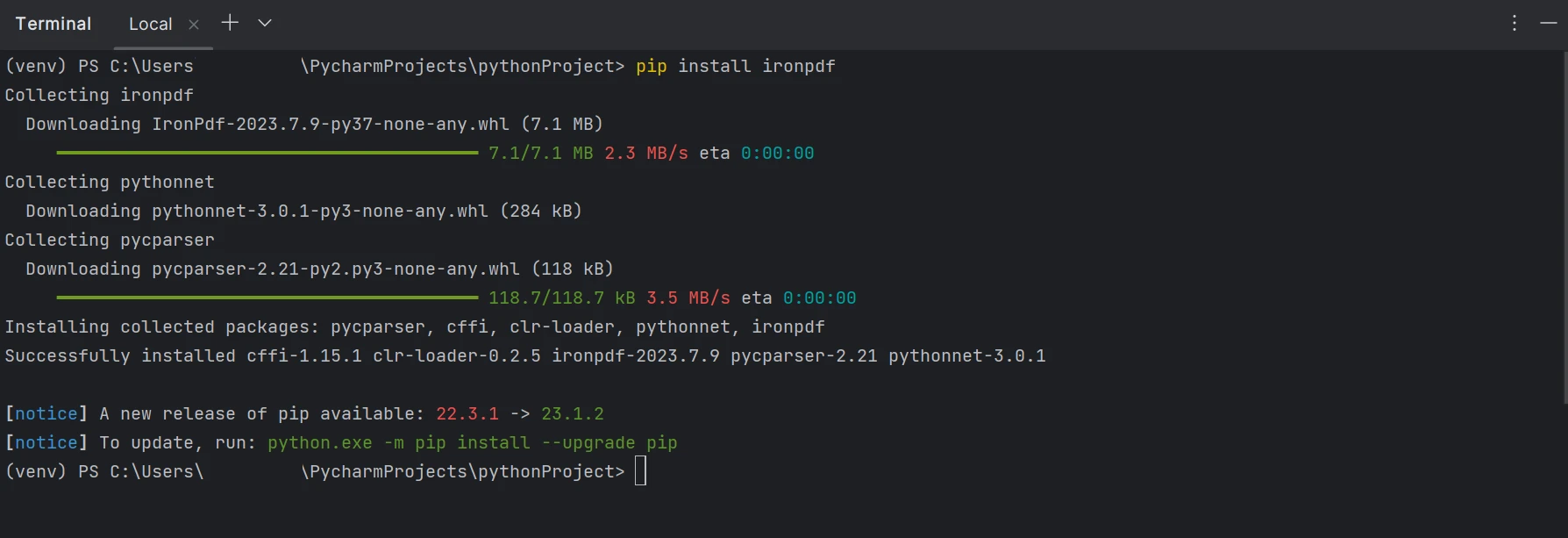 Installation d'IronPDF
Installation d'IronPDF
4. Extraire du Texte de Fichiers PDF
La bibliothèque IronPDF for Python transforme efficacement les pages PDF en objets de page PDF, simplifiant le processus d'extraction de contenu textuel à partir de fichiers PDF.
4.1 Extraction de Toutes les Données Textuelles du fichier PDF
Dans cet exemple, le processus d'extraction de texte à partir d'un PDF existant à l'aide de IronPDF est démontré. Dans ce cas, le document PDF ci-dessous est utilisé pour cette démonstration.
La première méthode se concentre sur l'extraction de tout le texte du fichier PDF. Écrivez le code suivant pour effectuer facilement une extraction de données complète sur le PDF d'entrée :
from ironpdf import *
# Load a PDF document from a file
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()from ironpdf import *
# Load a PDF document from a file
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()Comme illustré dans le code ci-dessus, la méthode FromFile joue un rôle clé. Il charge le fichier PDF depuis un emplacement existant pour le convertir en objets PdfDocument. Avec cet objet, tant le contenu textuel que les images présents dans les pages PDF peuvent être accessibles. Pour extraire tout le texte du fichier PDF donné, une méthode appelée ExtractAllText est utilisée. Le texte extrait est alors stocké dans une chaîne, prêt pour un traitement ultérieur.
4.2 Extraction de Texte Page par Page
Voici le code pour la deuxième approche, qui extrait explicitement du texte de chaque page du fichier PDF.
from ironpdf import *
# Load a PDF document from a file
pdf = PdfDocument.FromFile("sampleData.pdf")
# Iterate over each page and extract text
for xpage in range(pdf.PageCount):
# Extract text from the current page
print(pdf.ExtractTextFromPage(xpage))from ironpdf import *
# Load a PDF document from a file
pdf = PdfDocument.FromFile("sampleData.pdf")
# Iterate over each page and extract text
for xpage in range(pdf.PageCount):
# Extract text from the current page
print(pdf.ExtractTextFromPage(xpage))Ce code d'exemple charge initialement l'intégralité du fichier PDF et le transforme en un objet PdfDocument appelé pdf. Pour garantir que chaque page spécifique du fichier PDF est traitée séquentiellement, chaque page est accédée à l'aide de son numéro de page ou de son indice de page dans l'objet pdf. Pour ce faire d'abord, le nombre total de pages présentes dans le PDF d'entrée est déterminé en utilisant la méthode PageCount de son objet pdf.
Avec ce nombre de pages, une boucle for itère à travers chaque page, en appelant la fonction ExtractTextFromPage pour extraire le texte de chaque page du document PDF. Le texte extrait peut être stocké dans une variable de chaîne ou affiché à l'écran utilisateur. Ainsi, cette méthode permet l'extraction organisée de texte de chaque page PDF séparée. Ces méthodes, issues de IronPDF, une bibliothèque Python destinée aux tâches PDF, mettent en évidence sa capacité à rendre l'extraction de texte à partir de fichiers PDF facile et complète. Cette accessibilité a de nombreuses applications pratiques et améliore l'utilité des PDFs dans différents domaines.
5. Conclusion
La bibliothèque IronPDF incorpore de fortes mesures de sécurité pour atténuer les risques potentiels et assurer la sécurité des données. Elle fonctionne efficacement sur tous les navigateurs largement utilisés sans limitations spécifiques. IronPDF permet aux développeurs de générer et d'analyser efficacement des documents PDF avec peu de lignes de code Python. Pour répondre aux diverses exigences des développeurs, la bibliothèque IronPDF présente une gamme de choix de licences, englobant une licence de développeur gratuite et des licences de développement supplémentaires disponibles à l'acquisition.
Le package Lite coûte $999 et vous donne une licence permanente. Vous bénéficiez également d'une garantie de remboursement de 30 jours, d'une année de maintenance logicielle et de la possibilité d'obtenir des mises à jour. Après l'achat, il n'y a pas de frais supplémentaires. Vous pouvez utiliser cette licence en production, en préproduction et en développement. IronPDF propose également des licences gratuites avec certaines limites de temps et de partage. Vous pouvez l'essayer pendant 30 jours sans filigrane. Pour le coût et comment obtenir la version d'essai d'IronPDF, veuillez visiter la page de licence d'IronPDF.
Questions Fréquemment Posées
Comment puis-je extraire des données d'un fichier PDF en utilisant Python ?
Vous pouvez utiliser IronPDF pour extraire des données de fichiers PDF en Python. Chargez le PDF en utilisant la méthode PdfDocument.FromFile() et utilisez la méthode ExtractAllText() ou ExtractTextFromPage() pour récupérer les données textuelles.
Quelles sont les étapes pour configurer IronPDF dans un projet Python ?
Pour configurer IronPDF dans votre projet Python, installez d'abord Python et configurez un environnement virtuel. Ensuite, utilisez la commande pip install ironpdf pour installer la bibliothèque IronPDF. Assurez-vous que votre système dispose du runtime .NET 6.0 installé.
Puis-je convertir du contenu HTML en PDF en utilisant Python ?
Oui, IronPDF vous permet de convertir du contenu HTML en PDF en Python. Vous pouvez utiliser les méthodes RenderUrlAsPdf() ou RenderHtmlAsPdf() pour convertir des pages web ou des chaînes HTML en documents PDF.
IronPDF prend-il en charge la création et la gestion de formulaires PDF ?
IronPDF prend en charge la création et la gestion de formulaires PDF interactifs. Vous pouvez l'utiliser pour remplir des formulaires de manière programmée et les soumettre, améliorant ainsi l'interactivité de vos documents PDF.
Comment IronPDF peut-il être intégré aux frameworks web en Python ?
IronPDF peut être intégré aux frameworks web Python populaires comme Django et Flask. Cette intégration vous permet de générer des PDF de manière dynamique à partir d'applications web, améliorant ainsi les capacités de développement web.
Quelles fonctionnalités offre IronPDF pour la manipulation de PDF en Python ?
IronPDF fournit des fonctionnalités telles que l'extraction de texte et d'images, le découpage et la fusion de PDF, la conversion de HTML et d'images en PDF, et le support des formulaires interactifs. Il permet également des personnalisations et une gestion sécurisée des accès pour les PDFs.
Quelles sont les options de licence disponibles pour utiliser IronPDF ?
IronPDF propose plusieurs options de licence, y compris une licence développeur gratuite et diverses licences payantes pour différents niveaux de développement et de besoins de déploiement.
Est-il possible d'extraire des images d'un PDF avec IronPDF en Python ?
Oui, vous pouvez extraire des images d'un PDF avec IronPDF en accédant aux données d'image au sein des pages PDF, vous permettant de les enregistrer ou de les manipuler selon vos besoins.
Quelles sont les exigences système pour exécuter IronPDF dans un environnement Python ?
Pour exécuter IronPDF en Python, vous devez disposer du runtime .NET 6.0 installé sur votre système. Cette exigence est particulièrement importante pour les utilisateurs de Linux et MacOS.
Comment puis-je garantir un accès sécurisé aux PDF générés en Python ?
IronPDF vous permet de mettre en œuvre des mesures de sécurité telles que la protection par mot de passe et le chiffrement pour garantir que vos PDF sont accédés en toute sécurité, protégeant ainsi les informations sensibles.
















