
如何在 Python 中从 PDF 提取数据
一个名为 IronPDF 的强大 Python 包可以用于从 PDF 文件中提取数据、图像、单选按钮、列表框小部件(代替复选框小部件)和其他信息。 本文将演示如何使用该库将交互式表单与数据进行分组,并生成新的 PDF 文件和 PDF 表单。
如何从 PDF 中提取数据 Python
- 获取 PDF 文件以提取文本以进行数据处理。
- 在 PyCharm 中创建一个项目。
- 为您的项目配置必要的 Python 库。
- 从 PDF 文档中的特定页面提取信息。
- 打印从 PDF 文档中提取的文本内容。
2. IronPDF
IronPDF 适用于 Python 库通过提供高效的 PDF 数据处理并支持多种 PDF 操作,无缝提升了 Python 编程。 其集成能力扩展到各种框架,扩展了开发图形用户界面的能力。
Python 是一种多功能的编程语言,可快速轻松地创建用户友好的图形界面,使其成为许多开发人员的首选。 其动态特性使其与其他编程语言不同。 将 IronPDF 库引入 Python 被证明是一个简单的过程,可以实现高效的 PDF 数据处理。
为了快速安全地开发功能齐全的图形用户界面,开发人员可以利用许多预安装的工具和流行的 Python 库,包括 PyQt、wxWidgets、Kivy 及许多其他工具。
此外,IronPDF 库无缝集成了其他框架的各种功能,特别是在 .NET Core 的上下文中,扩展了对 Python 和其他几种编程语言的支持。 有关 Python IronPDF 的更多信息,可以访问 官方网站。
IronPDF for Python 库简化了创建和管理网站的过程,特别是在使用 Django、Flask 和 Pyramid 等框架进行基于 Python 的 Web 开发时。 这是一个有价值的工具,受这些流行的网站和在线服务(如 Reddit、Mozilla 和 Spotify)依赖,以提高其功能和特性。
2.1 IronPDF 功能
HTML、HTML5、ASPX 和 Razor/MVC View 是一些可以使用 IronPDF 转换为 PDF 格式的格式。 此外,IronPDF 还提供了从图像和 HTML 页面生成 PDF 文件的便捷功能。
IronPDF 工具包可协助完成各种任务,包括创建交互式 PDF、促进交互式表单完成和提交、高效的合并和拆分PDF 文件、精确的文本和图像提取、在 PDF 文件中进行全面的文本搜索、将PDF 转换为图像,并提供灵活的自定义字体大小、边框和背景颜色。 IronPDF 还可以轻松实现 PDF 文件转换。
IronPDF 更进一步,通过扩展对用户代理、代理、Cookie、HTTP 头和表单变量的支持,从而增强HTML 登录表单验证。 它使用用户名和密码来保护用户访问 PDF 中包含的安全文本。
可以从许多来源(例如字符串、流或 URL)生成PDF 文件打印,只需几行代码即可实现。
IronPDF 可以通过转换交互式元素,确保文档内容保持不可更改和可查看但不可编辑的状态,从而生成扁平化的 PDF 文档。
3. 配置和安装
3.1 安装 Python 并创建虚拟环境
确保您在个人计算机上安装了 Python 编程语言。 这很重要,因为 Python 库在各种任务中经常需要。 为此,请访问Python 官方网站并下载与您的操作系统兼容的最新版本。 这可确保您拥有与 Python 库有效协作的正确工具。
安装 Python 后,建立一个虚拟环境,以隔离项目所需的库,因为某些项目可能需要 Python 中的一些必要库。 venv 模块允许您构建和维护虚拟环境,这可以帮助您的转换项目拥有一个整洁、自主的工作环境,尤其是在处理多个 Python 库时。
3.2 在 PyCharm 中设置新项目
您可以使用任何文本编辑器或编码环境编写 Python 代码,例如Visual Studio Code、PyCharm或Sublime Text。 然而,本文使用 PyCharm,这是一种用于编写 Python 代码的 IDE 来创建 Python 项目。
启动 PyCharm IDE 后,选择新项目。
 PyCharm IDE 创建新 Python 项目
PyCharm IDE 创建新 Python 项目
选择新项目后,您将看到允许您指定项目的环境和位置的新窗口。 下面的图片可能会提供更多清晰度。
设置项目位置和环境详细信息后,点击创建,您将进入 PyCharm 的界面。 在这里,您可以找到项目的结构和代码文件。 这是您管理和开发项目的工作空间。 本指南中使用的是 Python 3.9。
 主 Python 文件
主 Python 文件
3.3 IronPDF 的库要求
Python 库 IronPDF 通常与 .NET 6.0 配合使用。因此,为有效使用 IronPDF for Python,您的计算机必须安装 .NET 6.0 运行时。
对于 Linux 和 Mac 用户,可能需要在使用此 Python 模块之前安装 .NET。 有关获取所需运行时环境的指导,请访问此微软下载页面。
3.4 安装 IronPDF 库
您必须安装"ironpdf"包以处理 PDF 文件,包括创建、编辑和打开它们。 要在 PyCharm 中这样做,请打开终端窗口并输入此命令:
pip install ironpdf
请参考下面的屏幕截图,了解 ironpdf 软件包的安装情况。
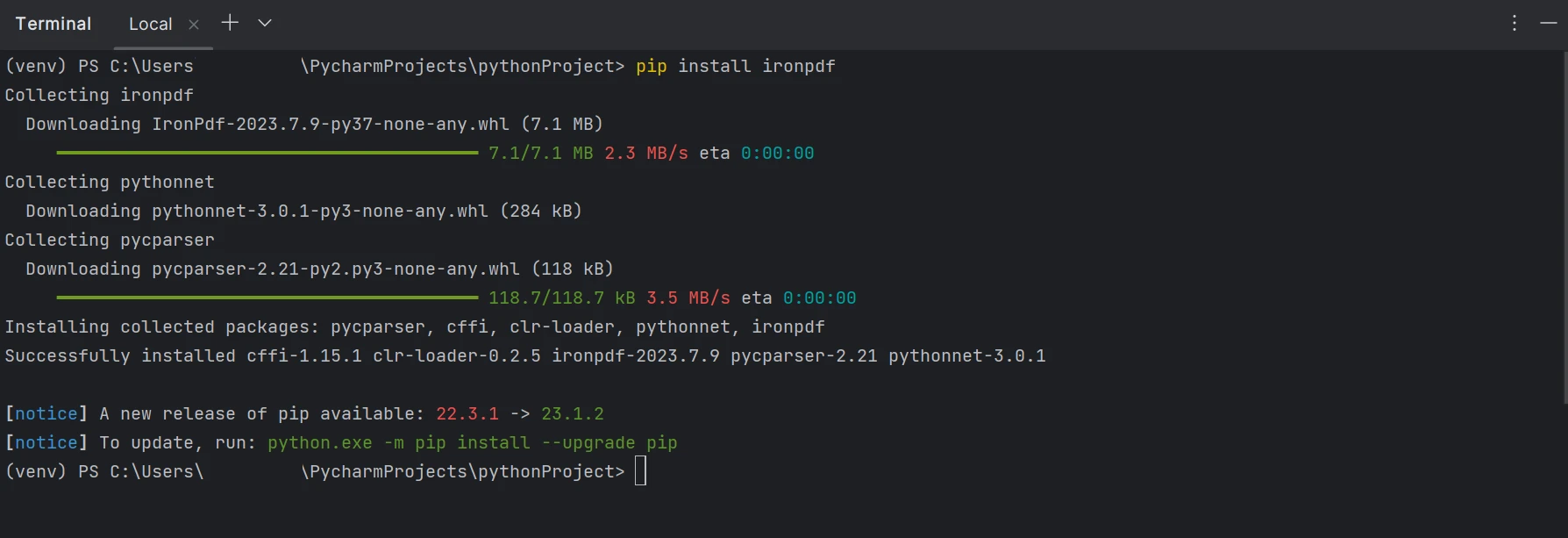 IronPDF 安装
IronPDF 安装
4. 从 PDF 文件中提取文本
IronPDF for Python 库有效地将 PDF 页面转换为 PDF 页面对象,简化了从 PDF 文件中提取文本内容的过程。
4.1 从 PDF 文件中提取所有文本数据
在此示例中,将演示使用 IronPDF 从现有 PDF 中提取文本的过程。 在这种情况下,下面的 PDF 文档用于此演示。
第一种方法是从 PDF 文件中提取所有文本。编写以下代码以方便对输入 PDF 执行完整的数据提取:
from ironpdf import *
# Load a PDF document from a file
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()from ironpdf import *
# Load a PDF document from a file
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()如上面的代码所示,FromFile 方法起着关键作用。 它从现有位置加载 PDF 文件,并将其转换为 PdfDocument 对象。 通过此对象,可以访问 PDF 页面内的文本内容和图像。 要从给定的 PDF 文件中提取所有文本,可以使用名为 ExtractAllText 的方法。 提取的文本然后存储在字符串中,准备进一步处理。
4.2 按页面提取文本
下面是第二种方法的代码,它显式从 PDF 文件的每一页提取文本。
from ironpdf import *
# Load a PDF document from a file
pdf = PdfDocument.FromFile("sampleData.pdf")
# Iterate over each page and extract text
for xpage in range(pdf.PageCount):
# Extract text from the current page
print(pdf.ExtractTextFromPage(xpage))from ironpdf import *
# Load a PDF document from a file
pdf = PdfDocument.FromFile("sampleData.pdf")
# Iterate over each page and extract text
for xpage in range(pdf.PageCount):
# Extract text from the current page
print(pdf.ExtractTextFromPage(xpage))此示例代码首先加载整个 PDF 文件,并将其转换为名为 PdfDocument 的对象。 为了确保按顺序处理 PDF 文件中的每一页,可以使用 pdf 对象中的页码或页索引来访问每一页。 首先,使用其 PageCount 对象的 pdf 方法确定输入 PDF 中的页数总数。
根据这个页数,一个循环遍历每一页,调用函数从 PDF 文档的每一页中提取文本。 提取的文本可以存储在字符串变量中或显示在用户屏幕上。 因此,此方法能够有序地从每个单独的 PDF 页面中提取文本。 这些方法,来自专为 PDF 任务设计的 Python 库 IronPDF,突显其能够轻松而全面地从 PDF 文件中提取文本的能力。 这种可访问性在许多实际应用中具有很多实用意义,增强了 PDF 在各个领域的用途。
5. 结论
IronPDF库结合了强大的安全措施,以减轻潜在风险并确保数据安全。 它在所有广泛使用的浏览器上有效运行,而没有任何特定限制。 IronPDF 使开发人员能够高效生成和解析 PDF 文档,只需很少的 Python 代码行。 为了满足开发人员的各种需求,IronPDF 库提供了一系列许可选择,包括免费开发者许可和可供购买的补充开发许可。
Lite套餐售价为 $999,并提供永久许可证。 您还可以获得 30 天退款保证、一年的软件维护和更新机会。 购买后没有额外费用。 您可以在生产、预发和开发环境中使用此许可。 IronPDF 还提供了具有一些时间和共享限制的免费许可。 您可以在 30 天内免费试用,无水印。 有关 IronPDF 的成本和试用版获取方式,请访问 IronPDF 的许可页面。
常见问题解答
如何使用 Python 从 PDF 文件中提取数据?
您可以使用 IronPDF 在 Python 中从 PDF 文件中提取数据。使用 PdfDocument.FromFile() 方法加载 PDF,并利用 ExtractAllText() 或 ExtractTextFromPage() 方法检索文本数据。
在 Python 项目中设置 IronPDF 的步骤是什么?
要在您的 Python 项目中设置 IronPDF,首先安装 Python 并设置一个虚拟环境。然后,使用命令 pip install ironpdf 来安装 IronPDF 库。确保您的系统安装了 .NET 6.0 运行时。
我可以使用 Python 将 HTML 内容转换为 PDF 吗?
是的,IronPDF 允许您在 Python 中将 HTML 内容转换为 PDF。您可以使用 RenderUrlAsPdf() 或 RenderHtmlAsPdf() 方法将网页或 HTML 字符串转换为 PDF 文档。
IronPDF 是否支持 PDF 表单创建和管理?
IronPDF 支持创建和管理交互式 PDF 表单。您可以使用它来以编程方式填写表单并提交它们,从而增强 PDF 文档的交互性。
IronPDF 如何与 Python 中的 Web 框架集成?
IronPDF 可以与流行的 Python Web 框架如 Django 和 Flask 集成。此集成允许您动态生成 PDF,从 Web 应用程序中增强 Web 开发能力。
IronPDF 为 Python 中的 PDF 操作提供了哪些功能?
IronPDF 提供的功能包括文本和图像提取、PDF 拆分和合并、将 HTML 和图像转换为 PDF,以及支持交互式表单。它还允许自定义和安全访问管理 PDF。
使用 IronPDF 的许可选项有哪些?
IronPDF 提供多种许可选项,包括免费的开发者许可以及各种不同开发和部署需求的付费许可。
使用 IronPDF 在 Python 中从 PDF 提取图像是可能的吗?
是的,您可以使用 IronPDF 从 PDF 中提取图像,访问 PDF 页面中的图像数据,允许您根据需要保存或操作它们。
在 Python 环境中运行 IronPDF 的系统要求是什么?
要在 Python 中运行 IronPDF,您的系统需要安装 .NET 6.0 运行时。对于 Linux 和 MacOS 用户,此要求尤为重要。
如何确保 Python 中生成的 PDF 的安全访问?
IronPDF 允许您实现安全措施,例如密码保护和加密,以确保您的 PDF 被安全访问,保护敏感信息。
















