
如何在 Python 中从 PDF 提取图像
这篇文章将使用 IronPDF for Python 通过 Python 代码从 PDF 文件中提取图像。
IronPDF for Python
IronPDF for Python 是一个前沿且强大的库,为 Python 的 PDF 文档处理带来了新的维度。 作为 PDF 任务的综合解决方案,IronPDF 使得高级 PDF 功能无缝集成到应用程序中。
IronPDF 提供了广泛的工具和 API,可用于从头创建 PDF、将 HTML 转换为高质量 PDF,以及通过合并、拆分和编辑等操作管理 PDF 页面。 这些工具用户友好且高效。 凭借其用户友好的界面和广泛的文档,IronPDF 为开发人员打开了可能性。
无论是创建专业报告和发票、自动化工作流程还是管理文档,IronPDF 都在文档管理和自动化领域提供了宝贵的资产,使得它成为任何寻求在 Python 应用中利用 PDF 强大功能的开发人员的必备工具。
如何使用 IronPDF for Python 从 PDF 中提取图像
- 安装 IronPDF 库以在 Python 中从 PDF 中提取图像。
- 使用
PdfDocument.FromFile方法通过本地磁盘的文件路径加载PDF文件。 - 应用
ExtractAllImages方法从PDF文件中提取图像。 - 使用循环遍历 PDF 中找到的所有提取图像。
- 使用所需的图像扩展名保存这些从 PDF 文件中提取的图像。
前提条件
在深入了解如何使用 Python 从 PDF 中获取图像之前,让我们安装必要的先决条件:
- Python 安装:请确保您的系统上已安装Python解释器。 从 PDF 中获取图像的过程将需要 Python 3.0 或更新版本。 确保您具有兼容的 Python 安装。
IronPDF库:要利用IronPDF的强大功能,您需要使用
pip安装它,这是Python的包管理器。 只需打开您的命令行界面并执行以下命令:pip install ironpdfpip install ironpdfSHELL- 集成开发环境(IDE):尽管不是强制的,但使用 IDE 可以极大地提升您的开发体验。 IDE 提供代码补全、调试以及更简化的工作流程等功能。 一个非常受欢迎的 Python 开发 IDE 是 PyCharm。 您可以从 JetBrains 网站 下载并安装 PyCharm。
一旦这些先决条件到位,您可以通过分步指南探索如何使用 Python 和 IronPDF 的激动人心的世界来获取 PDF 中的图像。
步骤 1 创建一个新的 Python 项目
以下是在 PyCharm 中创建新的 Python 项目的步骤。
- 要在 PyCharm 中启动新的 Python 项目,请打开 PyCharm 应用并导航到顶部菜单。
- 点击 File 并从下拉菜单中选择 New Project。
 PyCharm IDE
PyCharm IDE
- 点击 New Project 后,将出现一个标题为 Create Project 的新窗口。
- 在此窗口中,在顶部的 Location 字段输入您的项目名称。选择环境; 如果您使用虚拟环境,请从提供的选项中选择它。
 在 PyCharm 中创建新的 Python 项目
在 PyCharm 中创建新的 Python 项目
- 选择环境后,点击 Create 按钮以创建您的 Python 项目。
您的 Python 项目现在已创建,可用于各种任务,如提取图像。
步骤 2 安装 IronPDF
要安装IronPDF,请打开终端或单独的命令提示符并输入命令pip install ironpdf,然后按Enter键。 终端会显示如下输出。
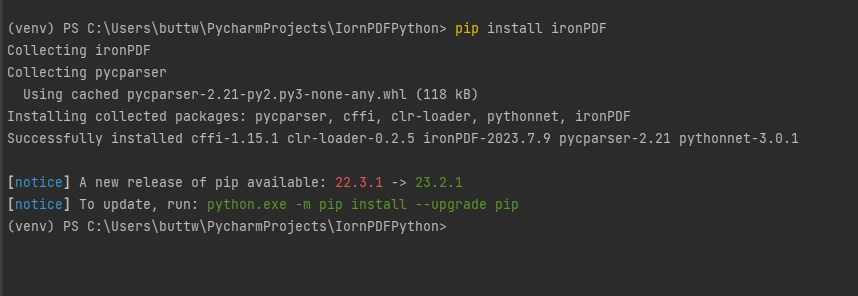 安装IronPDF包
安装IronPDF包
步骤 3 使用 IronPDF 从 PDF 文件中提取图像
IronPDF 为开发人员提供工具和 API,使他们能够轻松导航 PDF 并识别和提取嵌入的图像。 无论是用于分析还是集成,IronPDF 都通过 Python 的灵活性简化了提取。 这使得它对于处理 PDF 和基于图像的应用程序至关重要。它能够从 PDF 文件中提取所有图像,仅需几行代码即可完成。
查看以下代码以使用 Python 编程语言从 PDF 提取图像。
from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")这段代码首先导入了IronPDF库,然后使用文件路径通过PdfDocument.FromFile方法从本地空间加载PDF文件。 它访问 PDF 的每一页以提取图像字节为 Image 对象。 然后使用SaveAs方法保存来自PDF页面的这些图像对象。 代码根据图像索引和所需的图像文件扩展名分配动态图像名称,例子中使用的是 PNG。
这种方法比使用其他 Python 库如 PyMuPDF 和 Pillow 更简单,因为后者需要更多代码来实现相同的任务。
步骤 4 保存从 PDF 文件中提取的图像
图像从 PDF 文件的所有页面提取出来并保存为 PNG 格式。 您还可以通过调整文件扩展名来修改输出格式以匹配所需的图像文件格式。
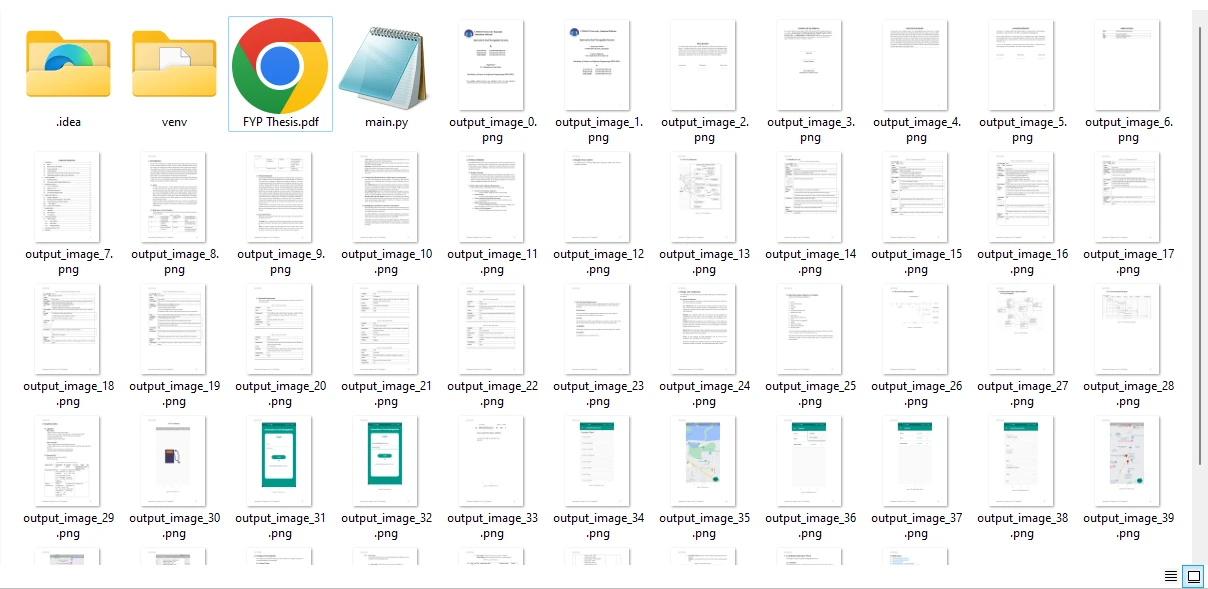 从示例 PDF 文件中提取的图像
从示例 PDF 文件中提取的图像
结论
Python 与强大的 IronPDF 一起,为从 PDF 文件中获取图像的任务提供了一种多功能和高效的解决方案。 利用 Python 的灵活性和 IronPDF 的功能,开发人员可以无缝地浏览 PDF 文档,定位其中的图像字节,并使用所需的图像扩展名保存这些图像。 此过程涉及从 PDF 中获取图像,生成的图像列表可以根据需要进一步处理和操作。 通过掌握如何使用 Python 从 PDF 中获取图像的艺术,开发人员可以提升他们的工作流程,自动化文档管理,并探索广泛的基于图像的应用,这是一种在数字时代非常有价值的技能。
有关从 PDF 文件中提取图像的更多功能,请访问以下 示例。 您可以探索其他操作,比如将 PDF 文件内容转换为图像; 完整的教程可以在此 Python 如何文章 中找到。
常见问题解答
如何使用 Python 从 PDF 中提取图像?
您可以通过使用 PdfDocument.FromFile 方法加载 PDF 和 ExtractAllImages 方法提取图像来使用 IronPDF for Python 从 PDF 中提取图像。
使用 Python 从 PDF 中保存提取的图像步骤有哪些?
要保存提取的图像,请遍历图像并使用 SaveAs 方法以指定的文件扩展名(如 PNG)存储每个图像。
为什么选择 IronPDF 在 Python 中从 PDF 中提取图像?
与其他库如 PyMuPDF 和 Pillow 相比,IronPDF 简化了图像提取过程,减少了实现类似结果所需的代码量。
在 Python 中使用 IronPDF 处理 PDF 的要求是什么?
您需要拥有 Python 3.0 或更新版本,并通过 pip 安装 IronPDF 库。使用诸如 PyCharm 之类的 IDE 进行开发也有益。
如何安装 IronPDF for Python?
IronPDF 可以使用 pip 包管理器安装。在您的命令行界面中运行命令 pip install ironpdf。
IronPDF 可以用于在 Python 中自动化 PDF 文档管理吗?
可以,IronPDF 允许自动化文档管理任务,例如提取图像和转换 PDF 内容,以提高工作流程效率。
IronPDF 支持哪些图像格式来保存提取的图像?
提取的图像可以通过在 SaveAs 方法中指定所需的文件扩展名保存为像 PNG 这样的格式。
IronPDF 适合用于开发基于图像的应用程序吗?
IronPDF 非常适合用于开发基于图像的应用程序,因为它提供了强大的功能来提取和管理 PDF 文档中的图像。
















