Comment extraire des images d'un PDF en Python
Cet article utilisera IronPDF for Python pour extraire des images d'un fichier PDF à l'aide de code Python.
IronPDF for Python
IronPDF pour Python est une bibliothèque de pointe et puissante qui apporte une nouvelle dimension à la gestion des documents PDF en Python. En tant que solution complète pour les tâches PDF, IronPDF permet une intégration transparente des fonctionnalités avancées de PDF dans les applications.
IronPDF fournit une large gamme d'outils et d'API pour des tâches telles que la création de PDF à partir de zéro, la conversion de HTML en PDF de haute qualité, et la gestion des pages PDF via des actions telles que la fusion, la division, et l'édition. Ces outils sont conviviaux et efficaces. Avec son interface conviviale et sa documentation étendue, IronPDF ouvre des possibilités pour les développeurs.
Que ce soit pour créer des rapports et des factures professionnels, automatiser les flux de travail ou gérer des documents, IronPDF propose un atout précieux dans le domaine de la gestion et de l'automatisation des documents, en faisant un outil essentiel pour tout développeur cherchant à tirer parti de la puissance des PDF dans les applications Python.
Comment extraire des images d'un PDF avec IronPDF for Python
- Installez la bibliothèque IronPDF pour extraire des images du PDF en Python.
- Utilisez la méthode
PdfDocument.FromFilepour charger un fichier PDF en utilisant un chemin de fichier sur le disque local. - Appliquez la méthode
ExtractAllImagespour extraire les images des fichiers PDF. - Utilisez une boucle pour itérer à travers toutes les images extraites trouvées dans le PDF.
- Enregistrez ces images extraites du fichier PDF avec l'extension d'image requise.
Prérequis
Avant de plonger dans le monde de l'obtention d'images à partir de PDF en utilisant Python, installons les prérequis nécessaires :
- Installation de Python : assurez-vous d'avoir un interpréteur Python installé sur votre système. Le processus d'obtention d'images à partir de PDF nécessitera Python 3.0 ou des versions plus récentes. Assurez-vous que vous avez une installation Python compatible.
-
Bibliothèque IronPDF : Pour utiliser les puissantes capacités d' IronPDF , vous devrez l'installer à l'aide de
pip, le Package Manager Python. Ouvrez simplement votre interface en ligne de commande et exécutez la commande suivante :pip install ironpdfpip install ironpdfSHELL - Environnement de développement intégré (IDE) : Bien que non obligatoire, l'utilisation d'un IDE peut grandement améliorer votre expérience de développement. Les IDE offrent des fonctionnalités telles que la complétion de code, le débogage et un flux de travail plus rationalisé. Un IDE très populaire pour le développement Python est PyCharm. Vous pouvez télécharger et installer PyCharm depuis le site JetBrains.
Une fois ces prérequis en place, vous pouvez explorer le guide étape par étape à travers le monde passionnant de la récupération d'images à partir de PDF en utilisant Python et IronPDF.
Étape 1 Création d'un nouveau projet Python
Voici les étapes pour créer un nouveau projet Python dans PyCharm.
- Pour initier un nouveau projet Python dans PyCharm, ouvrez l'application PyCharm et naviguez vers le menu du haut.
-
Cliquez sur File et sélectionnez New Project dans le menu déroulant.
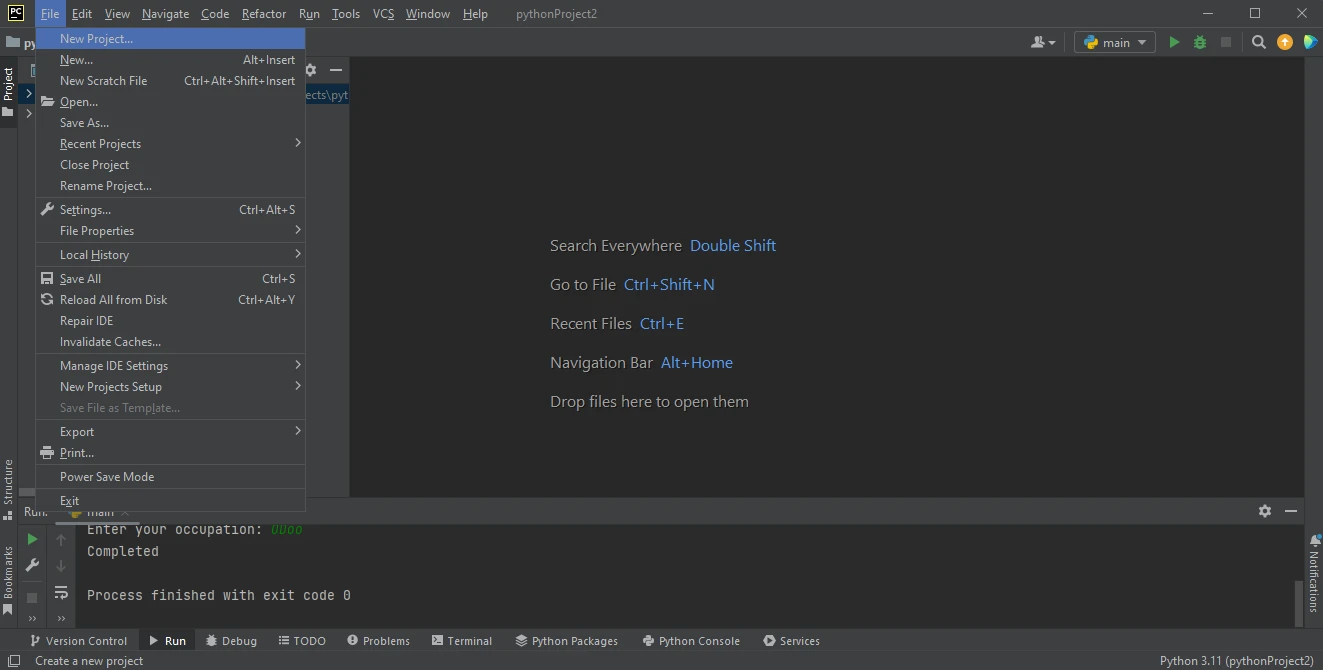 PyCharm IDE
PyCharm IDE - Après avoir cliqué sur New Project, une nouvelle fenêtre avec le titre Create Project apparaîtra.
-
Dans cette fenêtre, entrez le nom de votre projet dans le champ Location en haut. Choisissez l'environnement ; si vous utilisez un environnement virtuel, sélectionnez-le parmi les options fournies.
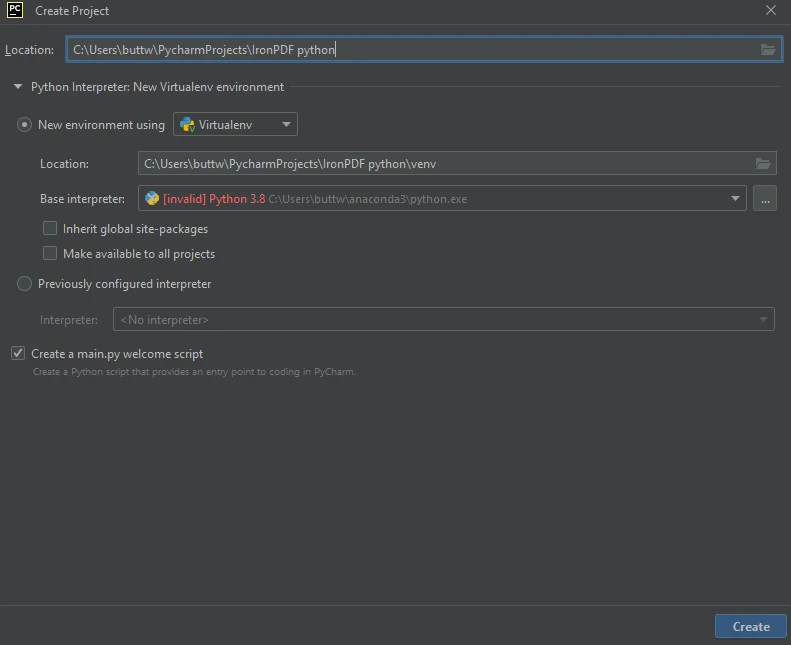 Créer un nouveau projet Python dans PyCharm
Créer un nouveau projet Python dans PyCharm - Une fois l'environnement sélectionné, cliquez sur le bouton Create pour créer votre projet Python.
Votre projet Python est maintenant créé et prêt à être utilisé pour diverses tâches, telles que l'extraction d'images.
Étape 2 Installation d'IronPDF
Pour installer IronPDF, ouvrez le terminal ou une invite de commandes séparée et entrez la commande pip install ironpdf, puis appuyez sur la touche Entrée . Le terminal affichera la sortie suivante.
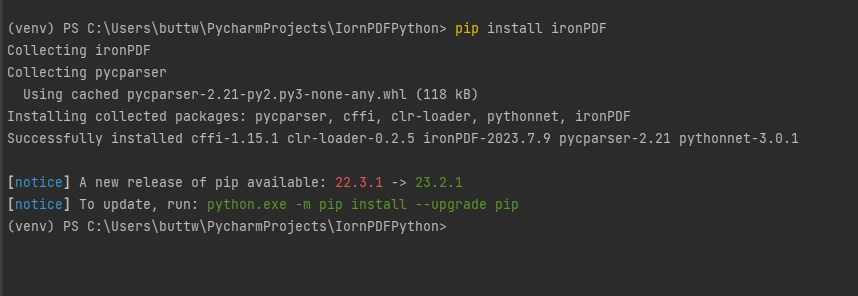 Installer le package IronPDF
Installer le package IronPDF
Étape 3 Extraction d'images à partir de fichiers PDF avec IronPDF
IronPDF donne les moyens aux développeurs avec des outils et des API pour naviguer dans les PDF et identifier et extraire des images intégrées sans effort. Que ce soit pour l'analyse ou l'intégration, IronPDF simplifie l'extraction en utilisant la flexibilité de Python. Cela en fait un élément essentiel pour travailler sur les PDF et les applications basées sur des images. Il peut extraire toutes les images d'un fichier PDF, ce qui est remarquablement simple avec seulement quelques lignes de code.
Voir le code suivant pour extraire des images d'un PDF en utilisant le langage de programmation Python.
from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")Ce code importe d'abord la bibliothèque IronPDF puis charge le fichier PDF depuis l'espace local en utilisant le chemin du fichier avec la méthode PdfDocument.FromFile. Il accède à chaque page du PDF pour extraire des octets image en tant qu'objets Image. Ces objets image provenant de pages PDF sont ensuite enregistrés à l'aide de la méthode SaveAs. Le code attribue des noms d'images dynamiques basés sur les indices d'images et l'extension de fichier d'image souhaitée, qui est PNG dans cet exemple.
Cette approche est plus simple que d'utiliser d'autres bibliothèques Python comme PyMuPDF et Pillow, qui nécessitent plus de code pour accomplir la même tâche d'extraction et de sauvegarde des fichiers d'image.
Étape 4 Sauvegarder les images du fichier PDF
Des images sont extraites de toutes les pages d'un fichier PDF et enregistrées au format PNG. Vous avez également la flexibilité de modifier le format de sortie en ajustant l'extension de fichier pour correspondre aux formats de fichiers d'image souhaités.
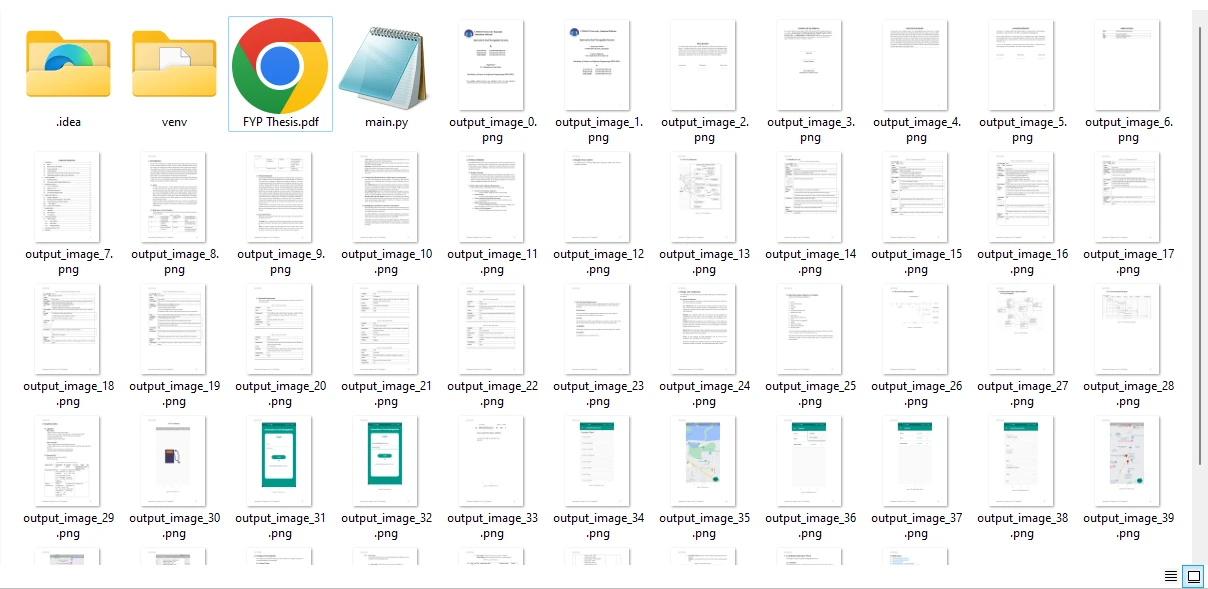 Les images extraites du fichier PDF d'exemple
Les images extraites du fichier PDF d'exemple
Conclusion
Python, associé au puissant IronPDF, offre une solution polyvalente et efficace pour la tâche de récupération d'images à partir de fichiers PDF. En tirant parti de la flexibilité de Python et des capacités d'IronPDF, les développeurs peuvent naviguer sans effort dans les documents PDF, localiser les octets d'image au sein de ceux-ci et enregistrer ces images avec l'extension d'image souhaitée. Le processus implique d'obtenir des images à partir d'un PDF, et la liste d'images résultante peut être traitée et manipulée davantage selon les besoins. En maîtrisant l'art d'acquérir des images à partir de PDF en utilisant Python, les développeurs peuvent améliorer leurs flux de travail, automatiser la gestion des documents et explorer une large gamme d'applications basées sur l'image, ce qui en fait une compétence précieuse à l'ère numérique.
Pour plus de fonctionnalités sur l'extraction d'images à partir de fichiers PDF, visitez l'exemple suivant. Vous pouvez explorer d'autres opérations comme la conversion du contenu de fichier PDF en images; le tutoriel complet est disponible dans cet article pratique en Python.
Questions Fréquemment Posées
Comment puis-je extraire des images d'un PDF en utilisant Python ?
Vous pouvez extraire des images d'un PDF en using IronPDF for Python en utilisant la méthode PdfDocument.FromFile pour charger un PDF et la méthode ExtractAllImages pour extraire les images.
Quelles sont les étapes pour sauvegarder les images extraites d'un PDF en utilisant Python ?
Pour sauvegarder les images extraites, itérez à travers les images et utilisez la méthode SaveAs pour enregistrer chaque image avec une extension de fichier spécifiée, telle que PNG.
Pourquoi choisir IronPDF pour l'extraction d'images de PDF en Python ?
IronPDF simplifie le processus d'extraction d'images comparé à d'autres bibliothèques comme PyMuPDF et Pillow, réduisant la quantité de code nécessaire pour obtenir des résultats similaires.
Quelles sont les exigences pour utiliser IronPDF en Python pour gérer les PDF ?
Vous devez disposer de Python 3.0 ou plus récent et installer la bibliothèque IronPDF via pip. Il est également avantageux d'utiliser un IDE comme PyCharm pour le développement.
Comment installer IronPDF for Python ?
IronPDF peut être installé en utilisant le Package Manager pip. Exécutez la commande pip install ironpdf dans votre interface de ligne de commande.
IronPDF peut-il être utilisé pour automatiser la gestion des documents PDF en Python ?
Oui, IronPDF permet l'automatisation des tâches de gestion de documents tels que l'extraction d'images et la conversion de contenus PDF, ce qui améliore l'efficacité du flux de travail.
Quels formats d'image sont pris en charge par IronPDF pour enregistrer les images extraites ?
Les images extraites peuvent être enregistrées dans des formats tels que PNG en spécifiant l'extension de fichier souhaitée dans la méthode SaveAs.
IronPDF est-il adapté au développement d'applications basées sur des images en Python ?
IronPDF est bien adapté pour le développement d'applications basées sur des images car il offre des fonctionnalités robustes pour extraire et gérer les images au sein des documents PDF.