
Como extrair imagens de um PDF em Python
Este artigo utilizará o IronPDF for Python para extrair imagens de um arquivo PDF usando código Python.
IronPDF for Python
IronPDF for Python é uma biblioteca poderosa e de ponta que traz uma nova dimensão ao manuseio de documentos PDF em Python. Como uma solução completa para tarefas com PDFs, o IronPDF permite a integração perfeita de recursos avançados de PDF em aplicativos.
O IronPDF oferece uma ampla gama de ferramentas e APIs para tarefas como criar PDFs do zero, converter HTML em PDFs de alta qualidade e gerenciar páginas de PDF por meio de ações como mesclar, dividir e editar. Essas ferramentas são fáceis de usar e eficientes. Com sua interface amigável e documentação abrangente, o IronPDF abre possibilidades para desenvolvedores.
Seja para criar relatórios e faturas profissionais, automatizar fluxos de trabalho ou gerenciar documentos, o IronPDF oferece um recurso valioso na área de gerenciamento e automação de documentos, tornando-se uma ferramenta essencial para qualquer desenvolvedor que busque aproveitar o poder dos PDFs em aplicações Python.
Como extrair imagens de um PDF usando o IronPDF for Python
- Instale a biblioteca IronPDF para extrair imagens de PDFs em Python.
- Use o método
PdfDocument.FromFilepara carregar um arquivo PDF usando um caminho de arquivo do disco local. - Aplique o método
ExtractAllImagespara extrair imagens de arquivos PDF. - Utilize um laço para percorrer todas as imagens extraídas encontradas no PDF.
- Salve essas imagens extraídas do arquivo PDF com a extensão de imagem desejada.
Pré-requisitos
Antes de mergulharmos no mundo da obtenção de imagens de PDFs usando Python, vamos instalar os pré-requisitos necessários:
- Instalação do Python: Certifique-se de ter um interpretador Python instalado em seu sistema. O processo de obtenção de imagens a partir de PDFs requer Python 3.0 ou versões mais recentes. Certifique-se de ter uma instalação do Python compatível.
-
Biblioteca IronPDF: Para utilizar as poderosas capacidades do IronPDF, você precisará instalá-lo usando
pip, o gerenciador de pacotes do Python. Basta abrir a interface de linha de comando e executar o seguinte comando:pip install ironpdf
- Ambiente de Desenvolvimento Integrado (IDE): Embora não seja obrigatório, o uso de um IDE pode melhorar muito sua experiência de desenvolvimento. As IDEs oferecem recursos como preenchimento automático de código, depuração e um fluxo de trabalho mais simplificado. Uma IDE muito popular para desenvolvimento em Python é o PyCharm. Você pode baixar e instalar o PyCharm no site da JetBrains .
Uma vez que esses pré-requisitos estejam atendidos, você poderá explorar o guia passo a passo pelo fascinante mundo da recuperação de imagens de PDFs usando Python e IronPDF.
Passo 1: Criando um novo projeto em Python
Aqui estão os passos para criar um novo projeto Python no PyCharm.
- Para iniciar um novo projeto Python no PyCharm, abra o aplicativo PyCharm e navegue até o menu superior.
-
Clique em Arquivo e selecione Novo Projeto no menu suspenso.
 IDE PyCharm
IDE PyCharm - Após clicar em Novo Projeto , uma nova janela com o título Criar Projeto será exibida.
-
Nesta janela, insira o nome do seu projeto no campo Localização , na parte superior. Escolha o ambiente; Se estiver utilizando um ambiente virtual, selecione-o dentre as opções fornecidas.
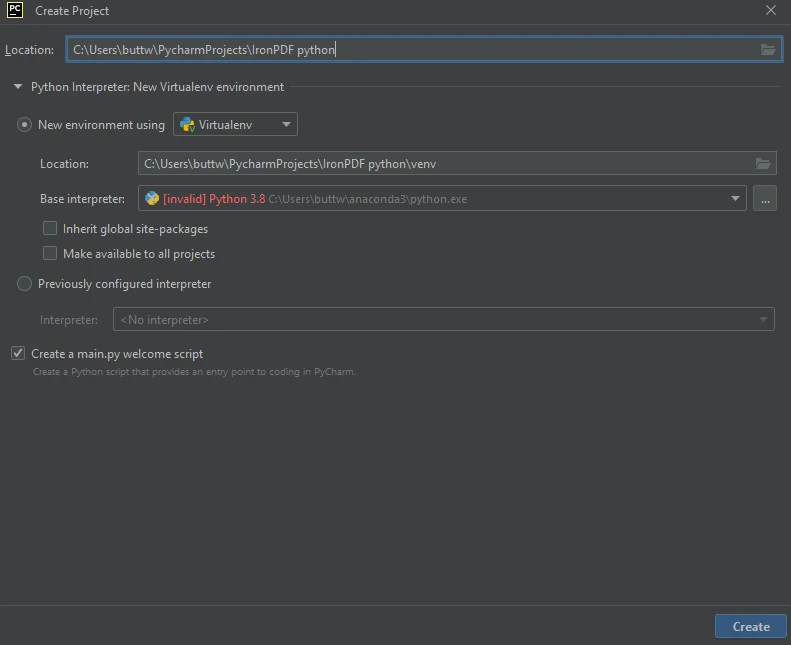 Crie um novo projeto Python no PyCharm.
Crie um novo projeto Python no PyCharm. - Depois de selecionar o ambiente, clique no botão Criar para criar seu projeto Python.
Seu projeto em Python foi criado e está pronto para ser usado em diversas tarefas, como extrair imagens.
Etapa 2: Instalando o IronPDF
Para instalar o IronPDF, abra o terminal ou um prompt de comando separado e insira o comando pip install ironpdf, em seguida, pressione a tecla Enter. O terminal exibirá a seguinte saída.
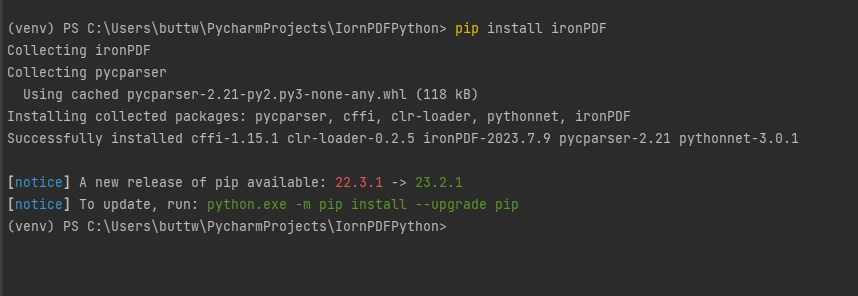 Instale o pacote IronPDF
Instale o pacote IronPDF
Etapa 3: Extraindo imagens de arquivos PDF usando o IronPDF
O IronPDF oferece aos desenvolvedores ferramentas e APIs para navegar em PDFs e identificar e extrair imagens incorporadas de forma integrada. Seja para análise ou integração, o IronPDF simplifica a extração usando a flexibilidade do Python. Isso o torna essencial para trabalhar com PDFs e aplicativos baseados em imagens. Ele consegue extrair todas as imagens de um arquivo PDF de forma surpreendentemente simples, com apenas algumas linhas de código.
Veja o código a seguir para extrair imagens de um PDF usando a linguagem de programação Python.
from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")Este código primeiro importa a biblioteca IronPDF e, em seguida, carrega o arquivo PDF do espaço local usando o caminho do arquivo com o método PdfDocument.FromFile. Ele acessa cada página do PDF para extrair bytes de imagem como objetos Image. Esses objetos de imagem das páginas do PDF são então salvos usando o método SaveAs. O código atribui nomes de imagem dinâmicos com base nos índices da imagem e na extensão de arquivo de imagem desejada, que neste exemplo é PNG.
Essa abordagem é mais simples do que usar outras bibliotecas Python como PyMuPDF e Pillow , que exigem mais código para realizar a mesma tarefa de extrair e salvar arquivos de imagem.
Passo 4: Salve as imagens do arquivo PDF.
As imagens são extraídas de todas as páginas de um arquivo PDF e salvas no formato PNG. Você também tem a flexibilidade de modificar o formato de saída ajustando a extensão do arquivo para corresponder aos formatos de arquivo de imagem desejados.
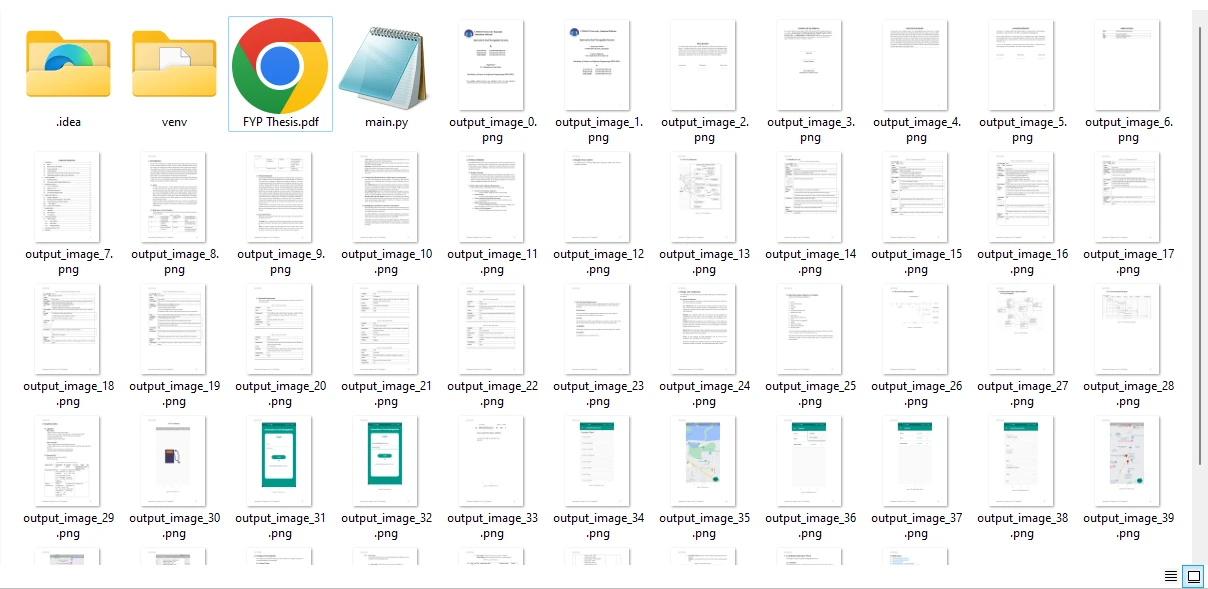 As imagens extraídas do arquivo PDF de amostra
As imagens extraídas do arquivo PDF de amostra
Conclusão
O Python, juntamente com a poderosa IronPDF , oferece uma solução versátil e eficiente para a tarefa de recuperar imagens de arquivos PDF. Aproveitando a flexibilidade do Python e os recursos do IronPDF, os desenvolvedores podem navegar facilmente por documentos PDF, localizar bytes de imagem dentro deles e salvar essas imagens com a extensão desejada. O processo envolve a obtenção de imagens a partir de um PDF, e a lista de imagens resultante pode ser posteriormente processada e manipulada conforme necessário. Ao dominar a arte de extrair imagens de PDFs usando Python, os desenvolvedores podem aprimorar seus fluxos de trabalho, automatizar o gerenciamento de documentos e explorar uma ampla gama de aplicações baseadas em imagens, tornando-se uma habilidade valiosa na era digital.
Para obter mais informações sobre como extrair imagens de arquivos PDF, visite o exemplo a seguir. Você pode explorar outras operações, como converter o conteúdo de arquivos PDF em imagens; O tutorial completo está disponível neste artigo sobre como programar em Python .
Perguntas frequentes
Como posso extrair imagens de um PDF usando Python?
Você pode extrair imagens de um PDF usando o IronPDF for Python, utilizando o método PdfDocument.FromFile para carregar o PDF e o método ExtractAllImages para extrair as imagens.
Quais são os passos para salvar imagens extraídas de um PDF usando Python?
Para salvar as imagens extraídas, percorra as imagens e use o método SaveAs para armazenar cada imagem com uma extensão de arquivo específica, como PNG.
Por que escolher o IronPDF para extrair imagens de PDFs em Python?
O IronPDF simplifica o processo de extração de imagens em comparação com outras bibliotecas como PyMuPDF e Pillow, reduzindo a quantidade de código necessária para obter resultados semelhantes.
Quais são os requisitos para usar o IronPDF em Python para manipular PDFs?
Você precisa ter o Python 3.0 ou mais recente e instalar a biblioteca IronPDF via pip. Também é recomendável usar uma IDE como o PyCharm para o desenvolvimento.
Como instalo o IronPDF for Python?
O IronPDF pode ser instalado usando o gerenciador de pacotes pip. Execute o comando pip install ironpdf na sua interface de linha de comando.
O IronPDF pode ser usado para automatizar o gerenciamento de documentos PDF em Python?
Sim, o IronPDF permite a automatização de tarefas de gestão documental, como a extração de imagens e a conversão de conteúdo de PDFs, o que aumenta a eficiência do fluxo de trabalho.
Quais formatos de imagem são suportados pelo IronPDF para salvar imagens extraídas?
As imagens extraídas podem ser salvas em formatos como PNG, especificando a extensão de arquivo desejada no método SaveAs .
O IronPDF é adequado para o desenvolvimento de aplicações baseadas em imagens em Python?
O IronPDF é ideal para o desenvolvimento de aplicações baseadas em imagens, pois oferece recursos robustos para extrair e gerenciar imagens em documentos PDF.
















