Scrapy em Python (Como funciona para desenvolvedores)
Eficácia e eficiência são cruciais nas áreas de extração de dados online e geração de documentos. A integração perfeita de ferramentas e estruturas robustas é necessária para extrair dados de sites e convertê-los posteriormente em documentos de qualidade profissional.
Apresentamos o Scrapy, um framework de web scraping em Python, e o IronPDF, duas bibliotecas formidáveis que trabalham em conjunto para otimizar a extração de dados online e a criação de PDFs dinâmicos.
Graças ao Scrapy em Python, uma das principais bibliotecas de web crawling e scraping, os desenvolvedores agora podem navegar sem esforço pela complexidade da web e extrair dados estruturados com rapidez e precisão. Com seus robustos seletores XPath e CSS e arquitetura assíncrona, é a opção ideal para tarefas de extração de dados de qualquer complexidade.
Por outro lado, o IronPDF é uma poderosa biblioteca .NET que oferece suporte à criação, edição e manipulação programática de documentos PDF. O IronPDF oferece aos desenvolvedores uma solução completa para produzir documentos PDF dinâmicos e visualmente atraentes, com suas poderosas ferramentas de criação de PDF, que incluem conversão de HTML para PDF e recursos de edição de PDF.
Este artigo irá guiá-lo por uma jornada através da integração perfeita do Scrapy Python com o IronPDF e mostrar como essa dupla dinâmica transforma a maneira como a extração de dados da web e a criação de documentos são feitas. Mostraremos como essas duas bibliotecas trabalham juntas para facilitar tarefas complexas e acelerar os fluxos de trabalho de desenvolvimento, desde a extração de dados da web com o Scrapy até a geração dinâmica de relatórios em PDF com o IronPDF.
Venha explorar as possibilidades de web scraping e geração de documentos enquanto usamos o IronPDF para aproveitar ao máximo o Scrapy.

Arquitetura Assíncrona
A arquitetura assíncrona utilizada pelo Scrapy permite o processamento de várias requisições simultaneamente. Isso resulta em maior eficiência e velocidades de extração de dados da web mais rápidas, especialmente ao trabalhar com sites complexos ou grandes quantidades de dados.
Gestão robusta de rastejamento
O Scrapy possui recursos robustos de gerenciamento do processo de rastreamento, como filtragem automática de URLs, agendamento configurável de requisições e tratamento integrado de diretivas no arquivo robots.txt. O comportamento de rastreamento pode ser ajustado pelos desenvolvedores para atender às suas próprias necessidades e garantir a conformidade com as diretrizes do site.
Seletores para XPath e CSS
O Scrapy permite que os usuários naveguem e selecionem itens em páginas HTML usando seletores XPath e seletores CSS. Essa adaptabilidade torna a extração de dados mais precisa e confiável, permitindo que os desenvolvedores identifiquem com exatidão elementos ou padrões específicos em uma página da web.
Pipeline de itens
Os desenvolvedores podem especificar componentes reutilizáveis para processar os dados extraídos antes de exportá-los ou armazená-los usando o pipeline de itens do Scrapy. Ao realizar operações como limpeza, validação, transformação e desduplicação, os desenvolvedores podem garantir a precisão e a consistência dos dados extraídos.
Middleware integrado
Diversos componentes de middleware pré-instalados no Scrapy oferecem recursos como gerenciamento automático de cookies, limitação de requisições, rotação de user-agent e rotação de proxy. Esses elementos intermediários são facilmente configuráveis e personalizáveis para melhorar a eficiência da extração de dados e solucionar problemas comuns.
Arquitetura extensível
Ao criar middleware, extensões e pipelines personalizados, os desenvolvedores podem personalizar e expandir ainda mais os recursos do Scrapy graças à sua arquitetura modular e extensível. Devido à sua adaptabilidade, os desenvolvedores podem facilmente incluir o Scrapy em seus processos atuais e modificá-lo para atender às suas necessidades específicas de extração de dados.
Criar e configurar o Scrapy em Python
Instale o Scrapy
Instale o Scrapy usando o pip executando o seguinte comando:
pip install scrapypip install scrapyDefina uma aranha
Para definir sua spider, crie um novo arquivo Python (como example.py) no diretório spiders/. Segue abaixo uma ilustração de um spider básico que extrai dados de uma URL:
import scrapy
class QuotesSpider(scrapy.Spider):
# Name of the spider
name = 'quotes'
# Starting URL
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
# Iterate through each quote block in the response
for quote in response.css('div.quote'):
# Extract and yield quote details
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
# Identify and follow the next page link
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)import scrapy
class QuotesSpider(scrapy.Spider):
# Name of the spider
name = 'quotes'
# Starting URL
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
# Iterate through each quote block in the response
for quote in response.css('div.quote'):
# Extract and yield quote details
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
# Identify and follow the next page link
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)Configurar configurações
Para configurar os parâmetros do projeto Scrapy, como user-agent, atrasos de download e pipelines, edite o arquivo settings.py. Esta é uma ilustração de como mudar o user-agent e fazer os pipelines funcionarem:
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Set user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# Configure pipelines
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Set user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# Configure pipelines
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}Começando
Para começar a usar Scrapy e IronPDF, é necessário combinar os recursos robustos de web scraping do Scrapy com as funcionalidades dinâmicas de produção de PDFs do IronPDF. A seguir, explicarei passo a passo como configurar um projeto Scrapy para que você possa extrair dados de sites e usar o IronPDF para criar um documento PDF contendo esses dados.
O que é o IronPDF?
IronPDF é uma poderosa biblioteca .NET para criar, editar e alterar documentos PDF programaticamente em C#, VB .NET e outras linguagens .NET . Por oferecer aos desenvolvedores um amplo conjunto de recursos para a criação dinâmica de PDFs de alta qualidade, é uma escolha popular para muitos programas.
Funcionalidades do IronPDF
Geração de PDFs: Usando o IronPDF, os programadores podem criar novos documentos PDF ou converter elementos HTML existentes, como tags, texto, imagens e outros formatos de arquivo, em PDFs. Essa funcionalidade é muito útil para criar relatórios, faturas, recibos e outros documentos de forma dinâmica.
Conversão de HTML para PDF: O IronPDF facilita para os desenvolvedores a transformação de documentos HTML, incluindo estilos de JavaScript e CSS, em arquivos PDF. Isso permite a criação de PDFs a partir de páginas da web, conteúdo gerado dinamicamente e modelos HTML.
Modificação e edição de documentos PDF: O IronPDF oferece um conjunto abrangente de funcionalidades para modificar e alterar documentos PDF preexistentes. Os desenvolvedores podem mesclar vários arquivos PDF, separá-los em documentos distintos, remover páginas e adicionar marcadores, anotações e marcas d'água, entre outros recursos, para personalizar os PDFs de acordo com suas necessidades.
Como instalar o IronPDF
Após certificar-se de que o Python está instalado em seu computador, use o pip para instalar o IronPDF.
pip install ironpdf
Projeto Scrapy com IronPDF
Para definir sua spider, crie um novo arquivo Python (como example.py) no diretório da spider do seu projeto Scrapy (myproject/myproject/spiders). Um exemplo de código de um spider básico que extrai citações de uma URL:
import scrapy
from IronPdf import *
class QuotesSpider(scrapy.Spider):
name = 'quotes'
# Web page link
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quotes = []
for quote in response.css('div.quote'):
title = quote.css('span.text::text').get()
content = quote.css('span small.author::text').get()
quotes.append((title, content)) # Append quote to list
# Generate PDF document using IronPDF
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(self.get_pdf_content(quotes))
pdf.SaveAs("quotes.pdf")
def get_pdf_content(self, quotes):
# Generate HTML content for PDF using extracted quotes
html_content = "<html><head><title>Quotes</title></head><body>"
for title, content in quotes:
html_content += f"<h2>{title}</h2><p>Author: {content}</p>"
html_content += "</body></html>"
return html_contentimport scrapy
from IronPdf import *
class QuotesSpider(scrapy.Spider):
name = 'quotes'
# Web page link
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quotes = []
for quote in response.css('div.quote'):
title = quote.css('span.text::text').get()
content = quote.css('span small.author::text').get()
quotes.append((title, content)) # Append quote to list
# Generate PDF document using IronPDF
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(self.get_pdf_content(quotes))
pdf.SaveAs("quotes.pdf")
def get_pdf_content(self, quotes):
# Generate HTML content for PDF using extracted quotes
html_content = "<html><head><title>Quotes</title></head><body>"
for title, content in quotes:
html_content += f"<h2>{title}</h2><p>Author: {content}</p>"
html_content += "</body></html>"
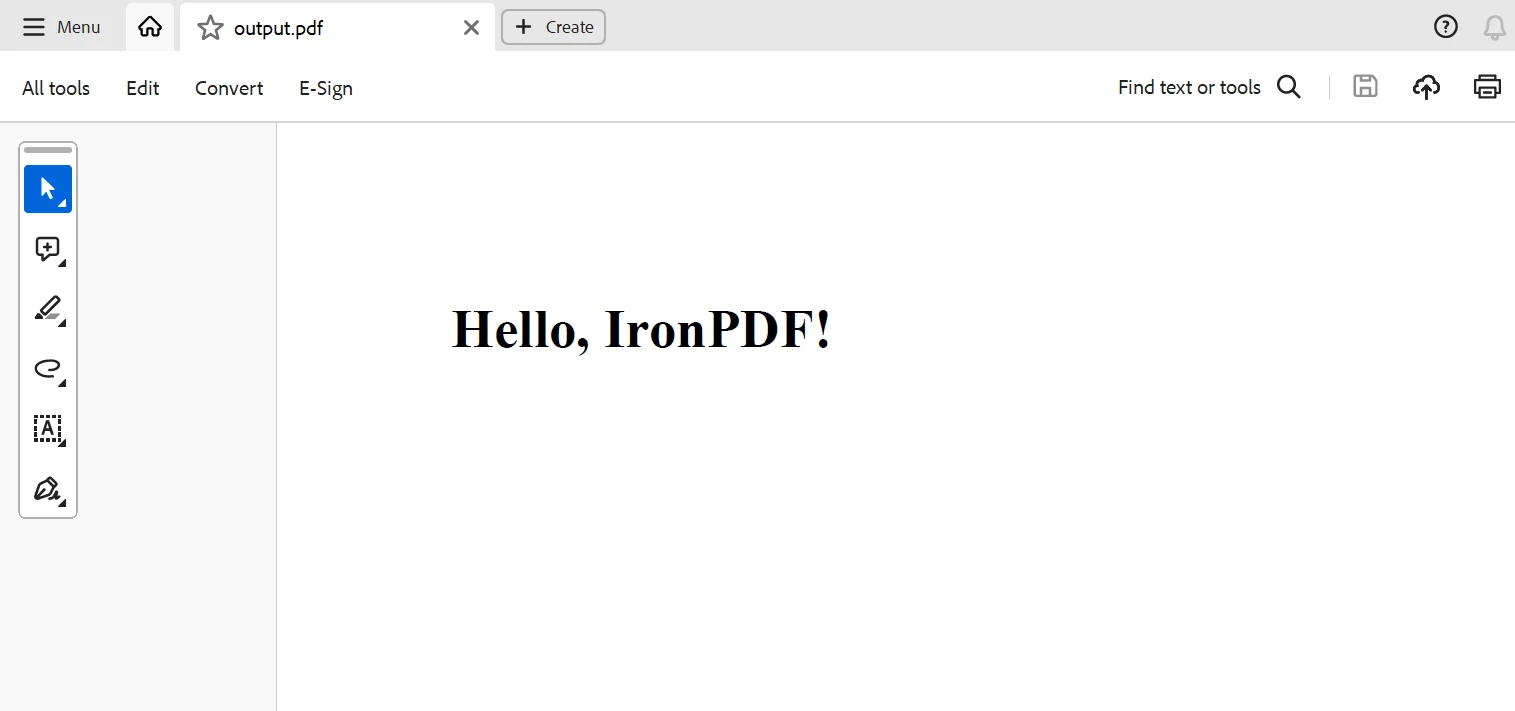
return html_contentNo exemplo de código acima, de um projeto Scrapy com IronPDF, o IronPDF está sendo usado para criar um documento PDF utilizando os dados extraídos pelo Scrapy.
Aqui, o método parse da spider coleta citações da página web e usa a função get_pdf_content para criar o conteúdo HTML para o arquivo PDF. Este material HTML é posteriormente renderizado como um documento PDF usando IronPDF e salvo como quotes.pdf.
Conclusão
Em resumo, a combinação de Scrapy e IronPDF oferece aos desenvolvedores uma opção robusta para automatizar atividades de web scraping e gerar documentos PDF instantaneamente. Os recursos flexíveis de produção de PDF do IronPDF, juntamente com as poderosas capacidades de rastreamento e extração de dados da web do Scrapy, proporcionam um processo tranquilo para coletar dados estruturados de qualquer página da web e transformar os dados extraídos em relatórios, faturas ou documentos em PDF com qualidade profissional.
Por meio da utilização do Scrapy Spider em Python, os desenvolvedores podem navegar com eficiência pelas complexidades da internet, recuperar informações de diversas fontes e organizá-las de forma sistemática. A estrutura flexível do Scrapy, sua arquitetura assíncrona e o suporte para seletores XPath e CSS proporcionam a flexibilidade e a escalabilidade necessárias para gerenciar uma variedade de atividades de web scraping.
A licença vitalícia está incluída no IronPDF, que tem um preço bastante razoável quando adquirido em pacote. Excelente valor é fornecido pelo pacote, que custa apenas $999 (uma compra única para vários sistemas). Quem possui licença tem acesso a suporte técnico online 24 horas por dia, 7 dias por semana. Para obter mais detalhes sobre a taxa, acesse o site . Visite esta página para saber mais sobre os produtos da Iron Software.
Perguntas frequentes
Como posso integrar o Scrapy com uma ferramenta de geração de PDF?
Você pode integrar o Scrapy com uma ferramenta de geração de PDF como o IronPDF, usando primeiro o Scrapy para extrair dados estruturados de sites e, em seguida, empregando o IronPDF para converter esses dados em documentos PDF dinâmicos.
Qual a melhor maneira de extrair dados e convertê-los em um PDF?
A melhor maneira de extrair dados e convertê-los em PDF é usando o Scrapy para extrair os dados de forma eficiente e o IronPDF para gerar um PDF de alta qualidade a partir do conteúdo extraído.
Como posso converter HTML para PDF em Python?
Embora o IronPDF seja uma biblioteca .NET, você pode usá-lo com Python por meio de soluções de interoperabilidade como o Python.NET para converter HTML em PDF usando os métodos de conversão do IronPDF.
Quais são as vantagens de usar o Scrapy para extração de dados da web?
O Scrapy oferece vantagens como processamento assíncrono, seletores XPath e CSS robustos e middleware personalizável, que simplificam o processo de extração de dados de sites complexos.
Posso automatizar a criação de PDFs a partir de dados da web?
Sim, você pode automatizar a criação de PDFs a partir de dados da web integrando o Scrapy para extração de dados e o IronPDF para geração de PDFs, permitindo um fluxo de trabalho contínuo desde a extração até a criação do documento.
Qual é o papel do middleware no Scrapy?
O middleware no Scrapy permite controlar e personalizar o processamento de solicitações e respostas, possibilitando recursos como filtragem automática de URLs e rotação de user-agents para aumentar a eficiência da extração de dados.
Como você define uma aranha no Scrapy?
Para definir um spider no Scrapy, crie um novo arquivo Python no diretório spiders do seu projeto e implemente uma classe que estenda scrapy.Spider com métodos como parse para lidar com a extração de dados.
O que torna o IronPDF uma escolha adequada para geração de PDFs?
O IronPDF é uma escolha adequada para geração de PDFs, pois oferece recursos abrangentes para conversão de HTML para PDF, criação dinâmica de PDFs, edição e manipulação, tornando-o versátil para diversas necessidades de geração de documentos.
Como posso aprimorar a extração de dados da web e a criação de PDFs?
Aprimore a extração de dados da web e a criação de PDFs usando o Scrapy para uma extração de dados eficiente e o IronPDF para converter os dados extraídos em documentos PDF com formatação profissional.