Python'da Scrapy (Geliştiriciler İçin Nasıl Çalışır)
Çevrimiçi veri toplama ve belge oluşturma alanlarında etkinlik ve verimlilik kritik öneme sahiptir. Öğeleri web sitelerinden çıkartmak ve profesyonel standartlarda belgelere dönüştürmek için güçlü araçların ve çerçevelerin sorunsuz bir entegrasyonu gereklidir.
İşte Scrapy, bir Python web scraping çerçevesi ve IronPDF geliyor, çevrimiçi verileri toplamak ve dinamik PDFler oluşturmak için birlikte çalışan iki güçlü kütüphane.
Geliştiriciler, Python'daki Scrapy sayesinde karmaşık web dünyasında zahmetsizce gezinebilir ve hızla hassas ve hızlı bir şekilde yapılandırılmış verileri çıkartabilirler, bu da üst web tarama ve scraping kitaplıklarından biridir. Güçlü XPath ve CSS seçicileri ve asenkron mimarisi ile, her türlü karmaşıklıkta scraping işleri için ideal bir seçenektir.
Öte yandan, IronPDF, .NET kütüphanesi güçlü bir olup, PDF belgelerinin programlı bir şekilde oluşturulmasını, düzenlenmesini ve manipüle edilmesini destekler. IronPDF, HTML'den PDF'ye dönüşüm ve PDF düzenleme yetenekleri dahil olmak üzere dinamik ve estetik açıdan hoş PDF belgeleri oluşturmak için geliştiricilere tam bir çözüm sunar.
Bu gönderi, Scrapy Python ile IronPDF'in sorunsuz entegrasyonunu gözden geçirmenizi sağlayacak ve bu dinamik çiftin web scraping ve belge oluşturma şeklini nasıl dönüştürdüğünü gösterecektir. Burada, Scrapy ile web'deki verileri çıkartmaktan IronPDF ile dinamik olarak PDF raporları oluşturmaya kadar, bu iki kütüphanenin karmaşık görevleri nasıl kolaylaştırdığını ve gelişim akışlarını nasıl hızlandırdığını göstereceğiz.
Hadi gelin IronPDF'i kullanarak Scrapy'nin potansiyelini tam olarak kullanırken web scraping ve belge oluşturmanın olanaklarını keşfedelim.

Asenkron Mimari
Scrapy'nin asenkron mimarisi, birden fazla isteği aynı anda işlemesine olanak tanır. Bu, verimliliği artırır ve karmaşık web siteleri veya büyük miktarda verilerle çalışırken daha hızlı web scraping hızlarına yol açar.
Dayanıklı Tarama Yönetimi
Scrapy, URL otomatik filtreleme, yapılandırılabilir istek planlaması ve entegre robots.txt yönetimi gibi güçlü tarama yönetim özelliklerine sahiptir. Geliştiriciler, tarama davranışını kendi ihtiyaçlarına uyacak şekilde ayarlayabilir ve web sitesi yönergelerine uyumu garanti edebilir.
XPath ve CSS İçin Seçiciler
Scrapy, kullanıcıların HTML sayfaları içindeki öğeleri seçmelerine olanak tanır ve XPath ve CSS seçiciler için seçici kullanır. Bu esneklik, geliştiricilerin bir web sayfasında belirli öğeleri veya desenleri tam hedefleyebilmesini sağlayarak veri çıkarımını daha doğru ve güvenilir hale getirir.
Öğe Boru Hattı
Scrapy'nin item pipeline'ı sayesinde, geliştiriciler çıkartılan verileri ihraç etmeden veya depolamadan önce işlemeye yönelik yeniden kullanılabilir bileşenler belirleyebilir. Temizlik, doğrulama, dönüştürme ve başkalarını tekrar etmeme gibi operasyonlar gerçekleştirilerek, geliştiriciler çıkarılan verilerin doğruluğunu ve tutarlılığını garantileyebilir.
Yerleşik Ara Katman Yazılımı
Scrapy'de önceden yüklenmiş olan bir dizi yazılım bileşeni, otomatik çerez yönetimi, istek kısıtlama, kullanıcı aracısı rotasyonu ve vekil rotasyonu gibi işlevler sunar. Bu yazılım bileşenleri kolayca yapılandırılıp özelleştirilebilir, scraping verimliliğini artırır ve genel sorunları çözer.
Genişletilebilir Mimari
Geliştiriciler, özelleştirilmiş yazılım bileşenleri, eklentiler ve hatlar oluşturmak suretiyle Scrapy'nin yeteneklerini daha da kişiselleştirip genişletebilirler. Modüler ve genişletilebilir mimarisi sayesinde. Uyarlanabilirliği sayesinde, geliştiriciler Scrapy'yi mevcut süreçlerine kolayca dahil edebilir ve belirli scraping ihtiyaçlarına göre uyarlayabilirler.
Python'da Scrapy Oluştur ve Ayarla
Scrapy Yükleme
pip kullanarak Scrapy kurun, aşağıdaki komutu çalıştırarak:
pip install scrapypip install scrapyBir Örümcek Tanımlayın
Örümceğinizi tanımlamak için example.py gibi yeni bir Python dosyası spiders/ dizininde oluşturun. Bir URL'den çıkartma yapan basit bir örümcek örneği burada sağlanmıştır:
import scrapy
class QuotesSpider(scrapy.Spider):
# Name of the spider
name = 'quotes'
# Starting URL
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
# Iterate through each quote block in the response
for quote in response.css('div.quote'):
# Extract and yield quote details
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
# Identify and follow the next page link
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)import scrapy
class QuotesSpider(scrapy.Spider):
# Name of the spider
name = 'quotes'
# Starting URL
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
# Iterate through each quote block in the response
for quote in response.css('div.quote'):
# Extract and yield quote details
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
# Identify and follow the next page link
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)Ayarları Yapılandır
Kullanıcı ajanı, indirme gecikmeleri ve ardışık düzenler gibi Scrapy proje parametrelerini ayarlamak için settings.py dosyasını düzenleyin. Bu, kullanıcı ajanını nasıl değiştireceğiniz ve ardışık düzenleri nasıl işlevsel hale getireceğinizin bir gösterimidir:
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Set user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# Configure pipelines
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Set user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# Configure pipelines
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}Başlarken
Scrapy ve IronPDF ile başlamak, Scrapy'nin güçlü web scraping yeteneklerini IronPDF'in dinamik PDF üretim özellikleriyle birleştirmeyi gerektirir. Aşağıda, web sitelerinden veri çıkartıp IronPDF kullanarak bu verileri içeren bir PDF belgesi yaratabilmeniz için bir Scrapy projesi kurma adımlarını anlatacağım.
IronPDF Nedir?
IronPDF, C#, VB.NET ve diğer .NET dillerinde programlı olarak PDF belgeleri oluşturmak, düzenlemek ve değiştirmek için güçlü bir .NET kütüphanesidir. Geliştiricilere yüksek kaliteli PDF'leri dinamik olarak oluşturma için geniş bir fırsat seti sunduğundan, birçok program için popüler bir seçimdir.
IronPDF Özellikleri
PDF Oluşturma: IronPDF kullanarak, programcılar yeni PDF belgeleri yaratabilir ya da mevcut HTML öğeleri, etiketler, metinler, resimler ve diğer dosya formatlarının PDF'lere dönüştürülmesini sağlayabilir. Bu özellik, raporlar, faturalar, makbuzlar ve diğer belgeleri dinamik olarak oluşturmak için çok kullanışlıdır.
HTML'den PDF'ye Dönüşüm: IronPDF, geliştiricilerin JavaScript ve CSS'ten gelen stiller de dahil olmak üzere HTML belgelerini PDF dosyalarına kolayca dönüştürmesini sağlar. Bu, web sayfalarından, dinamik olarak üretilen içerikten ve HTML şablonlarından PDF oluşturulmasını sağlar.
PDF Belgelerinin Düzenleme ve Değiştirilmesi: IronPDF, mevcut PDF belgelerinin düzenlenmesi ve değiştirilmesi için kapsamlı bir fonksiyon seti sunar. Geliştiriciler, PDF'leri kendi ihtiyaçlarına göre özelleştirmek için birçok PDF dosyasını birleştirebilir, ayrı belgelere ayırabilir, sayfaları kaldırabilir, yer imleri, açıklamalar ve filigranlar gibi unsurlar ekleyebilir.
IronPDF Nasıl Yüklenir
Python'un bilgisayarınıza yüklü olduğundan emin olduktan sonra, pip kullanarak IronPDF'i yükleyin.
pip install ironpdf
IronPDF ile Scrapy Projesi
Örümceğinizi tanımlamak için Scrapy projenizin (myproject/myproject/spiders) örümcek dizininde example.py gibi yeni bir Python dosyası oluşturun. URL'den alıntılar çıkartan basit bir örümcek kod örneği:
import scrapy
from IronPdf import *
class QuotesSpider(scrapy.Spider):
name = 'quotes'
# Web page link
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quotes = []
for quote in response.css('div.quote'):
title = quote.css('span.text::text').get()
content = quote.css('span small.author::text').get()
quotes.append((title, content)) # Append quote to list
# Generate PDF document using IronPDF
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(self.get_pdf_content(quotes))
pdf.SaveAs("quotes.pdf")
def get_pdf_content(self, quotes):
# Generate HTML content for PDF using extracted quotes
html_content = "<html><head><title>Quotes</title></head><body>"
for title, content in quotes:
html_content += f"<h2>{title}</h2><p>Author: {content}</p>"
html_content += "</body></html>"
return html_contentimport scrapy
from IronPdf import *
class QuotesSpider(scrapy.Spider):
name = 'quotes'
# Web page link
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quotes = []
for quote in response.css('div.quote'):
title = quote.css('span.text::text').get()
content = quote.css('span small.author::text').get()
quotes.append((title, content)) # Append quote to list
# Generate PDF document using IronPDF
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(self.get_pdf_content(quotes))
pdf.SaveAs("quotes.pdf")
def get_pdf_content(self, quotes):
# Generate HTML content for PDF using extracted quotes
html_content = "<html><head><title>Quotes</title></head><body>"
for title, content in quotes:
html_content += f"<h2>{title}</h2><p>Author: {content}</p>"
html_content += "</body></html>"
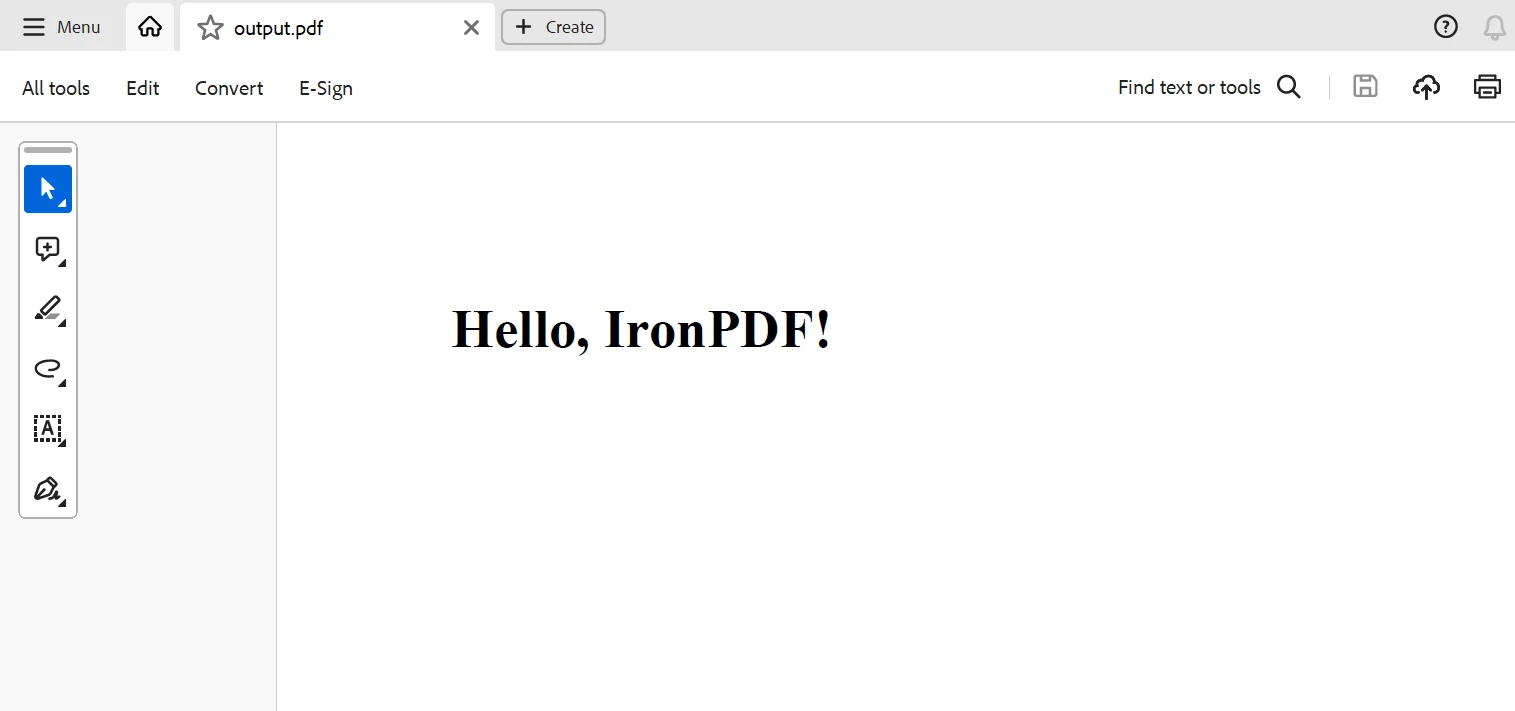
return html_contentIronPDF ile bir Scrapy projesinin yukarıdaki kod örneğinde, IronPDF çıkartılan veriyi kullanarak bir PDF belgesi oluşturmak için kullanılıyor.
Burada, örümceğin parse metodu web sayfasından alıntılar toplar ve HTML içeriğini PDF dosyası için oluşturmak amacıyla get_pdf_content fonksiyonunu kullanır. Bu HTML materyali daha sonra IronPDF kullanılarak PDF belgesi olarak işlenir ve quotes.pdf olarak kaydedilir.
Sonuç
Özetlemek gerekirse, Scrapy ve IronPDF kombinasyonu, geliştiricilere web scraping işlemlerini otomatikleştirmek ve anında PDF belgeleri üretmek için güçlü bir seçenek sunar. IronPDF'in esnek PDF üretim özellikleri, Scrapy'nin güçlü web gezme ve scraping yetenekleri ile birlikte, herhangi bir web sayfasından yapılandırılmış veri toplamak ve çıkarılan verileri profesyonel kaliteye sahip PDF raporlarına, faturalara veya belgelere dönüştürmek için sorunsuz bir süreç sunar.
Scrapy Spider Python'un kullanılmasıyla, geliştiriciler internetin karmaşıklıklarında etkili bir şekilde dolaşabilir, birçok kaynaktan bilgi toplayabilir ve bunu düzenli bir şekilde düzenleyebilirler. Scrapy'nin esnek çerçevesi, asenkron mimarisi ve XPath ve CSS seçici desteği, ona her türlü web scraping etkinliğini yönetmek için gerekli esnekliği ve ölçeklenebilirliği sağlar.
IronPDF, bir paket halinde satın alındığında oldukça makul bir fiyata ömür boyu bir lisans içerir. Bu paket mükemmel bir değer sunar ve sadece $999 maliyetindedir (birkaç sistem için bir kerelik satın alma). Lisanslı olanlar, çevrimiçi teknik desteğe 7/24 erişebilir. Ücretle ilgili daha fazla ayrıntı için lütfen web sitesini ziyaret edin. Iron Software'ın ürünleri hakkında daha fazla bilgi almak için bu sayfayı ziyaret edin.
Sıkça Sorulan Sorular
Scrapy'yi bir PDF oluşturma aracı ile nasıl entegre edebilirim?
Scrapy'yi bir PDF oluşturma aracı olan IronPDF ile entegre edebilirsiniz. İlk olarak, Scrapy'yi web sitelerinden yapılandırılmış veri çıkarmak için kullanın ve ardından IronPDF'yi kullanarak bu verileri dinamik PDF belgelerine dönüştürün.
Veri kazıma ve bunu bir PDF'ye dönüştürmenin en iyi yolu nedir?
Veri kazıma işlemi ve bunu bir PDF'ye dönüştürmenin en iyi yolu, verileri etkin bir şekilde çıkarmak için Scrapy ve çıkarılan içerikten yüksek kaliteli PDF üretmek için IronPDF kullanmaktır.
Python'da HTML'yi PDF'e nasıl dönüştürebilirim?
IronPDF bir .NET kütüphanesi olmasına rağmen, Python.NET gibi birlikte çalışabilirlik çözümleri aracılığıyla Python ile kullanılabilir ve IronPDF'nin dönüşüm yöntemlerini kullanarak HTML'yi PDF'ye dönüştürebilirsiniz.
Scrapy kullanmanın web kazıma için avantajları nelerdir?
Scrapy, eşzamansız işleme, sağlam XPath ve CSS seçicileri ve özelleştirilebilir ara katman gibi avantajlar sunarak karmaşık web sitelerinden veri çıkarma sürecini hızlandırır.
Web verilerinden PDF oluşturmayı otomatik hale getirebilir miyim?
Evet, web verilerinden PDF oluşturmayı Scrapy ile veri çıkarmayı ve PDF oluşturmada IronPDF'yi entegre ederek otomatikleştirebilirsiniz. Bu, kazımadan belge oluşturmaya kesintisiz bir iş akışı sağlar.
Scrapy'de ara katmanın rolü nedir?
Scrapy'deki ara katman, istek ve yanıtları kontrol etmeye ve özelleştirmeye olanak tanır, böylelikle otomatik URL filtreleme ve kullanıcı ajanı rotasyonu gibi özelliklerle kazıma verimliliğini artırır.
Scrapy'de bir örümcek nasıl tanımlanır?
Scrapy'de bir örümcek tanımlamak için, projenizin örümcekler dizininde yeni bir Python dosyası oluşturun ve veri çıkarma işlemlerini yönetmek için scrapy.Spider sınıfını uzatarak bir sınıf uygulayın.
IronPDF'yi PDF oluşturma için uygun yapan şey nedir?
IronPDF, HTML'den PDF'ye dönüştürme, dinamik PDF oluşturma, düzenleme ve manipülasyon için kapsamlı özellikler sunduğu için PDF oluşturma için uygun bir seçimdir. Bu, çeşitli belge oluşturma ihtiyaçları için çok yönlü olmasını sağlar.
Web veri çıkarma ve PDF oluşturmayı nasıl geliştirebilirim?
Web veri çıkarma ve PDF oluşturma işlemlerini geliştirmek için, verileri etkin bir şekilde kazımak için Scrapy ve çıkarılan verileri profesyonel olarak biçimlendirilmiş PDF belgelerine dönüştürmek için IronPDF kullanın.