Scrapy en Python (Comment ça marche pour les développeurs)
L'efficacité et l'efficience sont essentielles dans les domaines de l'extraction en ligne et de la génération de documents. Une intégration fluide d'outils et de frameworks puissants est nécessaire pour extraire des données de sites web et leur conversion subséquente en documents de calibre professionnel.
Voici Scrapy, un framework d'extraction web en Python, et IronPDF, deux bibliothèques formidables qui fonctionnent ensemble pour optimiser l'extraction de données en ligne et la création de PDF dynamiques.
Les développeurs peuvent désormais parcourir sans effort le web complexe et extraire rapidement des données structurées avec précision et rapidité grâce à Scrapy en Python, une bibliothèque de premier plan pour le crawling et l'extraction web. Avec ses sélecteurs puissants XPath et CSS et son architecture asynchrone, c'est l'option idéale pour les tâches d'extraction de toute complexité.
À l'inverse, IronPDF est une puissante bibliothèque .NET qui prend en charge la création, l'édition et la manipulation de documents PDF de manière programmatique. IronPDF offre aux développeurs une solution complète pour produire des documents PDF dynamiques et esthétiques avec ses puissants outils de création de PDF, qui incluent la conversion HTML en PDF et les capacités d'édition de PDF.
Ce post vous emmènera faire un tour de l'intégration fluide de Scrapy Python avec IronPDF et vous montrera comment ce duo dynamique transforme la manière dont l'extraction web et la création de documents sont effectuées. Nous montrerons comment ces deux bibliothèques travaillent ensemble pour faciliter les tâches complexes et accélérer les flux de travail de développement, depuis l'extraction de données du web avec Scrapy jusqu'à la génération dynamique de rapports PDF avec IronPDF.
Venez explorer les possibilités de l'extraction web et de la génération de documents alors que nous utilisons IronPDF pour pleinement exploiter Scrapy.

Architecture Asynchrone
L'architecture asynchrone utilisée par Scrapy permet le traitement de plusieurs requêtes à la fois. Cela conduit à une efficacité accrue et à des vitesses d'extraction web plus rapides, en particulier lorsqu'on travaille avec des sites web complexes ou de grandes quantités de données.
Gestion de Crawl Solide
Scrapy possède des fonctionnalités fortes de gestion du processus de crawl, telles que le filtrage automatique des URL, la planification configurable des requêtes et la gestion intégrée des directives robots.txt. Le comportement de crawl peut être ajusté par les développeurs pour répondre à leurs propres besoins et garantir le respect des directives du site.
Sélecteurs pour XPath et CSS
Scrapy permet aux utilisateurs de naviguer et de choisir des éléments au sein des pages HTML à l'aide de sélecteurs pour XPath et CSS. Cette adaptabilité rend l'extraction de données plus précise et fiable en permettant aux développeurs de cibler précisément certains éléments ou motifs sur une page web.
Pipeline d'Objets
Les développeurs peuvent spécifier des composants réutilisables pour traiter les données extraites avant de les exporter ou de les stocker en utilisant le pipeline d'objets de Scrapy. En effectuant des opérations comme le nettoyage, la validation, la transformation et la dé-duplication, les développeurs peuvent garantir la précision et la cohérence des données qui ont été extraites.
Middleware Préinstallé
Un certain nombre de composants de middleware préinstallés dans Scrapy offrent des fonctionnalités telles que la gestion automatique des cookies, l'étranglement des requêtes, la rotation des user-agent et la rotation des proxy. Ces éléments de middleware sont simplement configurables et personnalisables pour améliorer l'efficacité de l'extraction et résoudre les problèmes typiques.
Architecture Extensible
En créant des middlewares, des extensions et des pipelines personnalisés, les développeurs peuvent personnaliser et étendre davantage les capacités de Scrapy grâce à son architecture modulaire et extensible. De par sa flexibilité, les développeurs peuvent facilement inclure Scrapy dans leurs processus actuels et le modifier pour répondre à leurs besoins d'extraction uniques.
Créer et Configurer Scrapy en Python
Installer Scrapy
Installez Scrapy en utilisant pip en exécutant la commande suivante :
pip install scrapypip install scrapyDéfinir une Araignée
Pour définir votre spider, créez un nouveau fichier Python (tel que example.py) dans le répertoire spiders/. Voici une illustration d'une araignée basique qui extrait d'une URL :
import scrapy
class QuotesSpider(scrapy.Spider):
# Name of the spider
name = 'quotes'
# Starting URL
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
# Iterate through each quote block in the response
for quote in response.css('div.quote'):
# Extract and yield quote details
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
# Identify and follow the next page link
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)import scrapy
class QuotesSpider(scrapy.Spider):
# Name of the spider
name = 'quotes'
# Starting URL
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
# Iterate through each quote block in the response
for quote in response.css('div.quote'):
# Extract and yield quote details
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
# Identify and follow the next page link
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)Configurer les Paramètres
Pour configurer les paramètres du projet Scrapy, tels que l'agent utilisateur, les délais de téléchargement et les pipelines, modifiez le fichier settings.py. Voici un exemple de modification de l'agent utilisateur et d'activation des pipelines :
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Set user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# Configure pipelines
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Set user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# Configure pipelines
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}Commencer
Pour commencer avec Scrapy et IronPDF, vous devez combiner les compétences solides d'extraction web de Scrapy avec les fonctionnalités dynamiques de production de PDF d'IronPDF. Je vous guiderai à travers les étapes de mise en place d'un projet Scrapy afin que vous puissiez extraire des données de sites web et utiliser IronPDF pour créer un document PDF contenant les données.
Qu'est-ce qu'IronPDF ?
IronPDF est une puissante bibliothèque .NET pour créer, éditer et modifier des documents PDF de manière programmatique en C#, VB.NET et autres langages .NET. Étant donné qu'il offre aux développeurs un large ensemble de fonctionnalités pour créer dynamiquement des PDF de haute qualité, c'est un choix populaire pour de nombreux programmes.
Caractéristiques de IronPDF
Génération de PDF : Avec IronPDF, les programmeurs peuvent créer de nouveaux documents PDF ou convertir des éléments HTML existants tels que des balises, du texte, des images et d'autres formats de fichiers en PDF. Cette fonctionnalité est très utile pour créer dynamiquement des rapports, des factures, des reçus et d'autres documents.
Conversion HTML en PDF : IronPDF permet aux développeurs de transformer facilement des documents HTML, y compris les styles de JavaScript et CSS, en fichiers PDF. Cela permet la création de PDF à partir de pages web, de contenu généré dynamiquement et de modèles HTML.
Modification et Édition de Documents PDF : IronPDF fournit un ensemble complet de fonctionnalités pour modifier et altérer des documents PDF existants. Les développeurs peuvent fusionner plusieurs fichiers PDF, les séparer en documents distincts, supprimer des pages, ajouter des signets, annotations et filigranes, entre autres fonctionnalités, pour personnaliser les PDF selon leurs besoins.
Comment installer IronPDF
Après vous être assuré que Python est installé sur votre ordinateur, utilisez pip pour installer IronPDF.
pip install ironpdf
Projet Scrapy avec IronPDF
Pour définir votre spider, créez un nouveau fichier Python (tel que example.py) dans le répertoire du spider de votre projet Scrapy (myproject/myproject/spiders). Un exemple de code d'une araignée basique qui extrait des citations d'une URL :
import scrapy
from IronPdf import *
class QuotesSpider(scrapy.Spider):
name = 'quotes'
# Web page link
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quotes = []
for quote in response.css('div.quote'):
title = quote.css('span.text::text').get()
content = quote.css('span small.author::text').get()
quotes.append((title, content)) # Append quote to list
# Generate PDF document using IronPDF
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(self.get_pdf_content(quotes))
pdf.SaveAs("quotes.pdf")
def get_pdf_content(self, quotes):
# Generate HTML content for PDF using extracted quotes
html_content = "<html><head><title>Quotes</title></head><body>"
for title, content in quotes:
html_content += f"<h2>{title}</h2><p>Author: {content}</p>"
html_content += "</body></html>"
return html_contentimport scrapy
from IronPdf import *
class QuotesSpider(scrapy.Spider):
name = 'quotes'
# Web page link
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quotes = []
for quote in response.css('div.quote'):
title = quote.css('span.text::text').get()
content = quote.css('span small.author::text').get()
quotes.append((title, content)) # Append quote to list
# Generate PDF document using IronPDF
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(self.get_pdf_content(quotes))
pdf.SaveAs("quotes.pdf")
def get_pdf_content(self, quotes):
# Generate HTML content for PDF using extracted quotes
html_content = "<html><head><title>Quotes</title></head><body>"
for title, content in quotes:
html_content += f"<h2>{title}</h2><p>Author: {content}</p>"
html_content += "</body></html>"
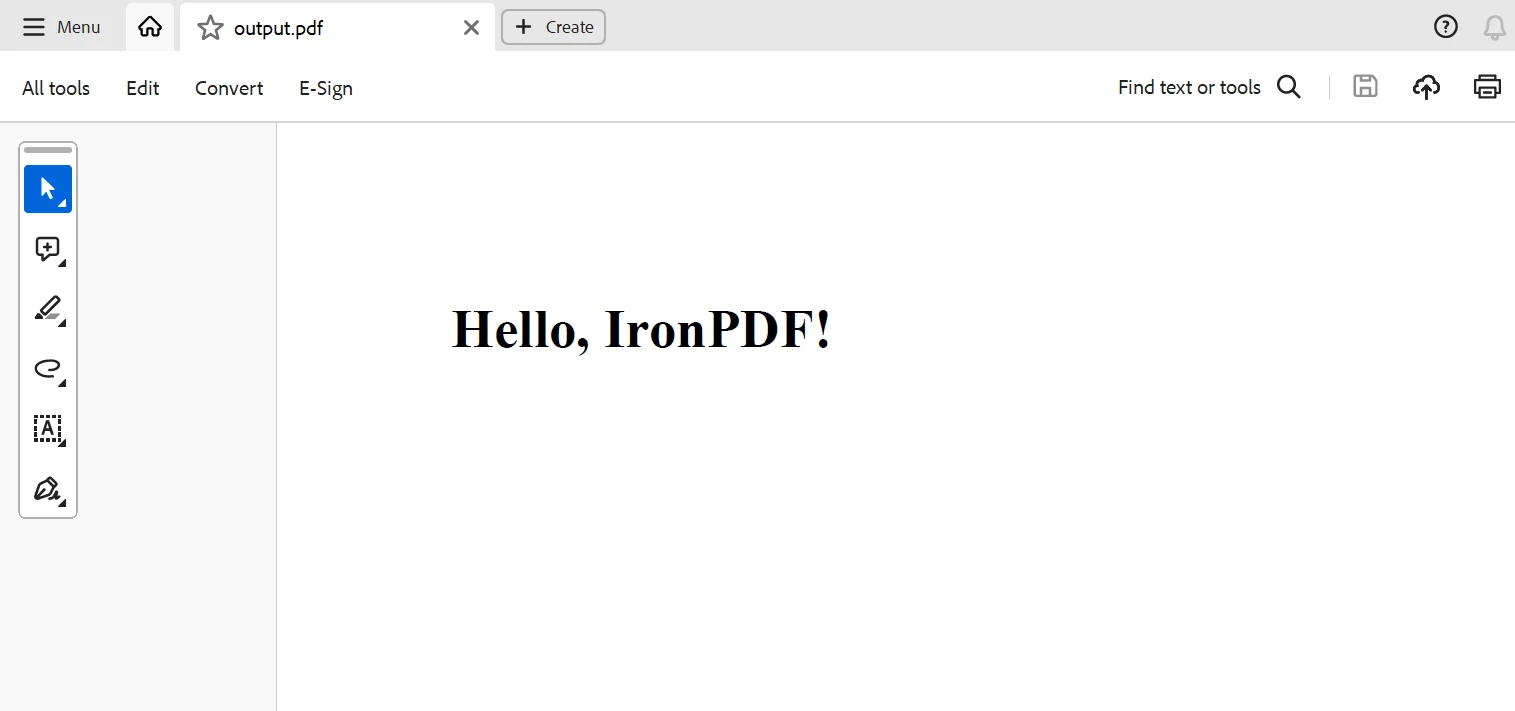
return html_contentDans l'exemple de code ci-dessus d'un projet Scrapy avec IronPDF, IronPDF est utilisé pour créer un document PDF en utilisant les données qui ont été extraites avec Scrapy.
Ici, la méthode parse du robot d'exploration récupère des citations de la page web et utilise la fonction get_pdf_content pour créer le contenu HTML du fichier PDF. Ce contenu HTML est ensuite converti en document PDF à l'aide IronPDF et enregistré sous le nom quotes.pdf.
Conclusion
Pour résumer, la combinaison de Scrapy et d'IronPDF offre aux développeurs une solution puissante pour automatiser les activités d'extraction web et produire des documents PDF à la volée. Les fonctionnalités flexibles de production de PDF d'IronPDF, combinées avec les capacités puissantes de crawling et d'extraction web de Scrapy, offrent un processus sans faille pour collecter des données structurées de n'importe quelle page web et transformer les données extraites en rapports, factures ou documents PDF de qualité professionnelle.
Grâce à l'utilisation de Scrapy Spider Python, les développeurs peuvent naviguer efficacement dans les complexités d'internet, récupérer des informations de nombreuses sources et les organiser de manière systématique. Le cadre flexible de Scrapy, son architecture asynchrone et son support pour les sélecteurs XPath et CSS lui confèrent la flexibilité et l'évolutivité requises pour gérer une variété d'activités d'extraction web.
Une licence à vie est incluse avec IronPDF, qui est à prix raisonnable lorsqu'elle est achetée dans un pack. Ce pack offre un excellent rapport qualité-prix, pour seulement $999 (un achat unique pour plusieurs systèmes). Ceux qui ont des licences ont accès en ligne au support technique 24h/24 et 7j/7. Pour plus de détails sur les frais, veuillez consulter le site web. Visitez cette page pour en savoir plus sur les produits d'Iron Software.
Questions Fréquemment Posées
Comment puis-je intégrer Scrapy avec un outil de génération de PDF ?
Vous pouvez intégrer Scrapy avec un outil de génération de PDF comme IronPDF en utilisant d'abord Scrapy pour extraire des données structurées de sites web, puis en employant IronPDF pour convertir ces données en documents PDF dynamiques.
Quelle est la meilleure façon d'extraire des données et de les convertir en PDF ?
La meilleure façon d'extraire des données et de les convertir en PDF est d'utiliser Scrapy pour extraire efficacement les données et IronPDF pour générer un PDF de haute qualité à partir du contenu extrait.
Comment puis-je convertir HTML en PDF en Python ?
Bien qu'IronPDF soit une bibliothèque .NET, vous pouvez l'utiliser avec Python grâce à des solutions d'interopérabilité comme Python.NET pour convertir HTML en PDF en utilisant les méthodes de conversion d'IronPDF.
Quels sont les avantages d'utiliser Scrapy pour l'extraction de données sur le web ?
Scrapy offre des avantages tels que le traitement asynchrone, des sélecteurs XPath et CSS robustes, et un middleware personnalisable, ce qui facilite l'extraction de données à partir de sites web complexes.
Puis-je automatiser la création de PDF à partir de données web ?
Oui, vous pouvez automatiser la création de PDF à partir de données web en intégrant Scrapy pour l'extraction de données et IronPDF pour générer des PDF, permettant un flux de travail transparent de l'extraction à la création de documents.
Quel est le rôle du middleware dans Scrapy ?
Le middleware dans Scrapy vous permet de contrôler et de personnaliser le traitement des requêtes et des réponses, permettant des fonctionnalités comme le filtrage automatique des URL et la rotation de l'agent utilisateur pour améliorer l'efficacité de l'extraction.
Comment définissez-vous un spider dans Scrapy ?
Pour définir un spider dans Scrapy, créez un nouveau fichier Python dans le répertoire spiders de votre projet et implémentez une classe qui étend scrapy.Spider avec des méthodes comme parse pour gérer l'extraction de données.
Qu'est-ce qui fait d'IronPDF un choix approprié pour la génération de PDF ?
IronPDF est un choix approprié pour la génération de PDF car il offre des fonctionnalités complètes pour la conversion de HTML en PDF, la création dynamique de PDF, l'édition et la manipulation, le rendant polyvalent pour divers besoins en génération de documents.
Comment puis-je améliorer l'extraction de données web et la création de PDF ?
Améliorez l'extraction de données web et la création de PDF en utilisant Scrapy pour une extraction efficace des données et IronPDF pour convertir les données extraites en documents PDF formatés professionnellement.