
如何逐行从 PDF 提取文本
本指南将展示如何使用 IronPDF 在 Python 中按顺序从 PDF 文档中提取文本。 它将涵盖从设置 Python 环境到执行第一个用于提取 PDF 文本的 Python 程序的所有内容。
如何逐行从 PDF 中提取文本
- 使用 Python 下载并安装 PDF 库,从 PDF 文件行中提取文本。
- 在您喜欢的 IDE 中创建一个 Python 项目。
- 加载要检索文本内容的 PDF 文件。
- 遍历 PDF 文件,并使用内置库的功能按顺序提取文本。
- 将提取的文本保存到文件中。
IronPDF PDF Python库
IronPDF是一个方便的工具,它允许你在 Python 中处理 PDF 文件。 您可以把它想象成一个得力的助手,让您能够轻松地阅读、创建和编辑 PDF 文件。 无论您是想从 PDF 文档中提取内容、添加新信息,还是将网页转换为 PDF 格式,IronPDF 都能提供全面的解决方案。 这是一个付费软件,但他们提供试用版供您在购买前体验。
在开始编写脚本之前,设置 Python 环境至关重要。 本分步指南将帮助您配置环境,在 Visual Studio Code 中创建一个新的 Python 项目,并设置 IronPDF 库环境配置。
下载并安装 Python:如果您还没有安装 Python,请从Python 官方网站下载最新版本。 请按照您操作系统对应的安装说明进行操作。
检查 Python 安装:打开终端或命令提示符,输入python --version 。 该命令应打印已安装的 Python 版本,以确认安装成功。
更新 pip: pip是 Python 包安装程序。 运行pip install --upgrade pip 命令确保它是最新版本。
在 Visual Studio Code 中创建新的 Python 项目
下载 Visual Studio Code:如果您还没有安装,请从官方网站下载。
安装 Python 扩展:打开 Visual Studio Code 并前往扩展市场。 搜索并安装微软提供的Python扩展程序。
创建新文件夹:创建一个新文件夹,用于存放您的 Python 项目。 给它起个相关的名字,比如PDF_Text_Extractor 。
在 VS Code 中打开文件夹:将文件夹拖入 Visual Studio Code 中,或使用"文件">"打开文件夹"菜单选项打开文件夹。
创建 Python 文件:在 VS Code 资源管理器面板中右键单击,然后选择"新建文件" 。 将文件命名为main.py或类似名称。 这个文件将存放你的Python程序。
 在 Visual Studio Code 中创建一个新的 Python 文件
在 Visual Studio Code 中创建一个新的 Python 文件
IronPDF库的要求和安装
IronPDF 对于从 PDF 文件中检索文本内容至关重要。 以下是安装方法:
在 VS Code 中打开终端:您可以通过转到"终端">"新建终端"在 VS Code 中打开终端。
安装IronPDF:在终端中执行以下命令安装最新版本的IronPDF:
pip install ironpdf
此过程会检索并安装 IronPDF 库以及任何必需的模块。
 安装IronPDF包
安装IronPDF包
就是这样! 您现在已经成功设置了 Python 环境,在 Visual Studio Code 中创建了一个新项目,并安装了 IronPDF 库。
逐行提取 PDF 中的文本
应用许可证密钥
在继续操作之前,请确保您已应用 IronPDF 许可证密钥。
from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"用您的实际IronPDF许可证密钥替换YOUR-LICENSE-KEY-HERE。 此许可证允许您解锁项目所需的所有库功能。
加载 PDF 文件格式
你需要将一个现有的 PDF 文件加载到你的 Python 程序中。 您可以使用IronPDF中的PdfDocument.FromFile方法来实现这一点。
pdfFileObj = PdfDocument.FromFile("content.pdf")pdfFileObj = PdfDocument.FromFile("content.pdf")"content.pdf"指的是您想要阅读的PDF文件。 此加载的PDF文件存储在pdfFileObj使用。
从整个 PDF 文档中提取文本
如果您想一次提取所有PDF文件中的文本数据,可以使用ExtractAllText方法。
all_text = pdfFileObj.ExtractAllText()all_text = pdfFileObj.ExtractAllText()此处使用ExtractAllText方法进行演示。 此方法从PDF文件中提取所有文本并将其存储在名为all_text的变量中。
从特定 PDF 页面中提取文本
IronPDF可以使用ExtractTextFromPage方法从特定页面提取文本。 当您只需要某些页面上的文本时,此方法非常有用。
page_2_text = pdfFileObj.ExtractTextFromPage(1)page_2_text = pdfFileObj.ExtractTextFromPage(1)在这里,我们从第二页提取文本,对应的索引为 1。
初始化文本文件以写入提取的文本
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:with open("extracted_text.txt", "w", encoding='utf-8') as text_file:打开名为"extracted_text.txt"的文件,保存文本数据。 使用Python的内置encoding='utf-8'处理Unicode字符。
遍历每一页,逐行提取文本
for i in range(0, pdfFileObj.get_Pages().Count):for i in range(0, pdfFileObj.get_Pages().Count):上述代码使用IronPDF的get_Pages().Count循环遍历PDF文件中的每一页,以获取总页数。
提取文本并将其分割成行
page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')对于每一页,使用split方法将其分行。 这样就得到了一个可以循环遍历的行列表。
将提取的行写入文本文件
for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')这里,代码遍历行列表中的每一行,将其打印到控制台,并通过在每一行后添加换行符( \n )将其写入文件,以正确格式化此文本。
完整代码
以下是完整的实施方案:
from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')输出
在 Visual Studio Code 终端中输入以下命令来运行 Python 文件:
python main.pypython main.py结果将显示在终端上:
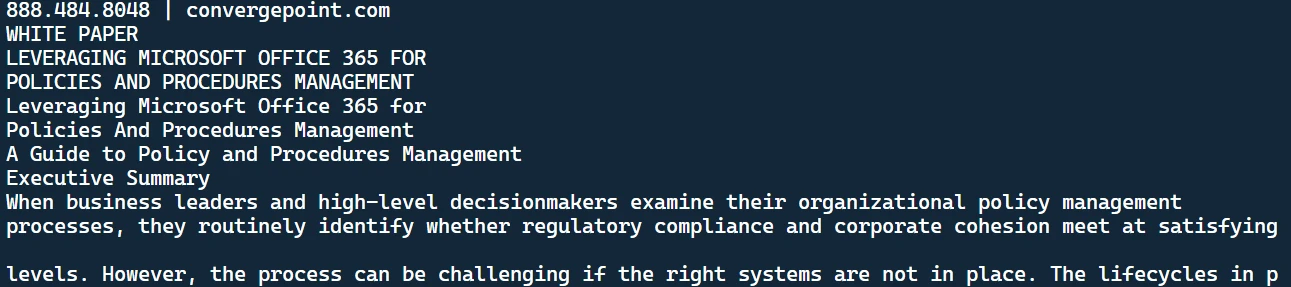 提取的文本
提取的文本
这是从 PDF 文件中提取的文本。您还会注意到目录中创建了一个文本文件。
 提取的文本存储在TXT文件中
提取的文本存储在TXT文件中
在这个文本文件中,您将找到已检索到的文本格式,并按顺序呈现。
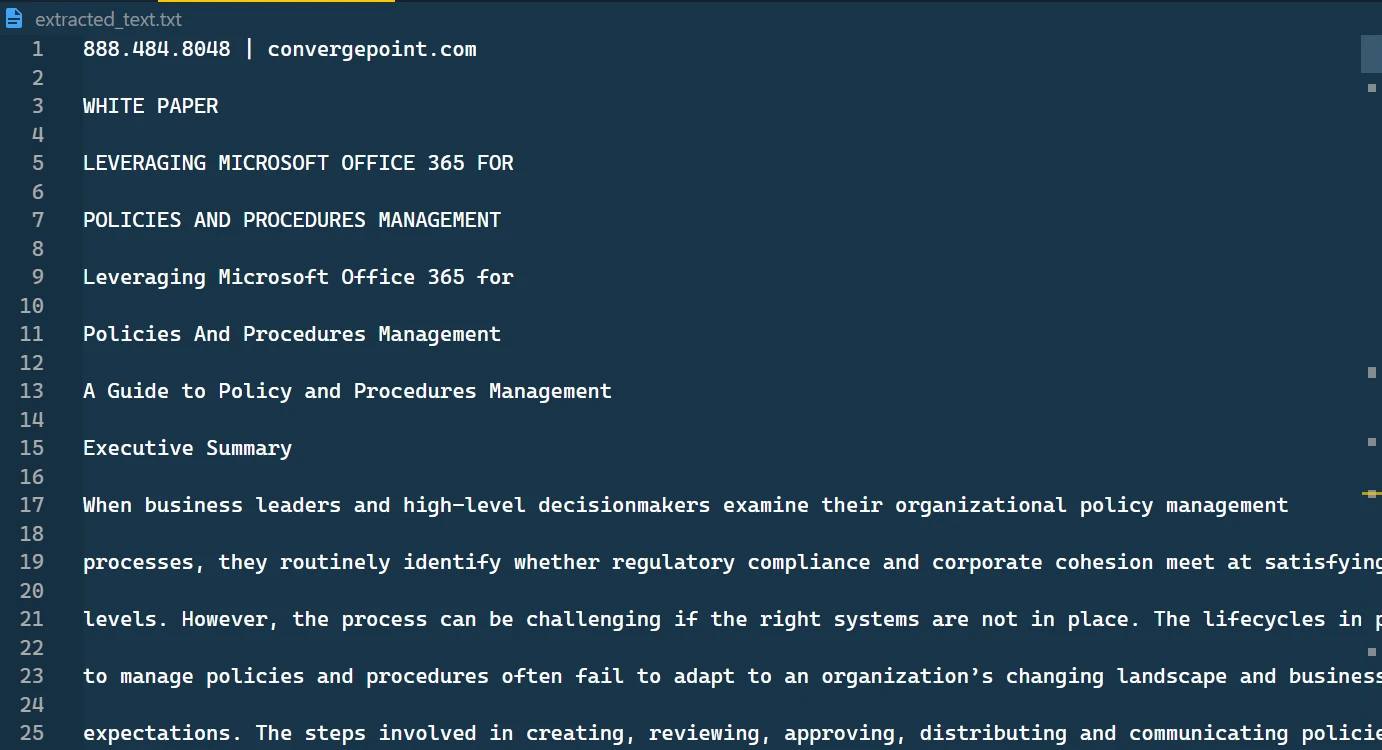 提取的文本文件内容
提取的文本文件内容
结论
总之,使用 IronPDF 和 Python 从 PDF 文件中提取文本是一种强大而简便的方法,无论是从整个文档、特定页面还是逐行提取文本。此外,将提取的文本保存到文本文件中,便于您高效地管理和利用这些数据进行后续处理。 IronPDF 被证明是处理 PDF 的非常宝贵的工具,它提供的功能远不止文本提取。 您还可以使用IronPDF在Python中将PDF转换为文本。
此外,IronPDF 工具包还可以帮助完成以下任务:创建交互式 PDF、填写和提交交互式表单、合并和拆分PDF 文件、提取文本和图像、在 PDF 文件中搜索文本、将 PDF 栅格化为图像、更改字体大小、边框和背景颜色以及转换 PDF 文件。
IronPDF 不是一个开源的 Python 库。 如果您正在考虑在项目中使用IronPDF,该软件包的许可证起价为$799。 但是,如果您需要了解投资详情,IronPDF 提供免费试用版,以便您全面了解其功能。
常见问题解答
如何使用Python从PDF中提取文本?
您可以使用IronPDF在Python中从PDF文件中提取文本。这涉及使用PdfDocument.FromFile方法加载PDF,并通过页面迭代逐行提取文本。
开始在Python中从PDF中提取文本需要什么?
要在Python中从PDF中提取文本,您需要安装Python以及可以通过pip安装的IronPDF库。建议使用像Visual Studio Code这样的IDE来编写和执行您的脚本。
IronPDF可以从PDF的特定页面提取文本吗?
是的,IronPDF允许您使用ExtractTextFromPage方法通过指定页面索引从PDF的特定页面提取文本。
如何在Python中将提取的文本保存到文件中?
使用IronPDF提取文本后,您可以通过使用Python的文件处理方法将提取的文本行保存到文本文件中。
除了文本提取外,IronPDF还提供哪些附加功能?
IronPDF提供了广泛的功能,包括创建、编辑和转换PDF,合并和拆分PDF文档,提取图像,以及将PDF转换为其他文件格式。
如何在我的Python项目中对IronPDF进行授权?
要对IronPDF进行授权,在Python脚本中使用License.LicenseKey属性设置您的许可证密钥,以解锁库的全部功能。
是否可以在购买之前试用IronPDF?
是的,IronPDF提供了一个试用版本,可以在决定购买完整许可证之前评估其功能。
在PDF文本提取过程中遇到问题时该怎么办?
确保 IronPDF 已正确安装和授权,并且您的 Python 环境已正确设置。请查阅文档或支持资源以解决常见问题。
我可以使用 IronPDF 将 PDF 转换为图像吗?
是的,IronPDF提供了将PDF光栅化为图像的功能,允许您将整个文档或特定页面转换为图像文件。
如何执行用于PDF文本提取的Python脚本?
编写完脚本后,可以在IDE的终端中运行python main.py执行它,其中main.py是您的脚本文件名。
















